Method and device for visualizing text set similarity
A similarity and text technology, which is applied in the field of visualization methods and devices for the similarity of text sets, and can solve problems such as the inability to express the relationship between text sets
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
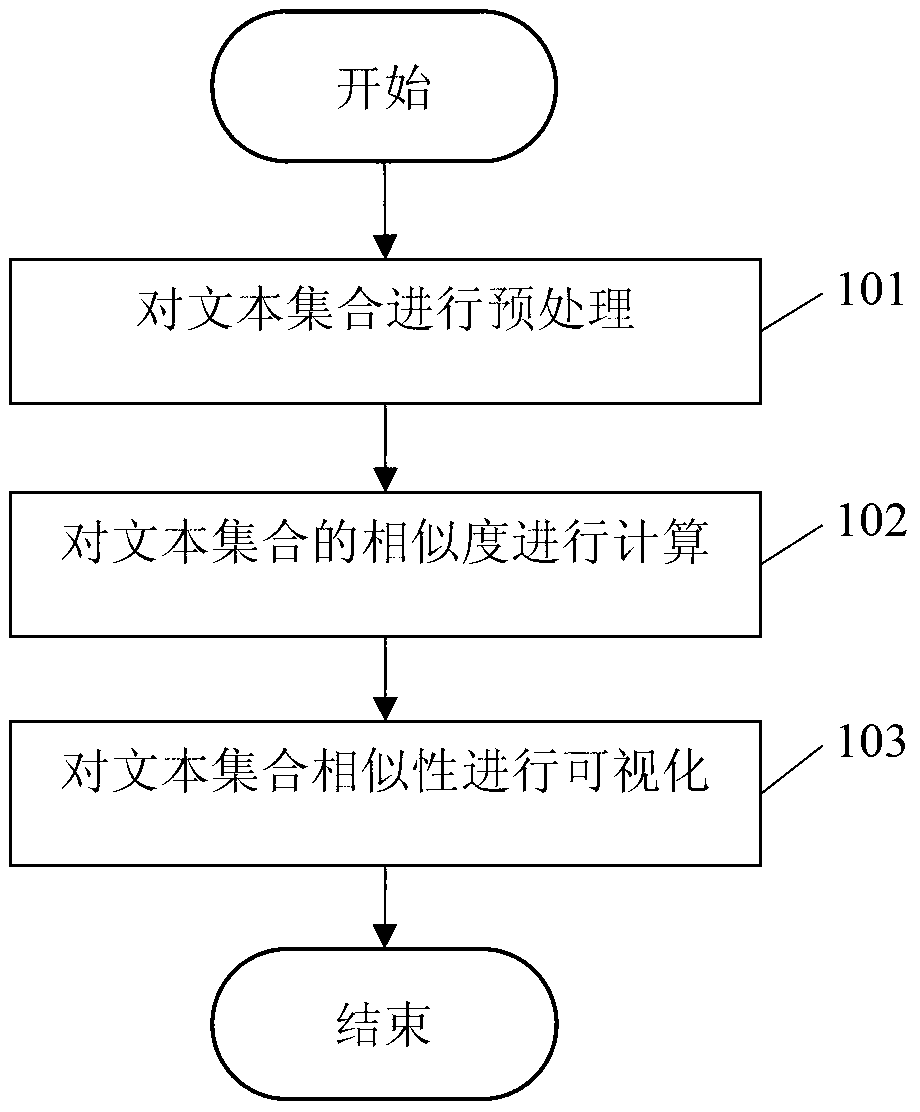
[0022] see figure 1 , this embodiment provides a method for visualizing the similarity of text sets, and the method flow is as follows:
[0023] 101: Preprocessing the text collection;
[0024] 102: Calculate the similarity of the text collection;
[0025] 103: Visualize the similarity of text collections.
[0026] The method provided in this embodiment measures the similarity of text collections by establishing a text collection similarity calculation model, and displays the similarity results in a graphical manner, so that users can intuitively and quickly understand the content and similarity of text collections beneficial effects of information.
Embodiment 2
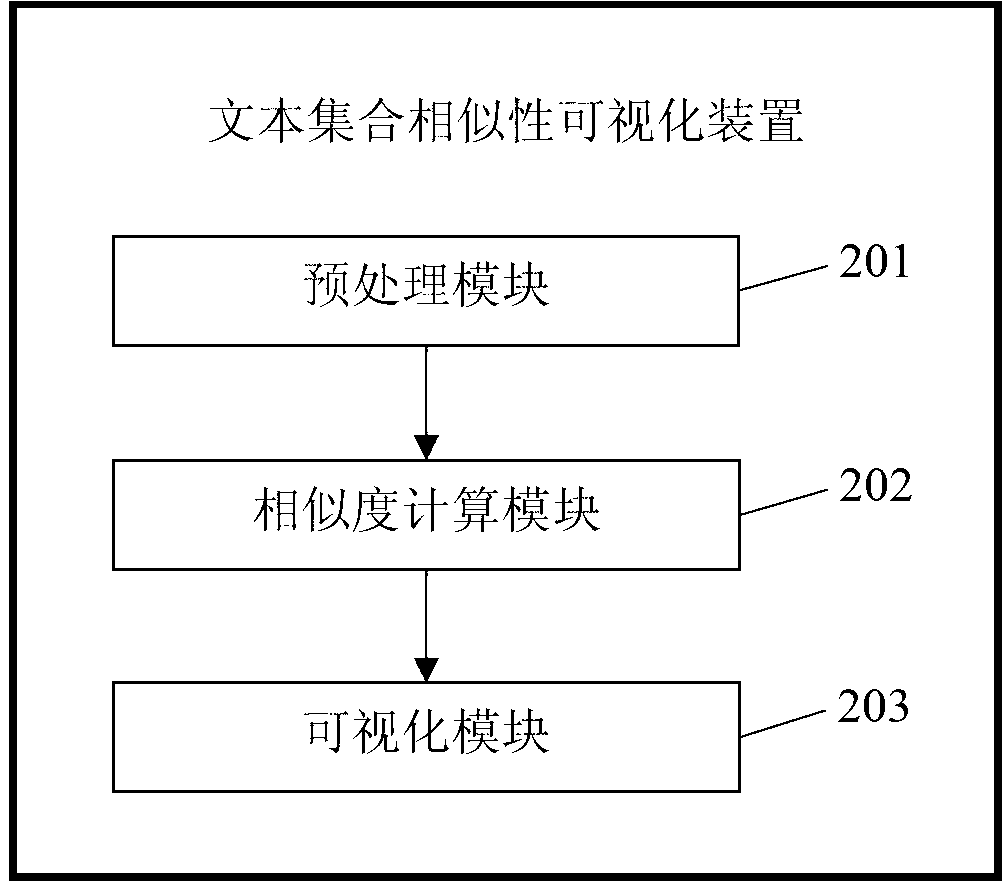
[0028] see figure 2 , this implementation provides a visualization device for the similarity of text sets, the device includes:
[0029] A preprocessing module 201, configured to preprocess the text set to be subjected to similarity calculation;
[0030] A similarity calculation module 202, configured to calculate the similarity of the preprocessed text set;
[0031] The visualization module 203 is configured to visualize the similarity of text collections.
[0032] Specifically, in the above-mentioned preprocessing module 201, the text collection is divided into words, and the text feature words are obtained after removing the stop words, and the weight of the words is calculated; wherein, the stop words refer to such as "of", "and" and "in " and other prepositions, modal particles and very commonly used words.
[0033] In the similarity calculation module 202, the similarity of the text set is calculated through the feature words of the text set and their weights.
[00...
Embodiment 3
[0041] see image 3 , this implementation provides a visualization device for the similarity of text sets, the device includes:
[0042] The preprocessing module 301 is used to preprocess the raw data to be visualized to obtain the feature words and weights of the text collection;
[0043] A similarity calculation module 302, configured to perform similarity calculation on the preprocessed text set;
[0044] The visualization module 303 is configured to use the above results to visualize the similarity of text collections.
[0045] Further, the preprocessing module 301 includes:
[0046] The word segmentation unit 301a is used to segment the text collection and remove stop words to obtain independent feature phrases;
[0047] The word weight calculation unit 301b is used to calculate the weight of the feature words of the text set.
[0048] Wherein, in the word segmentation unit 301a, stop words refer to some prepositions, modal particles or very commonly used words such a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com