Class center compression transformation-based text clustering method in search engine
A text clustering and compression transformation technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as inaccurate clustering results and the impact of document similarity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0053] The present invention will be further described below in conjunction with the accompanying drawings and embodiments.
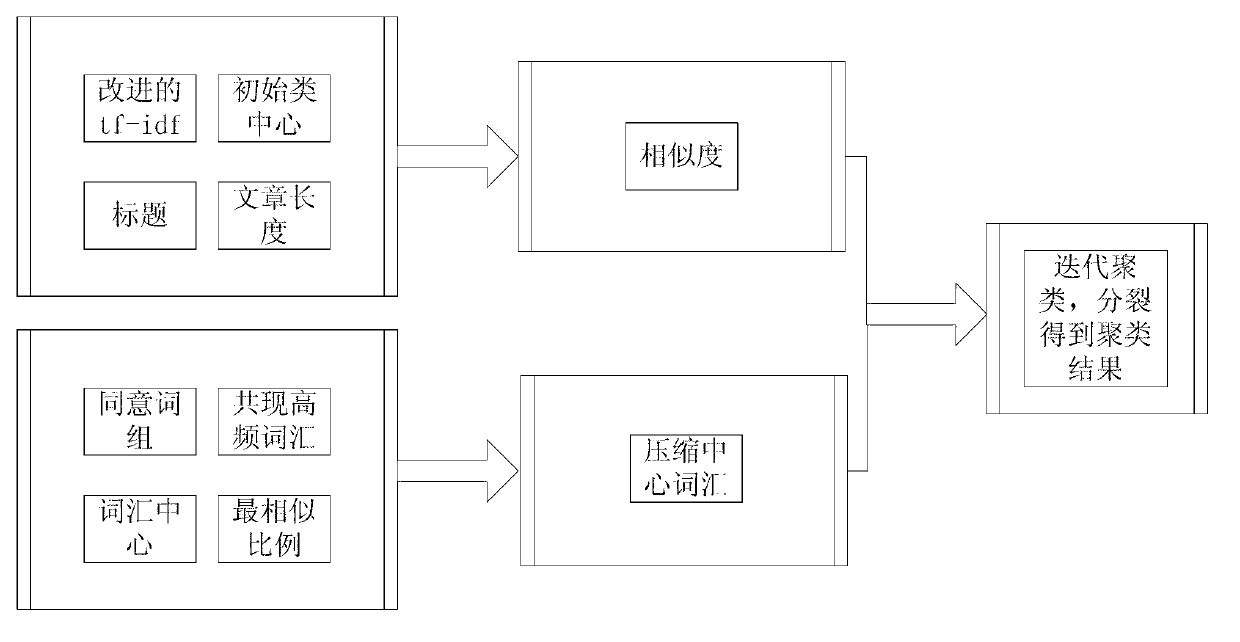
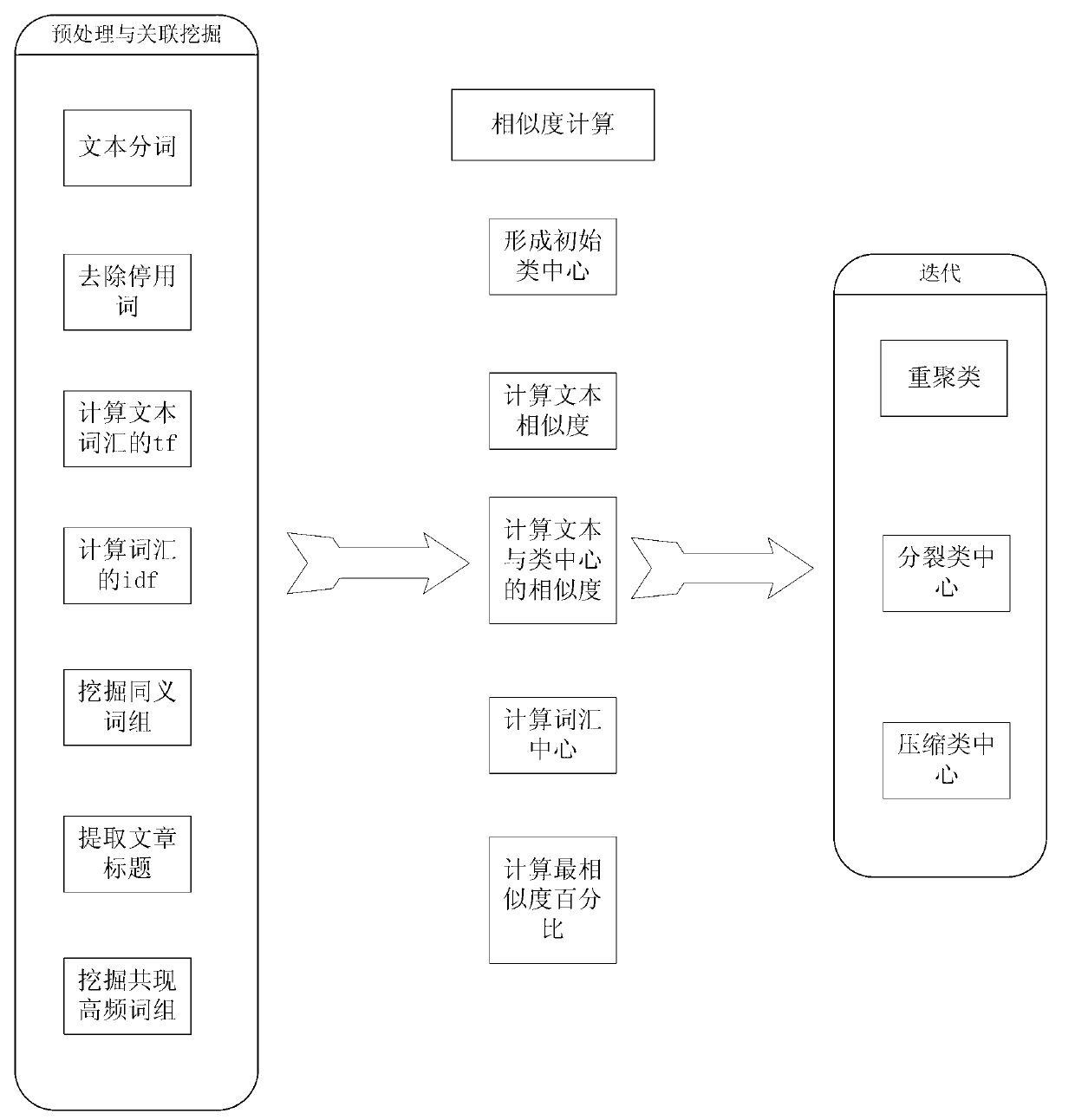
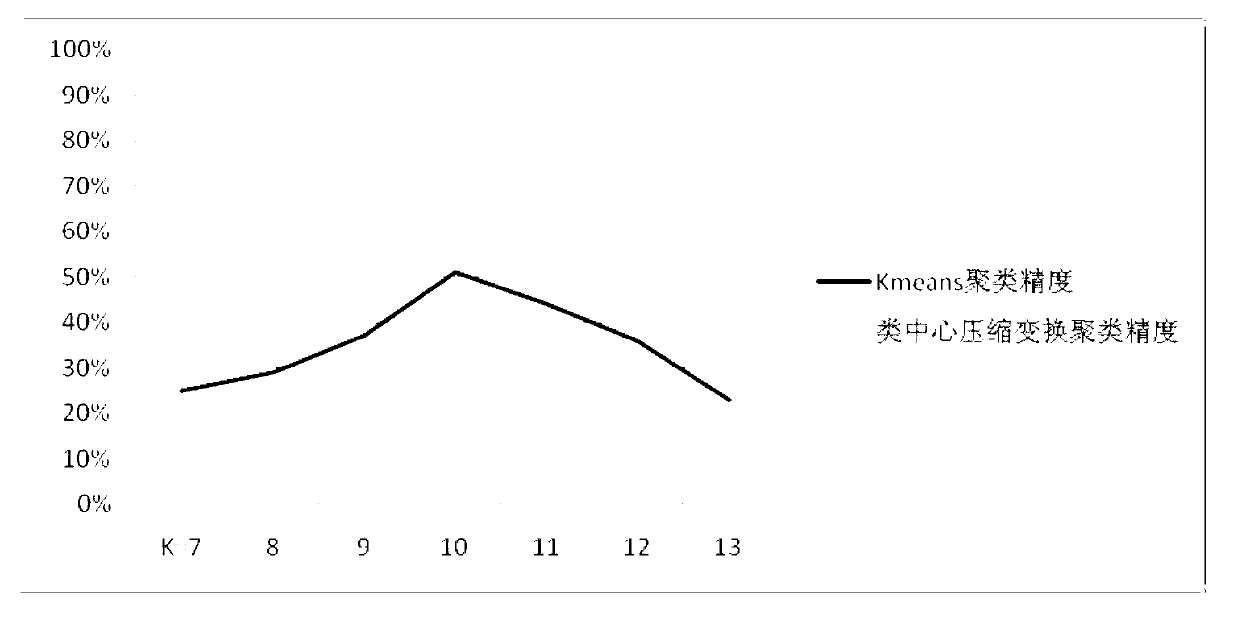
[0054] The text clustering method based on the class center compression transformation of the present invention fully excavates the potential semantic association between text words, calculates the word center, compresses the class center, and improves the accuracy of text clustering. Calculate the similarity between the class center and the text, iteratively split and merge, and reorganize the class center until a certain standard is met. Said mining the potential semantic association between text words, using the improved tf-idf to calculate the similarity between texts, as an important index to measure the association degree between text words. At the same time, the title of each document is extracted and word-segmented, and the similarity of the title vocabulary is weighted.
[0055] tf new =log(tf)+1
[0056] Where fileNum is the total number ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com