Method and device for extracting webpage title and information processing system
A technology of web page title and extraction method, which is applied in the field of information processing, can solve the problems of low accuracy rate and recall rate of web page search, and achieve the effect of improving accuracy rate and recall rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
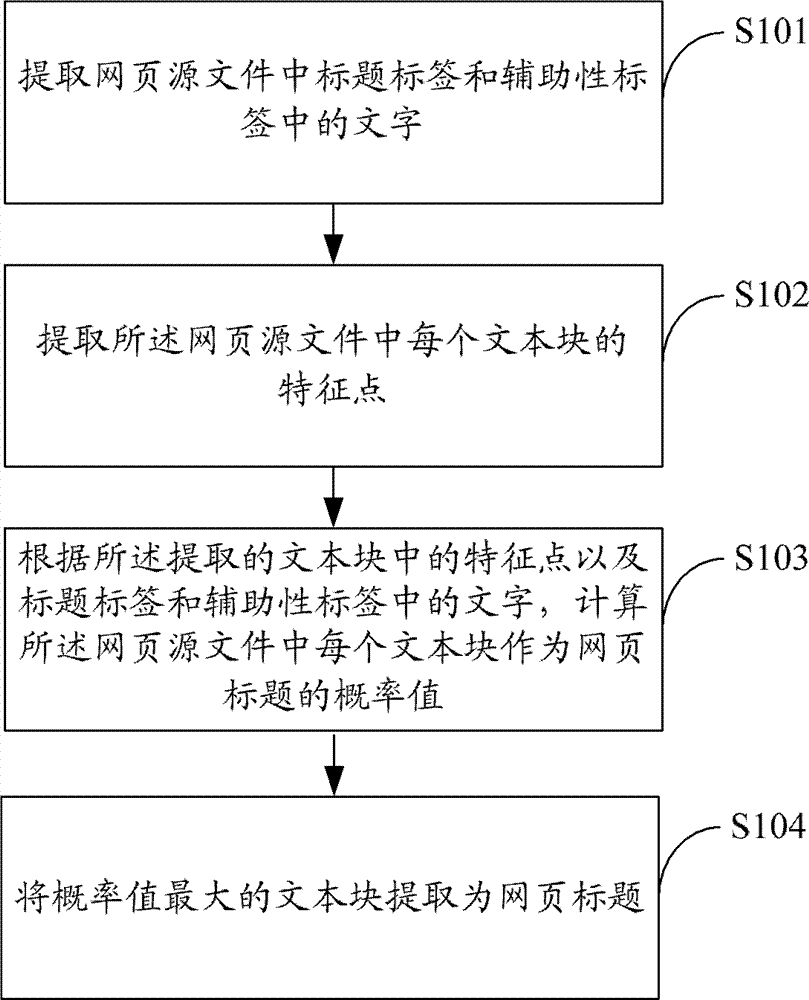
[0025] figure 1 The implementation flow of the method for extracting the title of a web page provided by Embodiment 1 of the present invention is shown, and the process of the method is described in detail as follows:
[0026] In step S101, the text in the title tag and the auxiliary tag in the source file of the web page is extracted.
[0027] In this embodiment, a text parser is used to parse title (title) tags and auxiliary (meta) tags in the webpage source file, and extract text in the title tags and auxiliary tags. For example: in described web page source file is HTML (HyperText Mark-up Language, hypertext markup language) source file, by HTML text parser, title tag economic center The words "economic center" and "politics, economy, technology, culture" in the meta tag are analyzed.
[0028] As an embodiment of the present invention, the method can also use a Document Object Model (Document Object Model, DOM) tree to replace the source file of the webpage, and subseq...
Embodiment 2
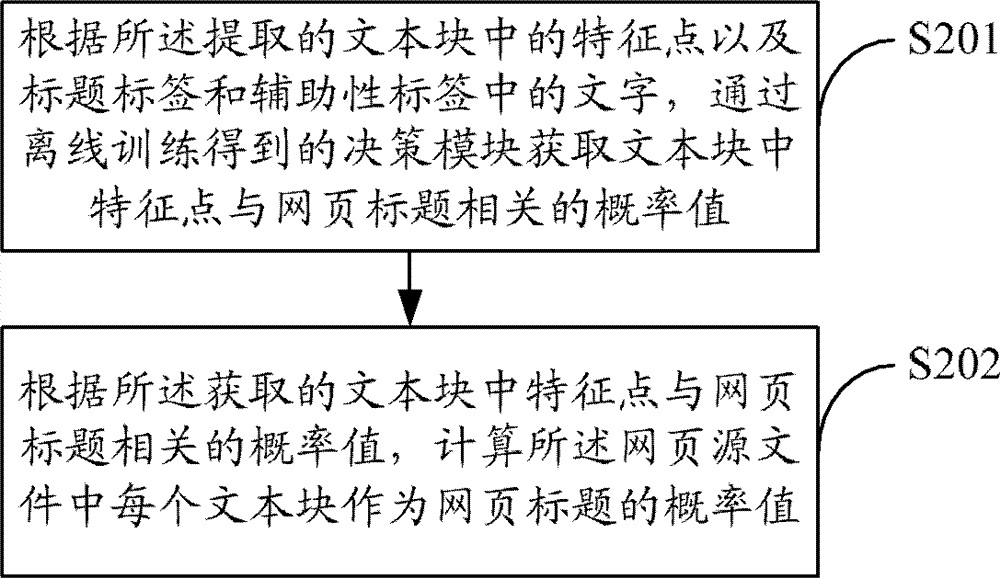
[0047] figure 2 It is a specific process for calculating the probability value of each text block in the web page source file as a web page title according to the feature points of the extracted text block and the text in the title tag and auxiliary tags provided by Embodiment 2 of the present invention:
[0048]In step S201, according to the extracted feature points of the text block and the words in the title tag and auxiliary tags, the probability value related to the feature point of the text block and the title of the webpage is obtained through a decision model obtained through offline training.
[0049] In this embodiment, the feature points are extracted from the collected webpage samples by means of offline training, and the feature points are stored in the feature point database, and a decision model is trained according to the feature points in the database, and then according to The decision-making model determines the probability value of each feature point relat...
specific example
[0054] In order to better illustrate the web page title extraction method, image 3 A specific example of the web page title extraction method provided by Embodiment 3 of the present invention is shown, and the steps of the specific example are as follows:
[0055] 1. Enter the URL (Universal Resource Locator, webpage address): http: / / news.qq.com / a / 20101120 / 000780.htm to obtain the HTML source file of the webpage;
[0056] 2. Extract the text in the title tag in the source file: "The State Council issued 16 measures to stabilize the overall level of consumer prices News Tencent Network";
[0057] 3. Extract the text in the meta tag in the source file: "The State Council issued 16 measures to stabilize the overall level of consumer prices and prices";
[0058] 4. Divide the continuous text nodes in the source file into multiple independent text blocks, for example: "Tencent.com Homepage", "Website Navigation", "Mailbox", "The State Council issued 16 measures to stabilize the o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com