Low-power consumption high-performance repeating data deleting system
A high-performance technology for data deduplication, applied to redundancy in computing for data error detection, transmission systems, electrical digital data processing, etc. Low cost, low implementation cost, good versatility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image


Examples
Embodiment 1
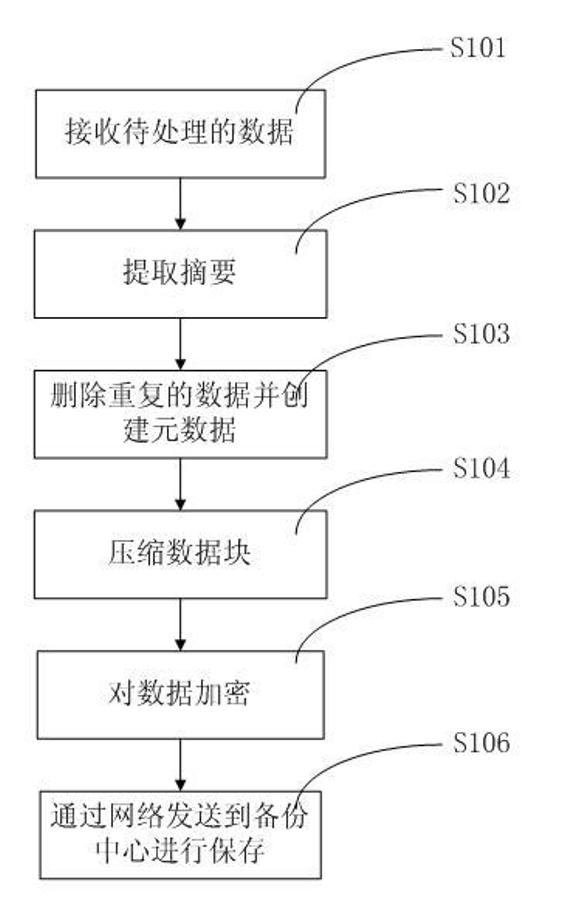
[0061] refer to image 3 , shows the data batch collection algorithm of the present invention. The specific principle and operation steps are as follows:
[0062] Step S301, generating corresponding metadata information for the data block received from the network.
[0063] In step S302, the metadata generated in step S301 is mounted on the corresponding global metadata linked list for use by subsequent threads.
[0064] In step S303, the size of the data block is obtained and stored in a corresponding location of the global data buffer.
[0065] Step S304, putting the data block into the corresponding position of the global data buffer.
[0066] The batch encapsulation of data streams is mainly data preprocessing for changing the traditional serial data deduplication process into a pipeline mechanism. At the same time, encapsulating data streams in batches and storing data and metadata separately is also a preparation for subsequent GPU parallel computing.
Embodiment 2
[0068] refer to Figure 4 , showing the flow of the GPU compression algorithm of the present invention. The specific principle and operation steps are as follows:
[0069] Step S401, obtain the ID of the current process.
[0070] Step S402, because the data is pre-organized during the accumulation process. Therefore, the position of the data to be processed by the thread in the total data block can be obtained according to the previous thread ID.
[0071] Step S403, obtain the size of the data block to be processed by the thread from the starting position of the data block, and store it in the pointer position obtained in the previous step.
[0072] Step S404, compress the data block using a certain compression algorithm.
Embodiment 3
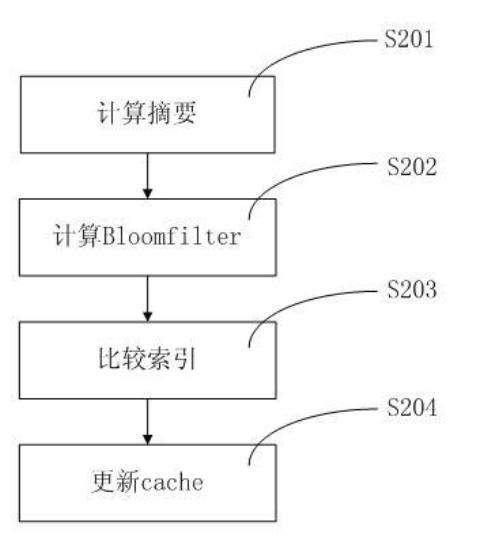
[0074] refer to Figure 5 , shows the process of using GPU to do Bloomfilter in the present invention. The specific principle and operation steps are as follows:
[0075] Step S501, acquiring the ID of the current thread.
[0076] In step S502, the data to be processed by the thread is obtained. The data is pre-organized, so the first address of the data in the total data block can be obtained according to the current thread ID. The data length is fixed (160 bits).
[0077] Step S503, using a certain algorithm to perform Bloomfilter calculation on the block of data.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com