


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Streaming speech recognition system and method based on non-autoregression model
A speech recognition and regression model technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of low speech recognition decoding efficiency and poor real-time speech recognition, and achieve the effect of avoiding losses and improving the speed of streaming reasoning.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
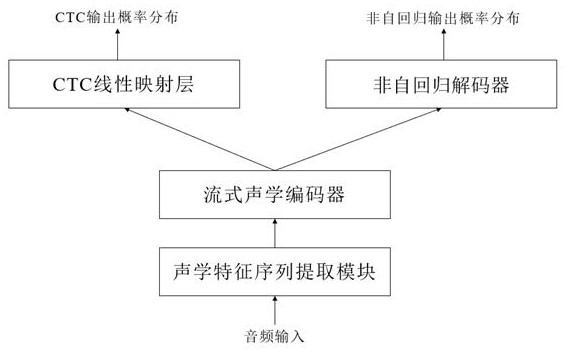
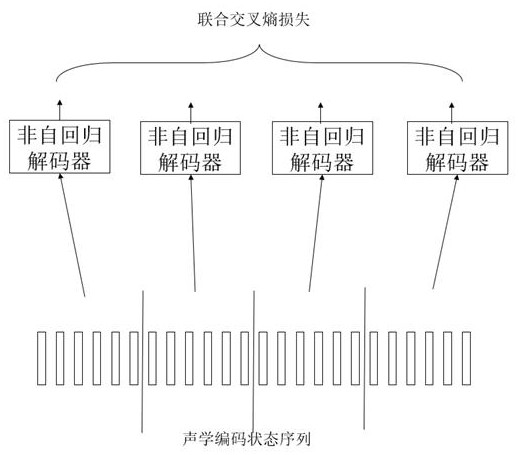
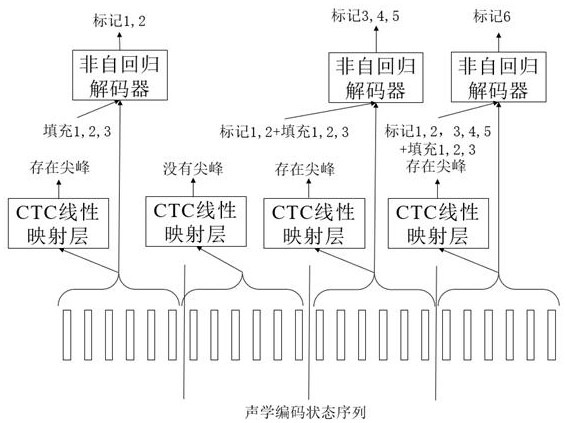
[0060] A non-autoregressive model-based streaming speech recognition system training method, which includes an acoustic feature sequence extraction module, a streaming acoustic encoder, a CTC linear mapping layer, and a non-autoregressive decoder, such as figure 1 As shown, the training process includes the following steps:
[0061] Step 1. Obtain speech training data and corresponding text annotation training data, and extract a series of features of the speech training data to form a speech feature sequence;
[0062] The goal of speech recognition is to convert continuous speech signals into text sequences. During the recognition process, the waveform signals in the time domain are windowed and framed and then discrete Fourier transform is performed to extract coefficients of specific frequency components to form feature vectors. A series of feature vectors constitute a speech feature sequence, and the speech features are Mel frequency cepstral coefficients (MFCC) or Mel fil...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com