Security patrol resource deployment method and system
A resource and security technology, applied in the field of security patrol resource deployment methods and systems, can solve problems such as the inability to reasonably deploy security resources, and achieve the effects of improving utilization and patrol efficiency, preventing dangerous activities, and improving efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

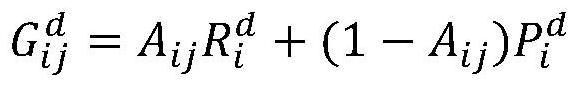
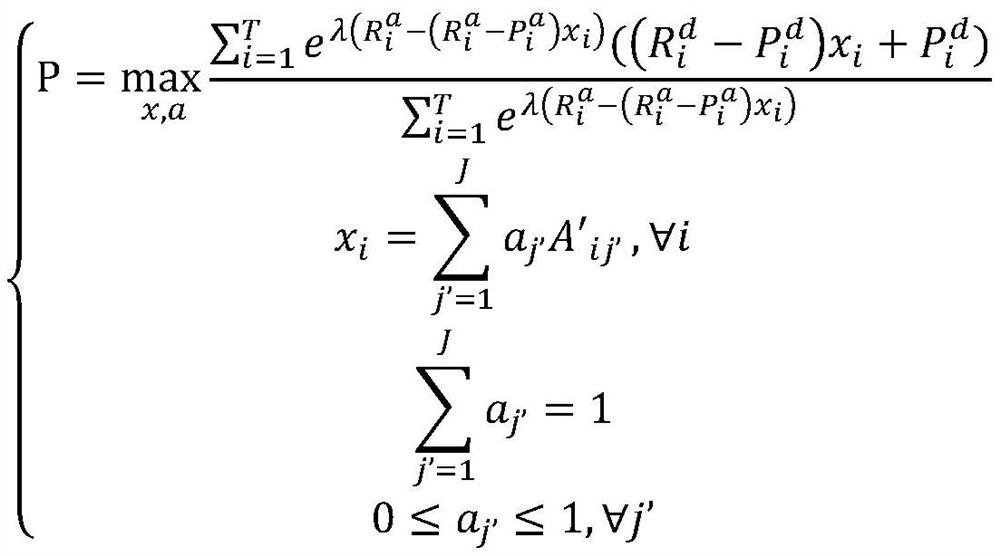
Examples
specific Embodiment approach 1
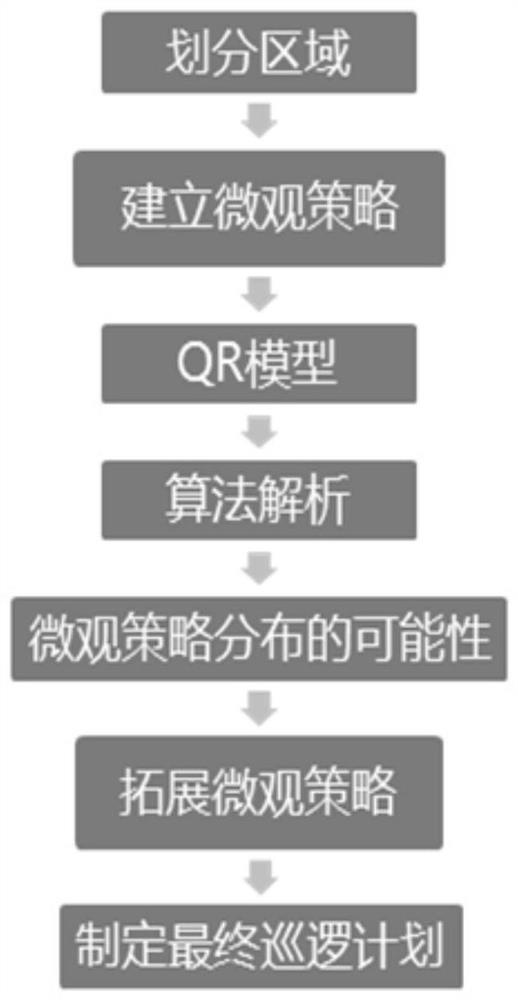
[0045] Specific implementation mode 1. Combination figure 1 This embodiment will be described. A security patrol resource deployment method described in this embodiment, the method specifically includes the following steps:
[0046] Step 1. Randomly generate all possible patrol schedules for the entire patrol area, and use all the randomly generated patrol schedules to create an area graph G=(V, E), where each sub-patrol area serves as the vertex V of the area graph and is at the same The connection line between the sub-patrol areas patrolled at adjacent moments in the patrol schedule is edge E; the sub-patrol area is obtained after dividing the entire patrol area, and refers to the area where a single target to be protected is located ;
[0047] The sub-patrol area in the patrol schedule is combined with the corresponding defense activities to obtain the patrol plan;
[0048] The patrol schedule refers to patrolling a certain sub-patrol area at a certain time, and then the...
specific Embodiment approach 2
[0052] Specific embodiment two: the difference between this embodiment and specific embodiment one is: the defender reward function is:
[0053]
[0054] in, Represents the reward that the defender gets when the target i selected by the attacker is in the patrol plan, Represents the penalty obtained by the defender when the target i selected by the attacker is not in the patrol plan, A ijis the effectiveness of the defender's defensive activities, that is, the probability that the patrol plan j will conduct defensive activities on the target i, is the defender's reward function value.
[0055] Effectiveness probability value A of different defense activities ij It is determined according to the duration of the activity. The longer the activity, the higher the probability of catching the attacker. If the target i is not in the patrol plan j of the patrol team, A ij is 0.
[0056] Other steps and parameters are the same as those in Embodiment 1.
specific Embodiment approach 3
[0057] Specific implementation mode three: the difference between this implementation mode and specific implementation mode one or two is: the specific process of said step two is:
[0058] Step 21. In the patrol plan, merge the sub-patrol area and the defense activities corresponding to the sub-patrol area to obtain a single micro-defender strategy;
[0059] Step 22. Denote the maximum patrol time as τ, and the shortest duration of a single defensive activity as ρ, and calculate value, where Represents rounding down, the The value of is recorded as n;
[0060] Step two and three, in each patrol plan, randomly generate a micro strategy comprising n sub-patrol areas;
[0061] If the micro-policy generated in at least one patrol plan satisfies the condition: the generated micro-policy contains n sub-patrol areas that provide the defender with the highest reward (that is, each sub-patrol area in the n sub-patrol areas provides the defender with activity with the highest re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com