


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Intelligent news recommendation system based on emotion protection
A recommendation system and news technology, applied in the direction of specific mathematical models, probabilistic networks, and other database searches, can solve the problem that the emotional dictionary is difficult to cover completely, so as to facilitate personalized recommendations, suppress bad emotions, and avoid harm. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



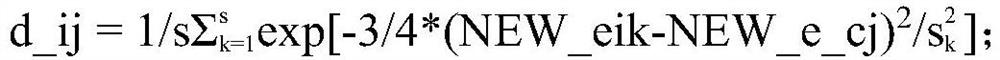
Examples
example 1
[0098] Example 1: Construct news feature matrix.
[0099] Step1_1, load the news content, news headlines, and user comments in the system as corpus data, clean the corpus data, and initialize the parameters of the BERT pre-training model;
[0100] Step1_2, convert the text into a vector form through the BERT model and compare the text content with the prepared non-characteristic vocabulary, remove the non-characteristic words in the text content, and segment the text with the non-characteristic words as the boundary;
[0101] Step1_3, calculate the Euclidean distance between the vector corresponding to each word after word segmentation and all other words in turn and accumulate them, and take the top 2 items with the highest results as the feature words corresponding to the news;
[0102] Set the vector after word segmentation as:
[0103] word1=[0.25,0.32,0.18,...,0.67];
[0104] word2=[0.35,0.64,0.37,...,0.82];
[0105] word3=[0.25,0.32,0.15,...,0.66];
[0106] Euclidean...
example 2
[0111] Example 2: Sentiment Grading.
[0112] Step2_1, randomly select the emotional feature vectors as positive emotions, compare positive emotions, neutral emotions, and compare negative emotions and the category center sum of negative emotions, divide the samples into five categories, and set the feature vectors as follows:
[0113] NEW_e_c1=[0.52,0.35,...,0.68];
[0114]NEW_e_c2=[0.62,0.38,...,0.82];
[0115] NEW_e_c3=[0.18,0.97,...,0.98];
[0116] NEW_e_c4=[0.27,0.48,...,0.64];
[0117] NEW_e_c5=[0.72,0.16,...,0.23];
[0118] Set the sample NEW_e1=[0.93,0.28,…,0.45], the vector dimension is 10, then the distance from the category center NEW_e_c1
[0119] in where n is the sample size;
[0120] Step2_2, the fuzzy classification matrix U is obtained through the fuzzy C-means clustering algorithm, and the solution formula of U is as follows:
[0121] Among them, u_ij represents the membership degree of sample i to category j, m is the fuzzy coefficient, and c is ...
example 3
[0134] Example 3: Construct user feature matrix.
[0135] Step3_1, r=2, take the randomly selected news label vector NEW_L1 as a circle with a center vector radius of 2 as a sliding window, and calculate the Euclidean distance L between all news label vectors and the center point NEW_L1 in turn, and calculate the distance between the news label vector and NEW_L1 that is less than or equal to r The news tag vectors are marked to the set M, that is, these points belong to cluster c1;
[0136] Step3_2, secondly calculate the offset vector N from the center vector NEW_L1 to all elements in the set i , get the offset vector N=N 1 +N 2 +…+N N ;
[0137] Set offset vector N1=[1.0,2.0,…,1.0], N2=[2.0,2.0,…,3.0],…,Nn=[3.0,4.0,…,3.0], then N=[6.0,8.0 ,...,7.0];
[0138] Step3_3, the center vector NEW_Li moves along the density rising direction (6.0 2 +8.0 2 +…+7.0 2 ) 1 / 2 distance;
[0139] Step3_4, the above operations until the offset is less than the threshold 5, mark the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com