Synthetic speech detection method based on speech segmentation
A technology for synthesizing speech and detection methods, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of high threat degree of ASV system, and achieve the effect of improving accuracy, improving detection accuracy, and high detection accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0038] In order to facilitate those skilled in the art to understand the technical content of the present invention, the content of the present invention will be further explained below in conjunction with the accompanying drawings.
[0039] The present invention is divided into a training stage and a deployment stage, the training stage is carried out on the server, the deployment stage is carried out after the training stage is completed, and the data in the training stage is deployed on the voice equipment.
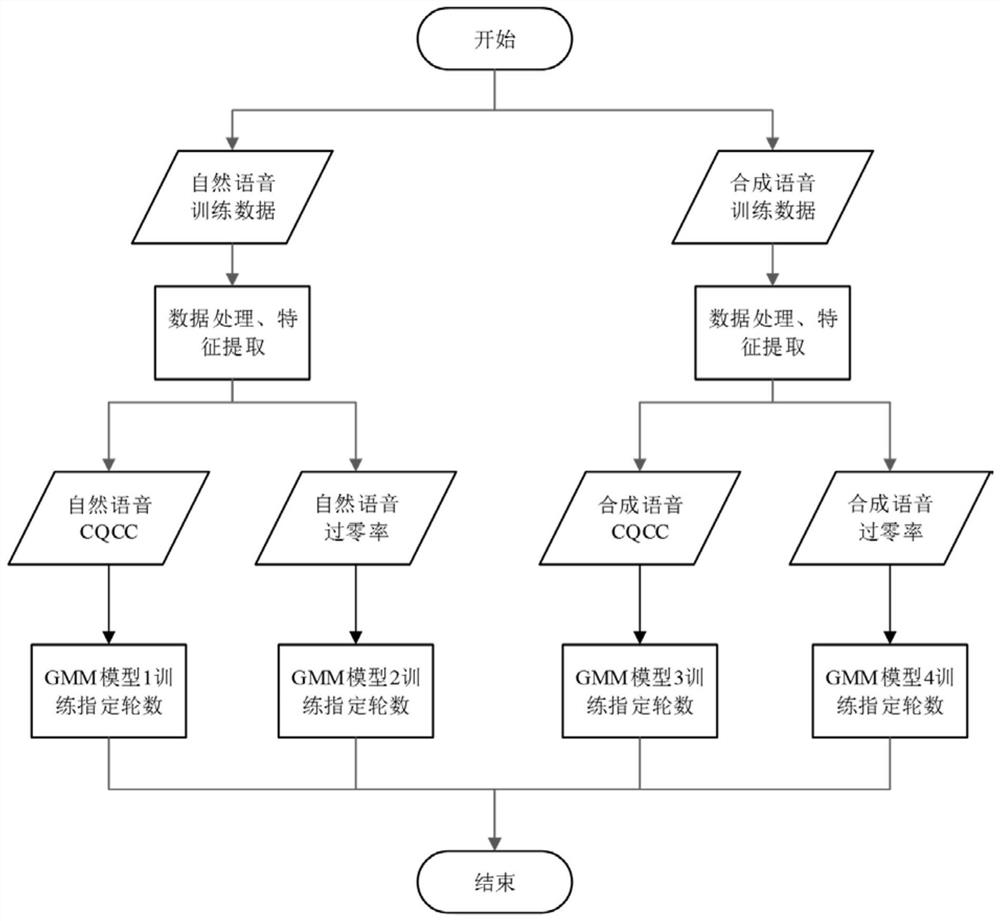
[0040] The training phase mainly includes two parts: data processing and model training.
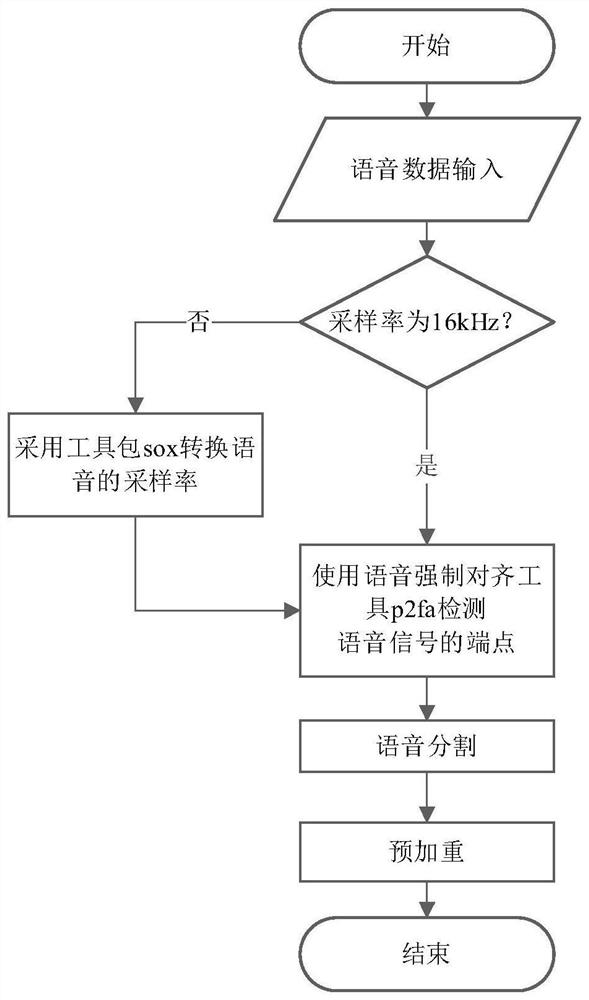
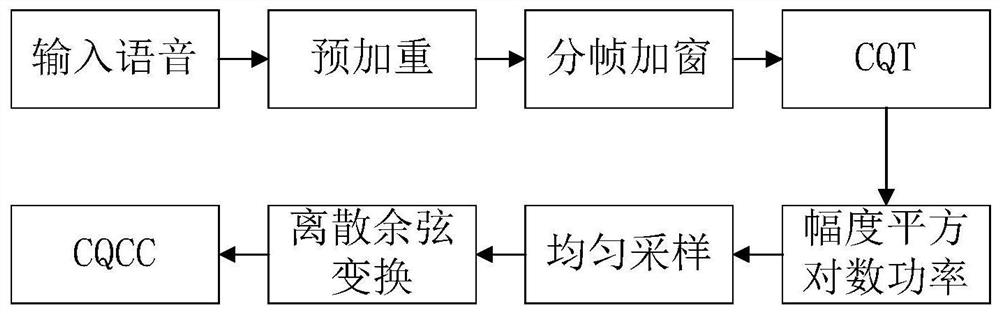
[0041] Step A data preprocessing is mainly to process the input original voice signal, detect the sampling rate, and perform endpoint detection of the voice signal (to find out the beginning and end of the voice signal), voice framing (approximately considered to be voice within 10-30ms) The signal is short-term stable, and the speech signal is divided into sections for analysis)...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com