Chinese literature data automatic acquisition method based on web crawler technology
A web crawler and document data technology, applied in the field of web crawlers, can solve the problems of inability to obtain data, achieve high crawling quality, solve data duplication and data missing problems, and facilitate data filtering
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049]In order to make the technical problems, technical solutions and beneficial effects to be solved by the present invention clearer, the present invention will be described in detail below in conjunction with the accompanying drawings and embodiments. It should be noted that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
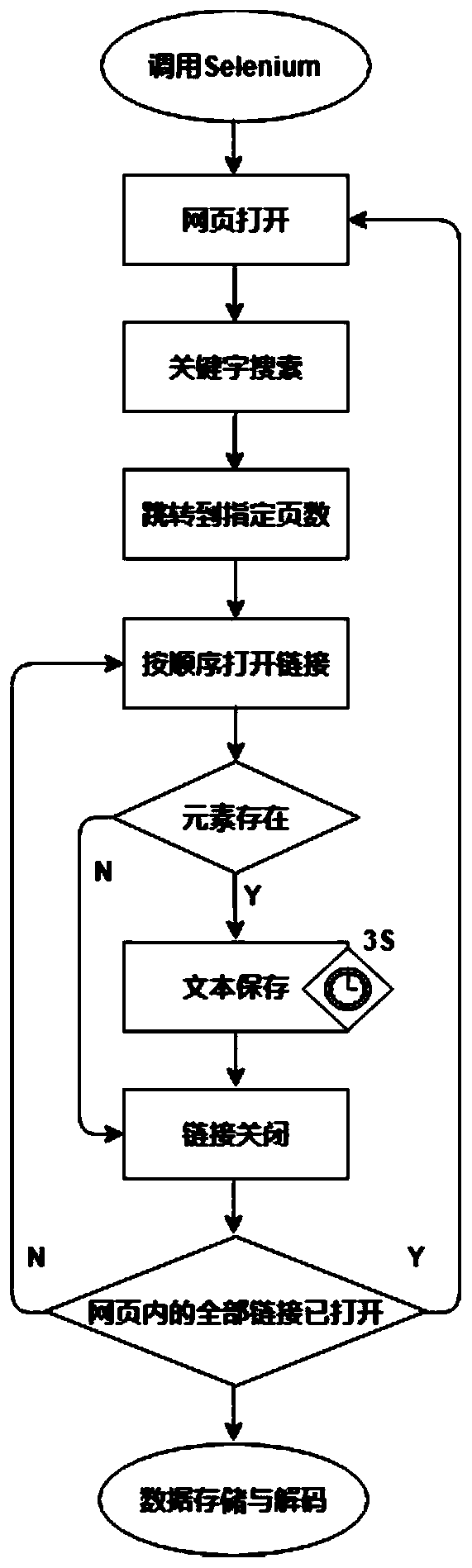
[0050] A method for automatically acquiring Chinese literature data based on web crawler technology, mainly including the following modules: a web page analysis module, a web page operation module, an element identification module, and a data storage module.
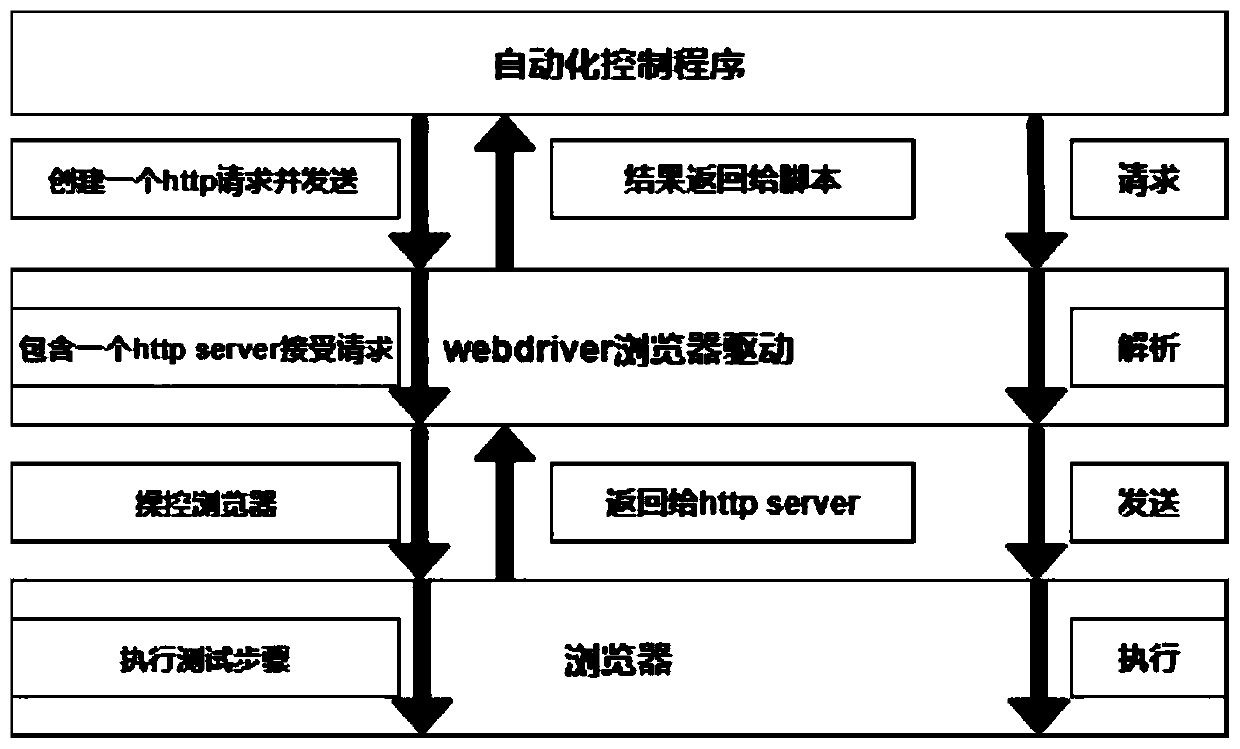
[0051] The webpage analysis module aims at performing webpage structure analysis and automatic operation on a given webpage. Such as figure 1 As shown, the basic process is: (1) for each program script, a network request will be created and sent to the browser driver; (2) the browser driver includes a web server to receiv...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com