Fictitious self-play-based multi-person incomplete information game policy resolving method, device and system as well as storage medium
A non-complete, two-player game technology applied in the field of artificial intelligence
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
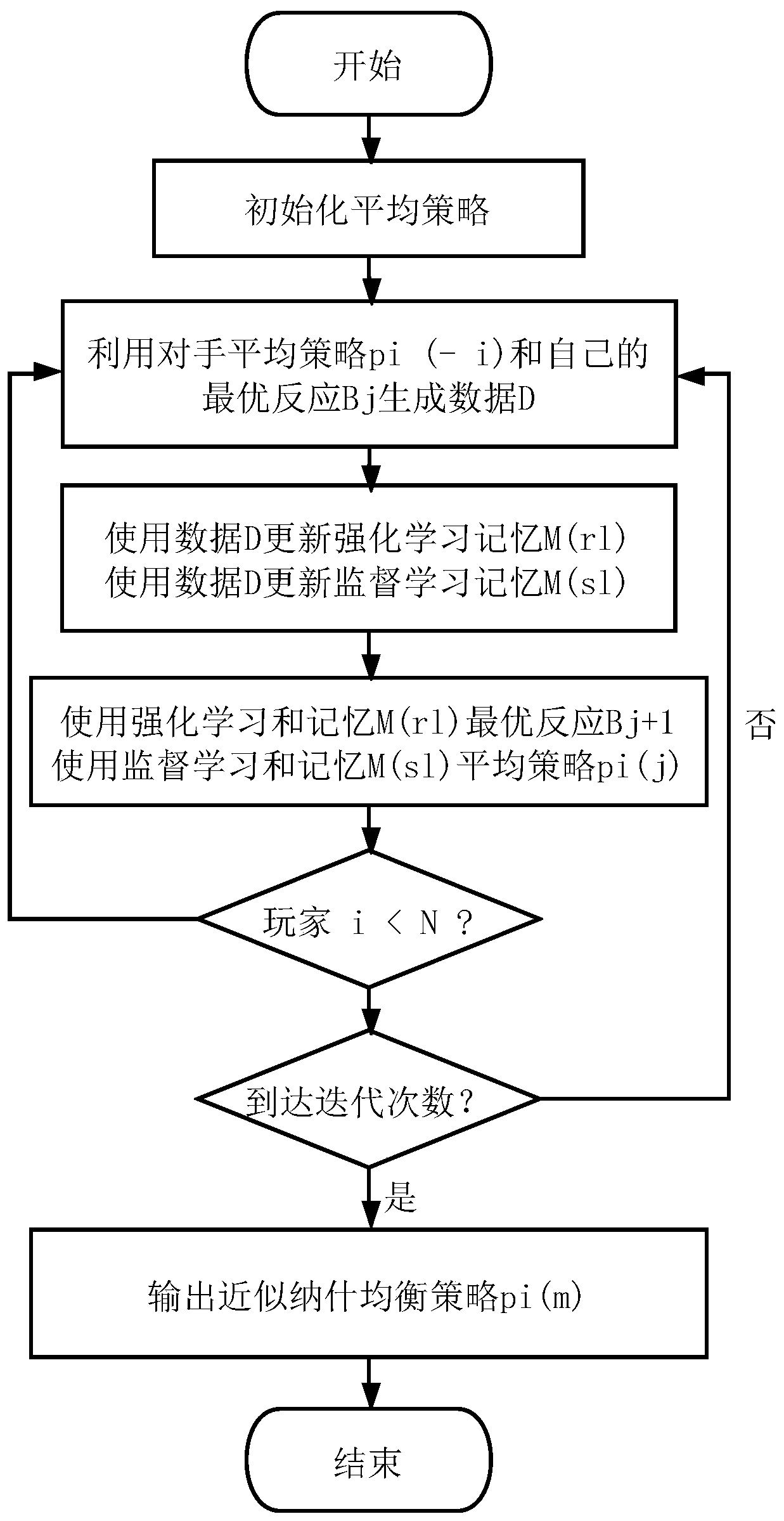
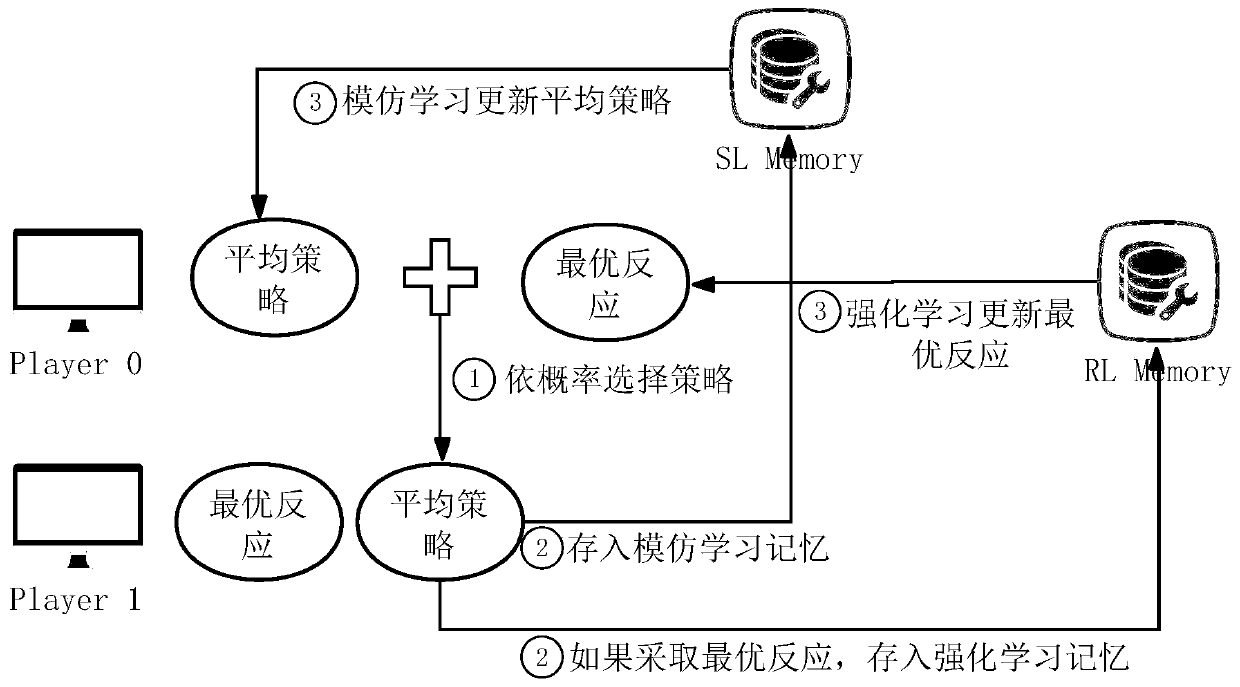
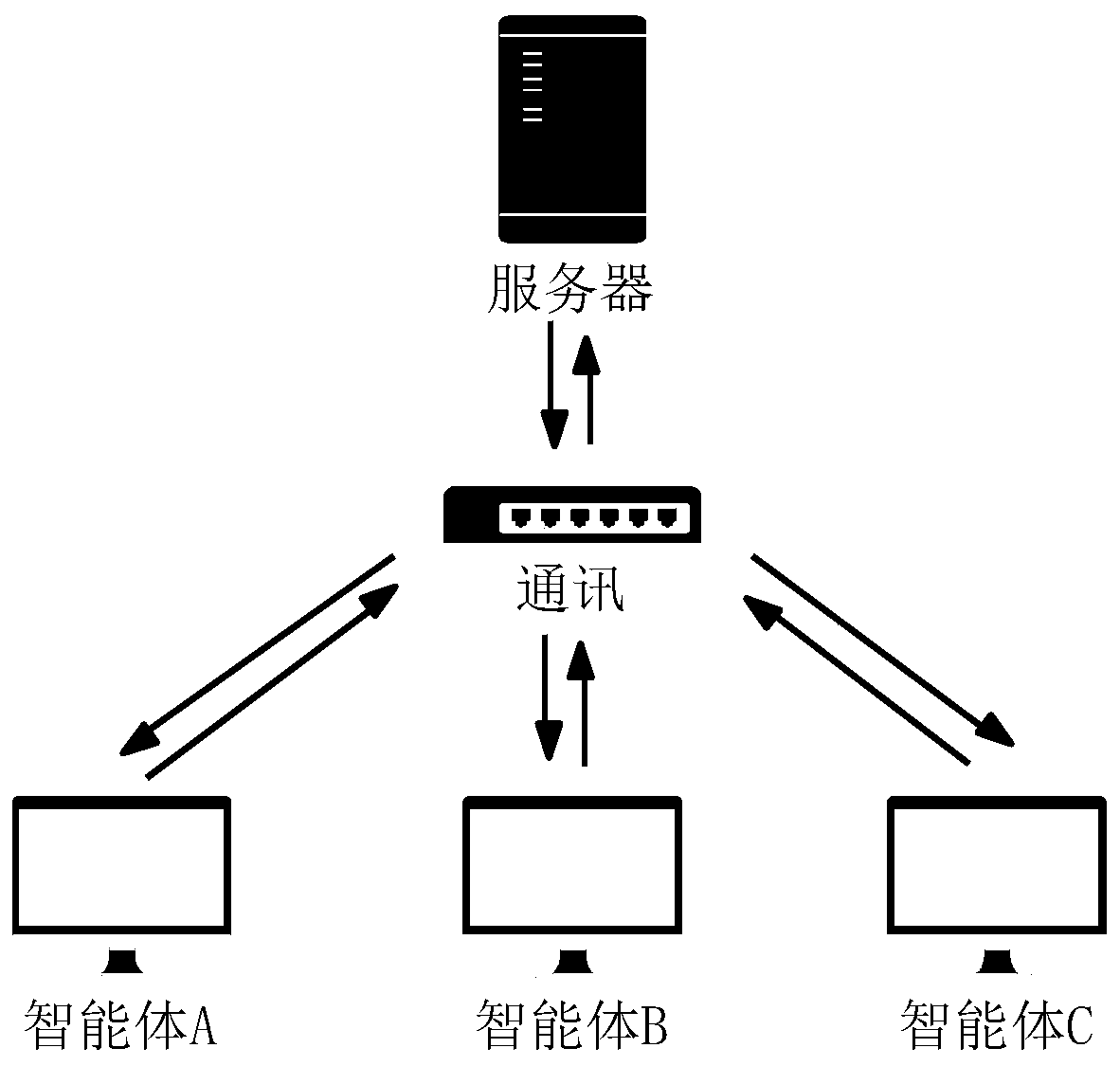
[0024] 1.1 The present invention discloses a multiplayer incomplete information game strategy solution method based on virtual self-play. Taking multiplayer unrestricted Texas Hold'em as an example, the present invention is a multiplayer unrestricted Texas Hold'em strategy solving algorithm. The invention is based on virtual self-play, combined with deep learning, multi-agent reinforcement learning and other technologies, and uses Texas Hold'em and multi-agent particle environment as the experimental platform. When the traditional method solves the incomplete information game problem of Texas Hold'em, it needs to use card abstraction and other field methods to reduce the size of the game tree, and the transferability is poor. The present invention introduces the algorithm framework of virtual self-play, divides the strategy optimization process of Texas Hold'em into two parts, the optimal response strategy learning and the average strategy learning, and uses imitation learning ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com