


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A depth K-means clustering method for time series data
A technology of time series and clustering methods, which is applied to instruments, character and pattern recognition, computer components, etc., can solve the problems of noise and outlier sensitivity, and can not be well adapted to clustering, so as to improve accuracy and better Clustering operation, noise reduction effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
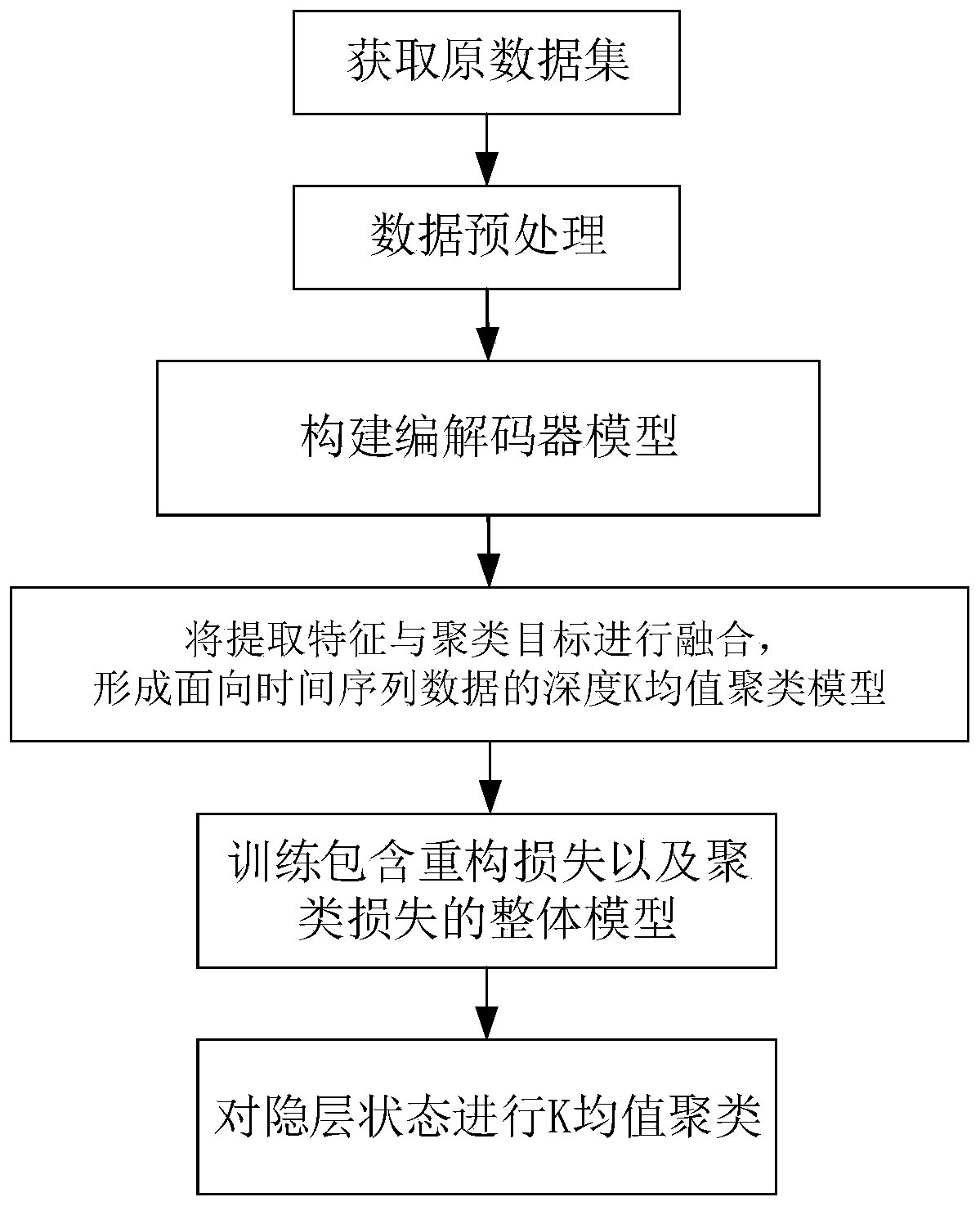
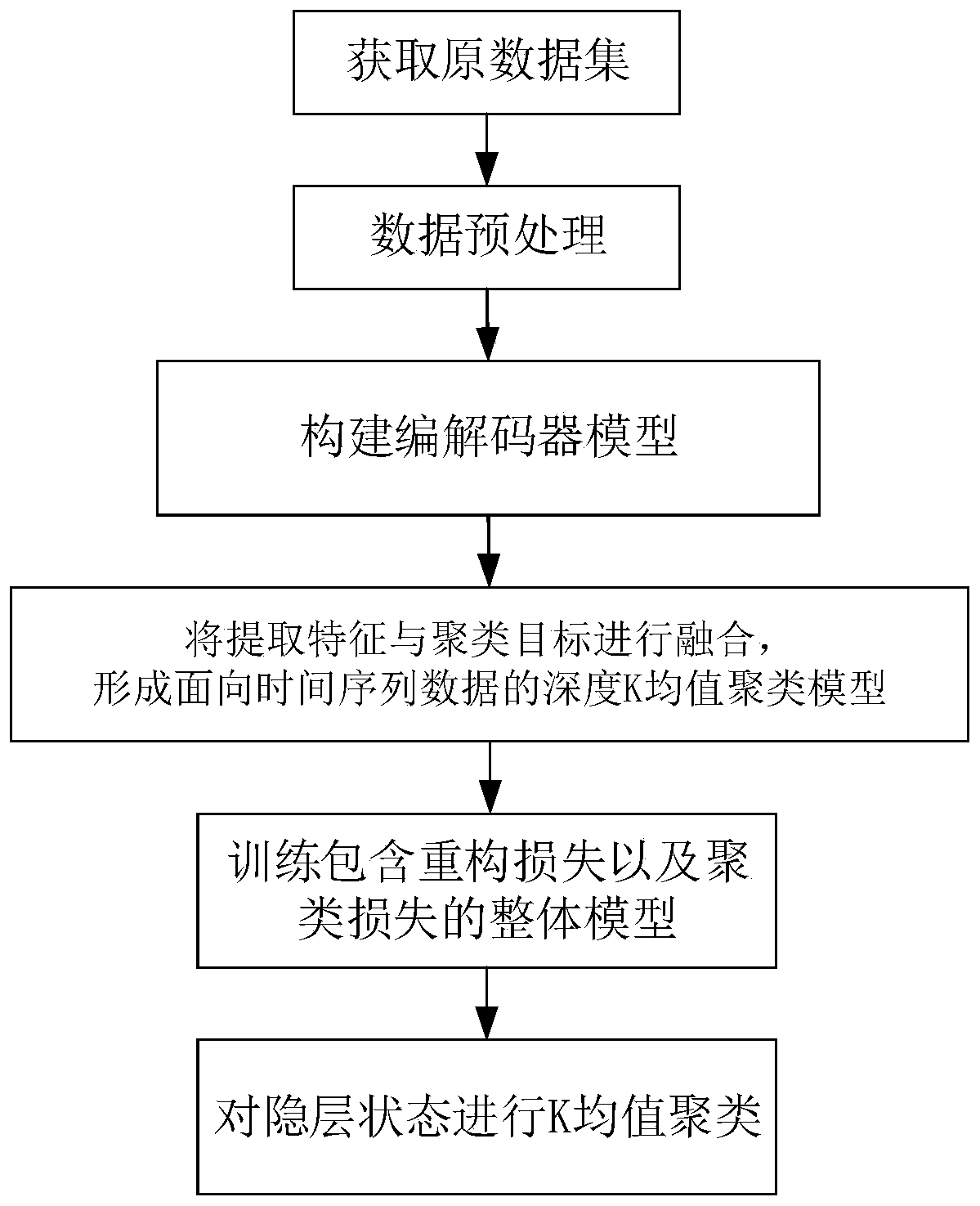
[0054] Such as figure 1 As shown, the depth K-means clustering method for time series data disclosed in this embodiment includes the following steps:
[0055] Step S1: Obtain a time series data set, preprocess the data, and separate sample information and category information of the data. The data set uses the UCR_TS_Archive_2015 data set. It includes 48 data sets, including both artificially synthesized and real data sets, covering various fields. Each data set contains 56 to 9236 pieces of data. The length of the sequence in the same data set is the same, and the length of the sequence in different data sets ranges from 24 to 1882. To label these data sets, each sequence can only belong to one class. In clustering, it should be interpreted as the cluster to which the sequence belongs.
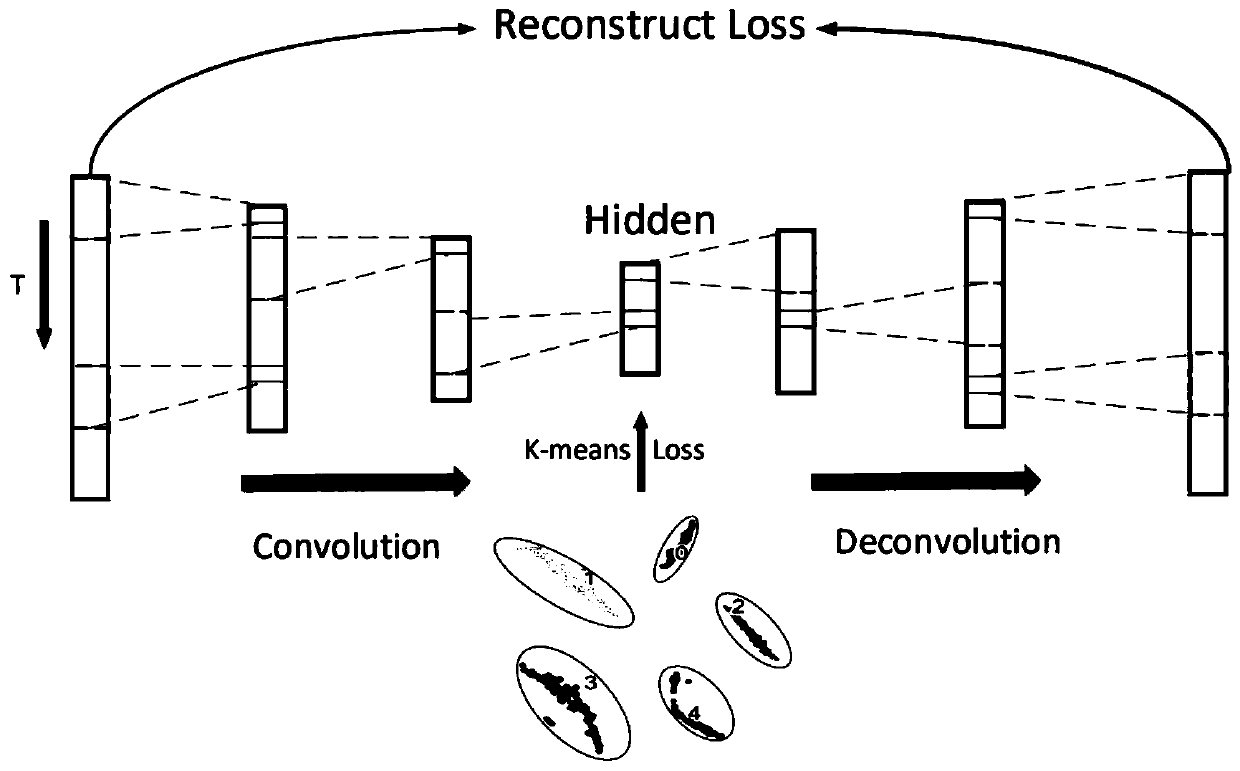
[0056] Step S2, construct a codec model, wherein the encoder adopts a three-layer convolution structure, and the decoder adopts a three-layer deconvolution structure.
[0057] Step S3, forming a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com