


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Voice dereplication method, device thereof, server and storage medium
A voice and algorithm technology, applied in the field of Internet technology applications, can solve the problems of ignoring the deep information of voice content and rough evaluation, and achieve the effect of fast and effective deduplication processing.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

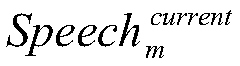
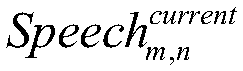
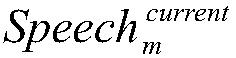
Examples
Embodiment 1
[0027] figure 1 It is a flow chart of a voice deduplication method provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation where voice deduplication is implemented based on the deep information of voice content in many voice data. The method can be deduplicated by voice device, wherein the device may be implemented by software and / or hardware. Such as figure 1 As shown, the method of this embodiment specifically includes:
[0028] S110. Obtain the MFCC feature matrix of the target short speech by using the MFCC algorithm of Mel-frequency cepstral coefficients, and convert the MFCC feature matrix into a target image.
[0029] Among them, the Mel frequency is proposed based on the auditory characteristics of the human ear, and has a nonlinear corresponding relationship with the HZ frequency. Among them, the auditory characteristic of the human ear is that the human ear has different perception capabilities to speech signals of differe...
Embodiment 2
[0084] figure 2It is a flowchart of a voice deduplication method provided by Embodiment 2 of the present invention. In this embodiment, on the basis of the above-mentioned embodiments, the optional conversion of the MFCC feature matrix into a target image includes: adjusting the row-column ratio of the MFCC feature matrix according to a first preset rule, so that the row-column ratio It is the same as the preset aspect ratio of the target image; the MFCC feature matrix after adjusting the row-column ratio is converted into a grayscale image, wherein each element in the MFCC feature matrix after adjusting the row-column ratio corresponds to the A grayscale value in the grayscale image; converting the grayscale image into an RGB three-primary-color image, and using the RGB three-primary-color image as the target image. Further, before adjusting the ratio of rows and columns of the MFCC feature matrix according to the preset first rule, it is optional to further include: perfor...
Embodiment 3
[0106] image 3 It is a flowchart of a voice deduplication method provided by Embodiment 3 of the present invention. In this embodiment, on the basis of the above-mentioned embodiments, an optional deep learning model and a feature dimensionality reduction algorithm are used to extract the target image features of the target image, including: inputting the target image into the deep learning model, and The feature dimensionality reduction adjustment is performed through the last fully connected layer, and the target image features with preset dimensions are output, wherein the fully connected layer is set using a feature dimensionality reduction algorithm. Further, the optional determination of the target index of the target image feature includes: performing normalization processing on the elements in each dimension of the target image feature; using the second preset rule, the normalized The subsequent elements in each dimension are subjected to binary quantization to obtai...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com