


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
K-means text clustering method and device with built-in constraint rules
A text clustering and text technology, applied in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc., can solve problems such as unsatisfactory results and high computational complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
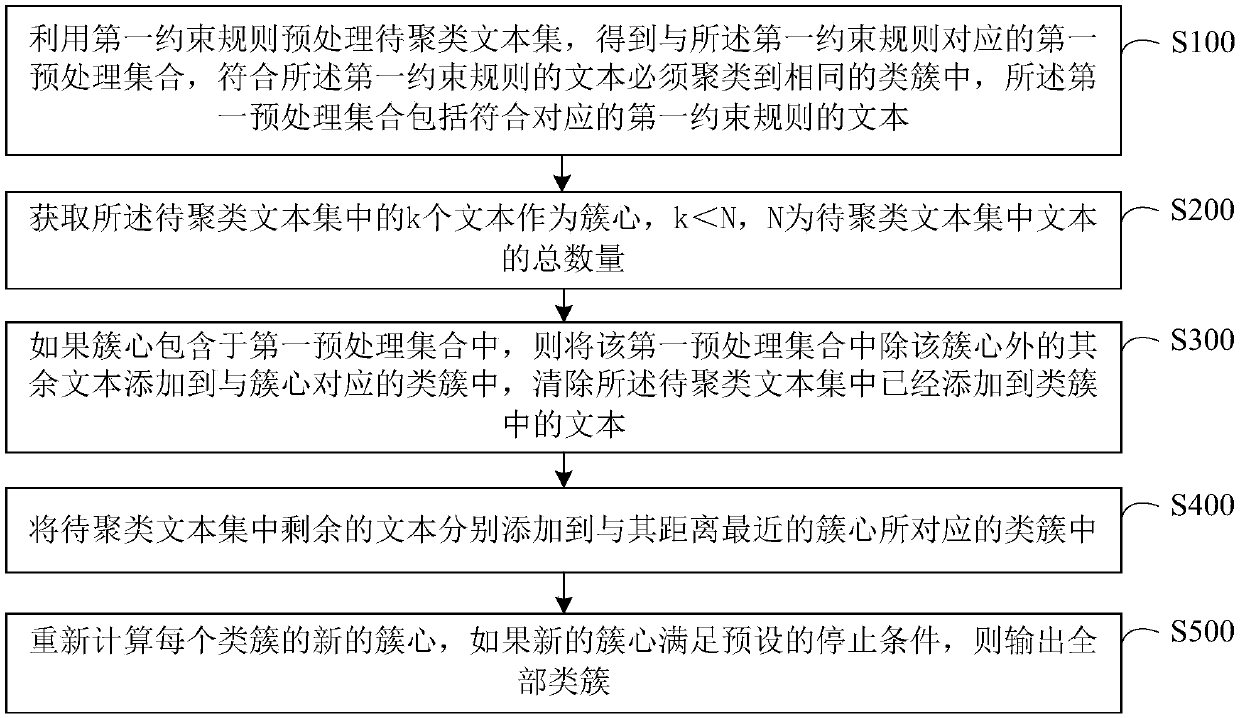
[0045] Please refer to figure 1 , in the first embodiment of the present application, a k-means text clustering method with built-in constraint rules is provided, including the following steps from S100 to S500:
[0046] S100: Using the first constraint rule to preprocess the text set to be clustered to obtain a first preprocessing set corresponding to the first constraint rule, the texts conforming to the first constraint rule must be clustered into the same cluster, The first preprocessing set includes texts conforming to corresponding first constraint rules.
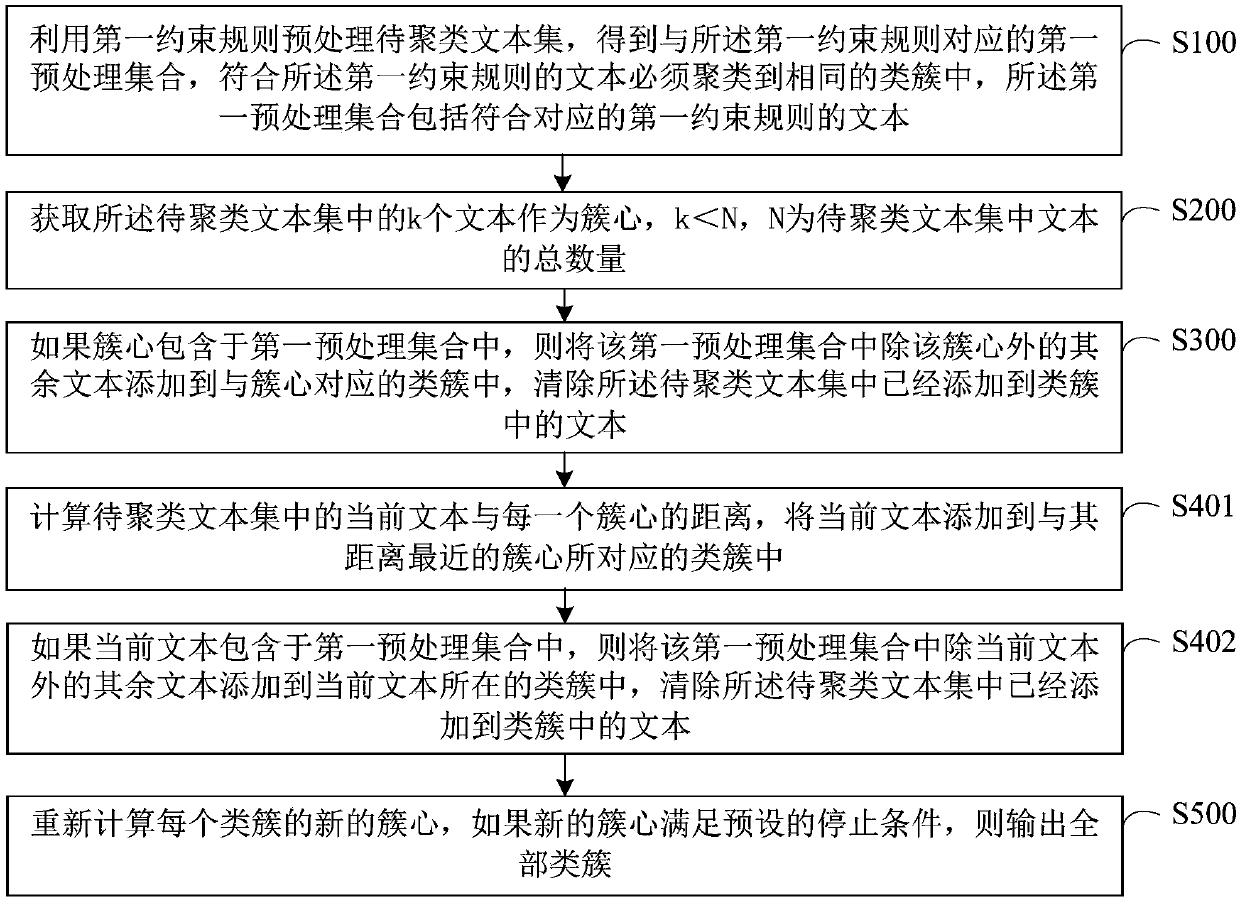
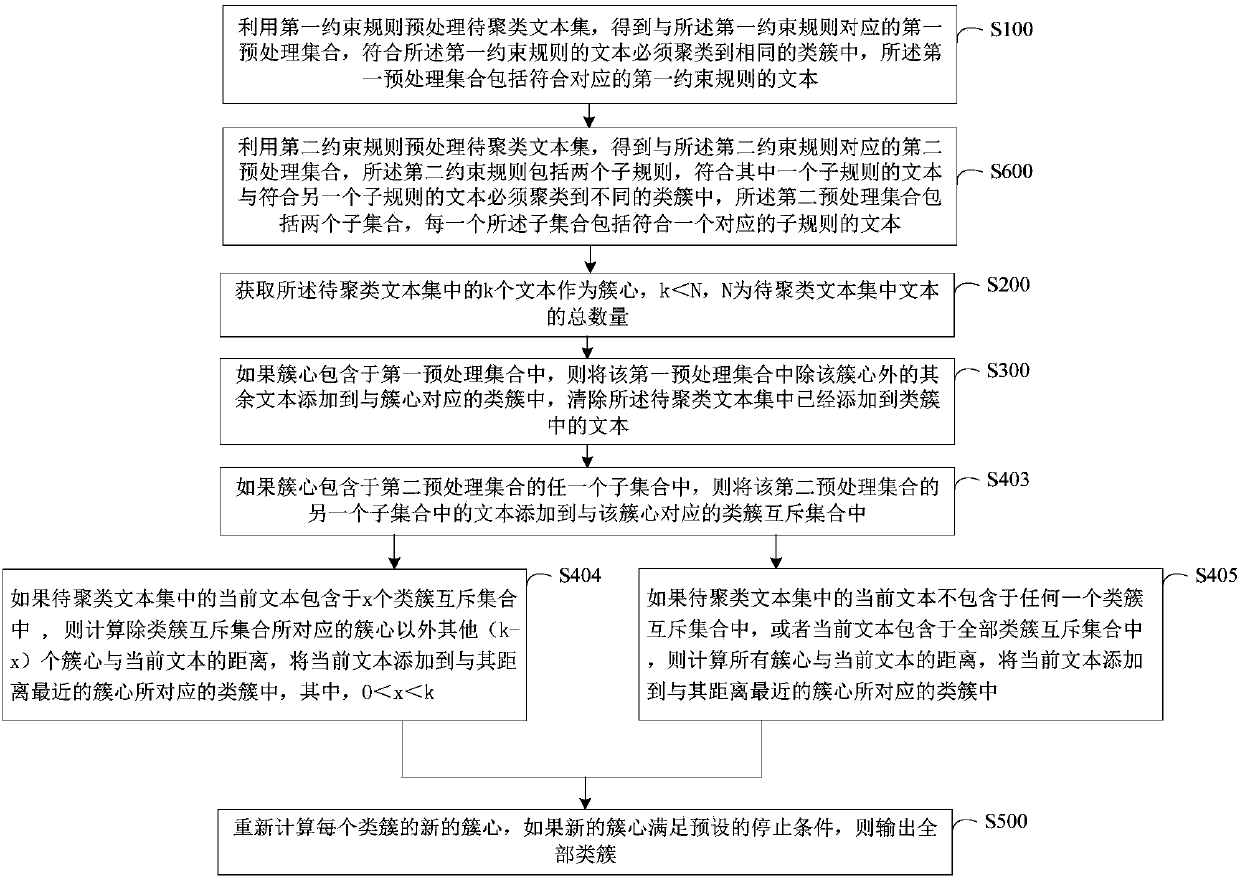
[0047] In the step of S100, the first constraint rule refers to a preset rule that texts conforming to the rule must be clustered into the same cluster. For example, if two texts A and B conform to a certain first constraint rule, when clustering the text set to be clustered including A and B, it is necessary to cluster A and B into the same cluster . Here, the texts in the text set to be clustered that meet differ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com