


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Quantitative F0 pattern generation device and method, and model learning device and method for generating F0 pattern
A technology for generating models and generating devices, which is applied in speech synthesis, speech analysis, instruments, etc., and can solve problems such as difficult to obtain model parameters
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 Embodiment approach
[0132]
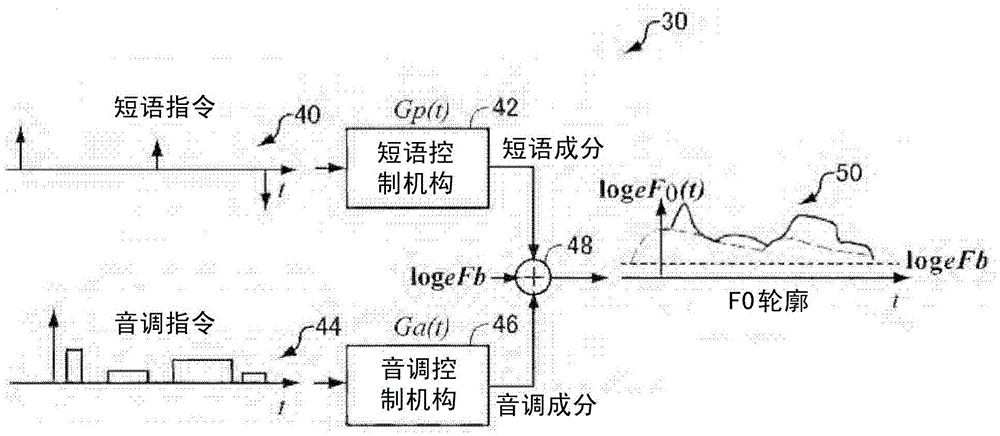
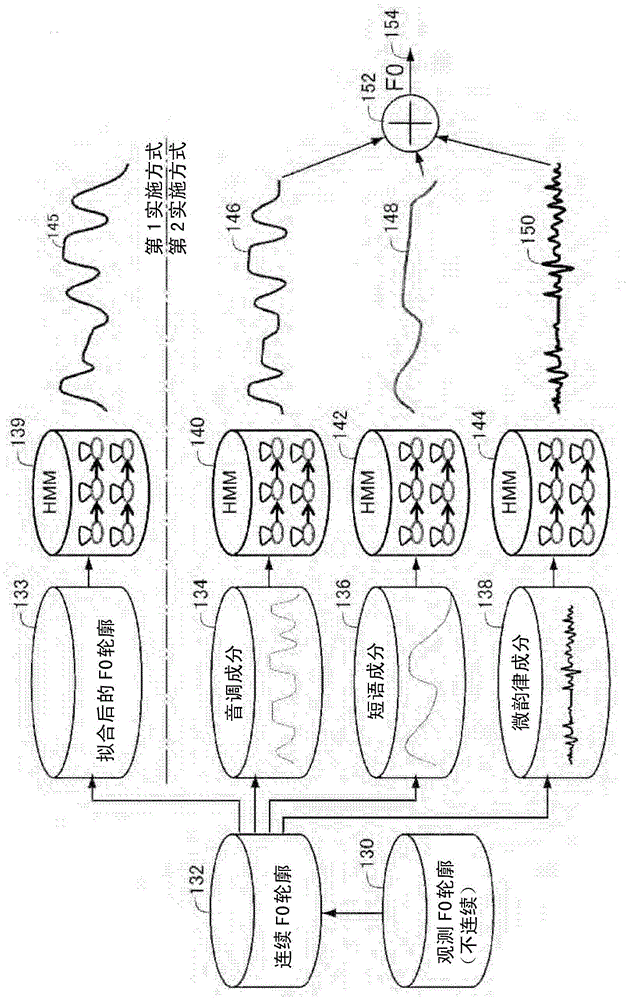
[0133] refer to Figure 7 , the F0 contour synthesizing unit 359 according to the first embodiment includes: a parameter estimation unit 366 for smoothing and serializing the observed F0 contour 130 observed from a plurality of sound signals included in the sound corpus to obtain The continuous F0 contour 132 of the given prosodic word boundary, according to the above-mentioned principle, estimates the target point for specifying the phrase component P and the target parameter for specifying the tone component A; the F0 contour fitting part 368, which passes The phrase component P and the tone component A estimated by the parameter estimation part 366 are synthesized to generate a fitted F0 profile fitted with a continuous F0 profile; the HMM learning part 369 uses the fitted F0 profile to generate Learning of the HMM is performed in the same manner as in the prior art; and the HMM storage device 370 stores the learned HMM parameters. The process of synthesizing th...
no. 2 Embodiment approach
[0156] In the first embodiment, the phrase component P and the tone component A are represented by target points, and the F0 profile is fitted by combining these components. However, the idea of using target points is not limited to this first embodiment. In the second embodiment, the observed F0 contour is separated into a phrase component P, a tone component A, and a micro-prosodic component M by the method described above, and HMM learning is performed on each of the time-varying contours of these components. When generating F0, the learned HMM is used to obtain the time-varying profiles of the phrase component P, the tone component A, and the micro-prosodic component M, and then these profiles are synthesized to estimate the F0 profile.
[0157]
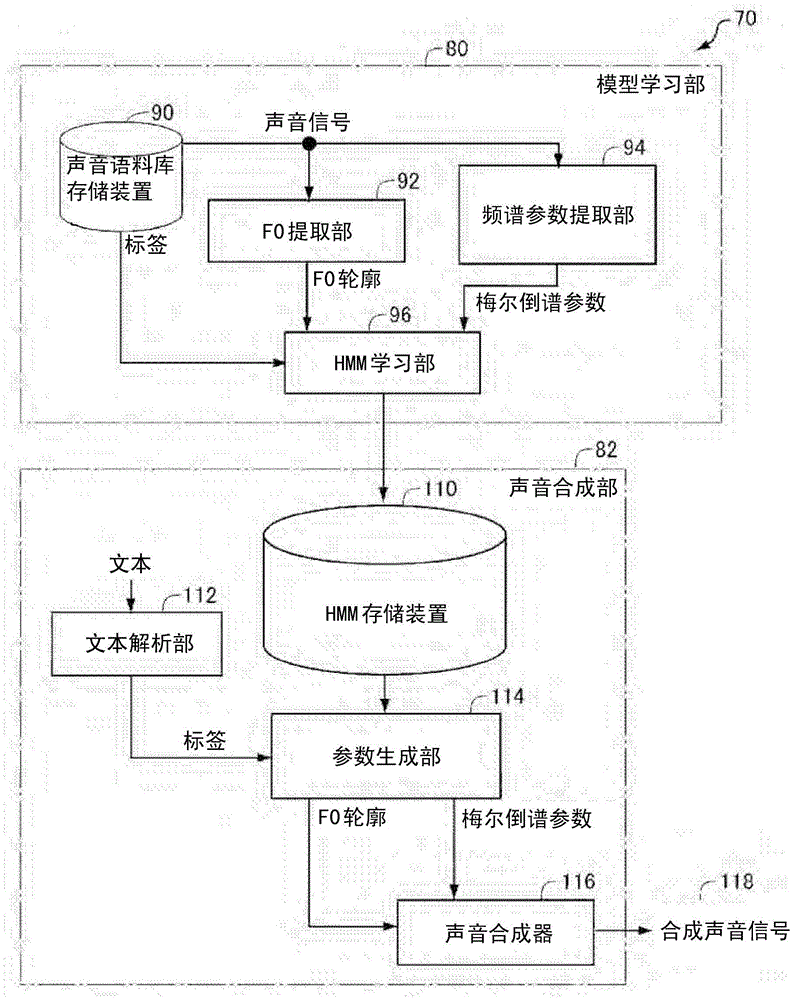
[0158] refer to Figure 9 , the sound synthesis system 270 according to this embodiment includes: a model learning unit 280 which learns an HMM used for sound synthesis; and a sound synthesis unit 282 which uses the HMM lear...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com