Document clustering method based on distribution-convergence model
A document clustering and clustering technology, which is applied in the cross-technology application field of data mining and knowledge system to achieve the effect of clarifying the knowledge context, improving computing efficiency and reducing time overhead.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

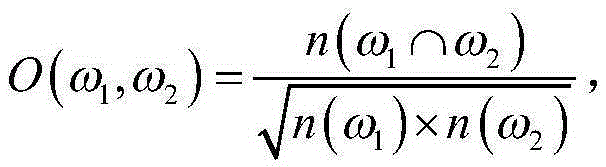

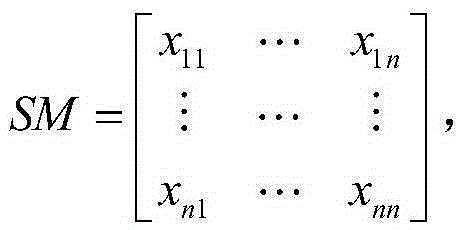
Examples
Embodiment Construction
[0020] The implementation of the present invention will be described in detail below. The implementation is exemplary and only used to explain the present invention, but not to limit the present invention.
[0021] The document clustering method based on the distribution-convergence model of the present invention comprises the following steps:
[0022] Step 1. Construction method of co-occurrence matrix based on distribution-convergence model
[0023] The present invention first proposes a co-occurrence matrix construction method based on the distribution-convergence model: the distribution-convergence model is used to count the co-occurrence frequency of knowledge attributes in pairs, and combined with the hash graph to construct the co-occurrence matrix, which solves the problem of the limited memory of a single computing node. Problems such as the inability to cluster or the reduction in clustering efficiency caused by storing and processing large matrices.
[0024] (1) Co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com