A Chinese Word Segmentation Incremental Learning Method
A Chinese word segmentation and incremental learning technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as high hardware requirements, long computing time, retraining models and large data processing volumes, etc., to achieve training Effects of cost reduction, processing time saving, and total saving
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

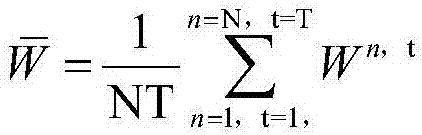
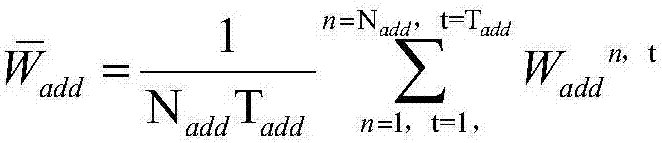
Examples
specific Embodiment approach 1
[0024] Specific implementation mode 1: This implementation mode is described in conjunction with FIG. 1 ,
[0025] A Chinese word segmentation incremental learning method, comprising the steps of:
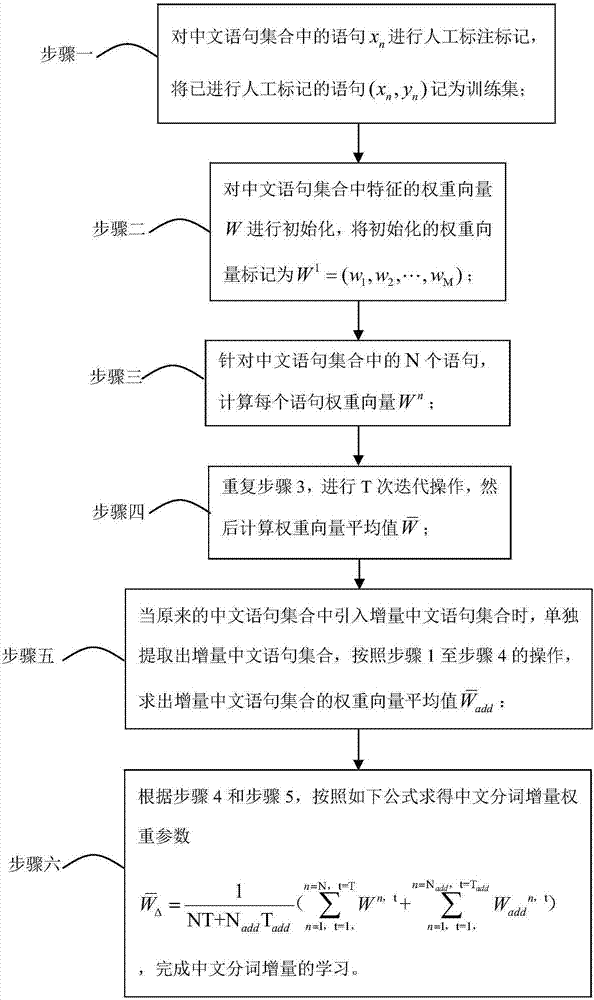
[0026] Step 1; suppose there are N statements in the Chinese statement set; for the statement x in the Chinese statement set n Carry out manual labeling, statement x n The result of manual labeling is y n ; Put the manually marked statement (x n ,y n ) is recorded as the training set, n is the sequence number of the statement, n=(1,2,...,N);
[0027] Step 2: Initialize the weight vector W of the features in the Chinese sentence set, and mark the initialized weight vector as W 1 =(w 1 ,w 2 ,...,w M ); where w 1 ,w 2 ,...,w M are the weights corresponding to each feature in the Chinese sentence set; M represents the number of all features in the Chinese sentence set;
[0028] Step 3: For the N sentences in the Chinese sentence set, calculate the weight vector W of each se...
specific Embodiment approach 2
[0041] The calculation of each sentence weight vector W for the N sentences in the Chinese sentence set described in step 3 of this embodiment n The specific steps are as follows:
[0042] Step 3.1: Segment the sentence x according to the Chinese word segmentation method n Carry out segmentation, there are many segmentation methods in the segmentation process, and each segmentation method is recorded as a possible marking result y′n ;
[0043] For the labeled result y' n , according to the feature extraction function Φ(x n ,y′ n ), to extract the feature vector (f 1 , f 2 ,..., f M );
[0044] Step 3.2: According to the following formula, calculate the statement x n is split into tokenized result y′ n When the score score;
[0045] score=w 1 f 1 +w 2 f 2 +…+w M f M =W n · Φ(x n ,y′ n )
[0046] Step 3.3: To statement x n All possible segmentation methods are segmented, and the corresponding score is calculated, the segmentation method with the largest scor...
Embodiment
[0053] Conduct experiments on CTB5.0 and Zhu Xian web novel data. The source field selects CTB5.0 data, and the CTB5.0 data is divided into CTB5.0 training set and CTB5.0 test set according to the division method in "Enhancing Chinese Word Segmentation Using Unlabeled Data". The incremental data is selected from Zhu Xian’s novels, which are recorded as ZX; the data division of Zhu Xian’s novels refers to the division method of "Type-supervised domain adaptation for joint segmentation and pos-tagging", and is divided into ZX training set and ZX test set. Randomly select 500 sentences of ZX training data in the ZX training set as a small-scale training set, and randomly select 2400 sentences of ZX training data in the ZX training set as a large-scale training set.
[0054] The training data in the CTB5.0 training set is used for training, and then the CTB5.0 test set and the ZX test set are used for testing. The test results are shown in Table 1, and the experimental results are...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com