Method for realizing task data decoupling in spark operation scheduling system
A job scheduling and data decoupling technology, applied in the direction of multi-programming devices, etc., can solve the problem of lack of task scheduling implementation, and achieve the effects of improving coordination and maintainability, enhancing collaborative development capabilities, and improving maintainability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment
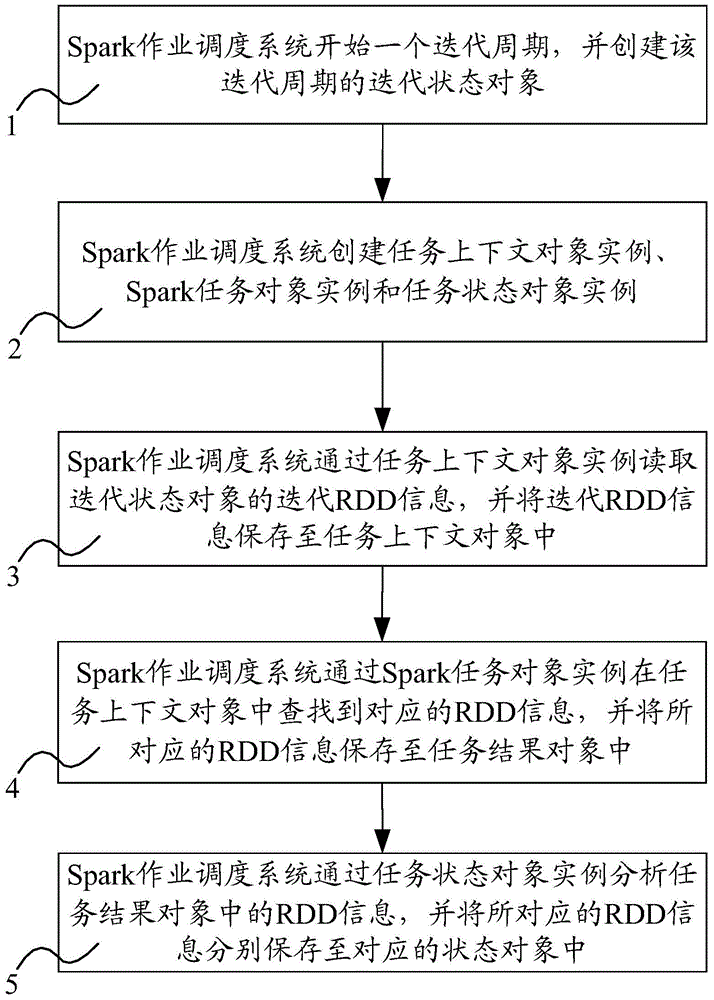
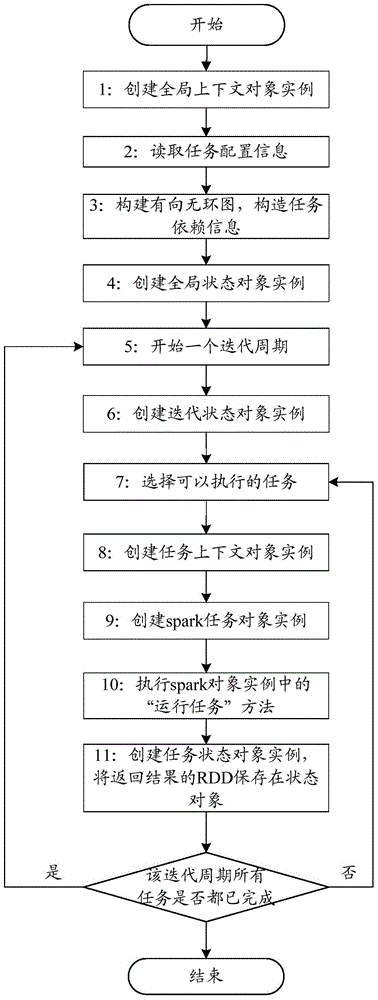
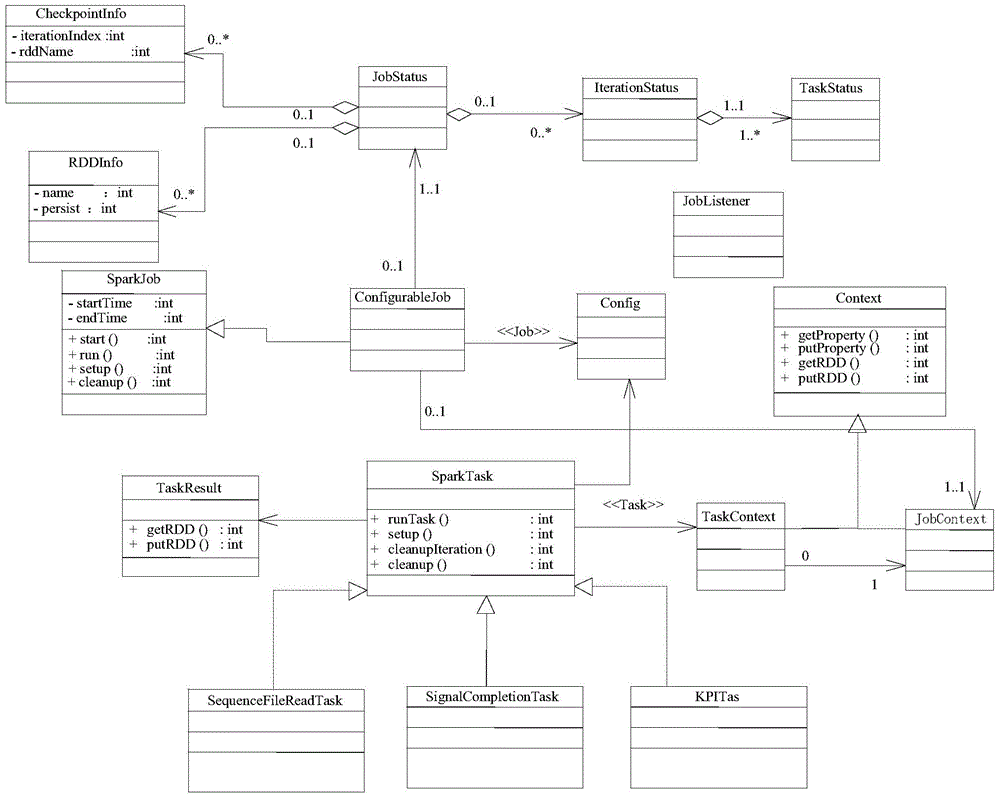
[0073] In practical applications, such as figure 2 As shown, it is a specific embodiment of the present invention, and the specific process is as follows:
[0074] 1: First create a global context object, which will save the context information and global attribute information of the Spark runtime state. These attribute information can be specified by the developer.
[0075] 2: Read the configuration information of each task
[0076] 3: According to the configuration information of these tasks, a directed acyclic graph will be constructed, and the dependencies of tasks can be analyzed through the directed acyclic graph.
[0077] 4: Create a global state object instance, which saves the RDD information of the global scope and the iteration state object of each iteration cycle. In this way, all state objects can be traversed through the object instance to obtain necessary RDD information.
[0078] 5: Start an iterative cycle, and execute the tasks in this cycle in sequence according to...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com