A method and device for extracting deduplication feature values of web crawlers
A technology of web crawler and extraction method, which is applied in the field of extraction of web crawler deduplication eigenvalues, which can solve problems such as waste of network resources and system memory, failure of deduplication, and impact on data analysis effects, etc., to achieve improved accuracy and high computing efficiency , the effect of weight removal is obvious
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

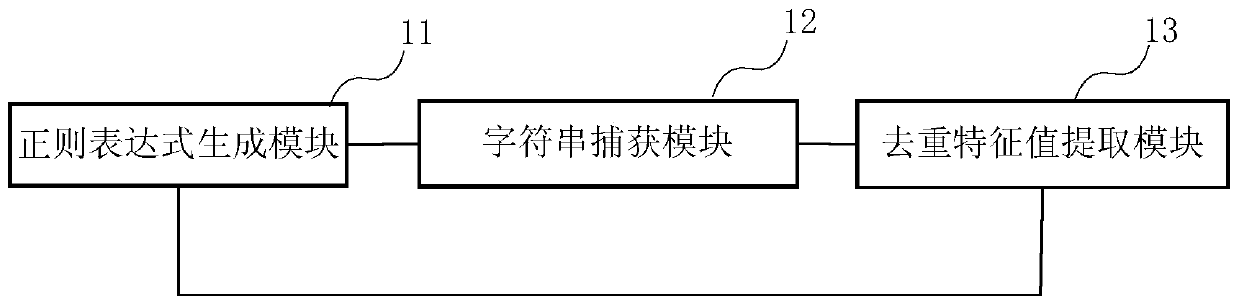
Examples
Embodiment Construction
[0023] The technical solutions of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
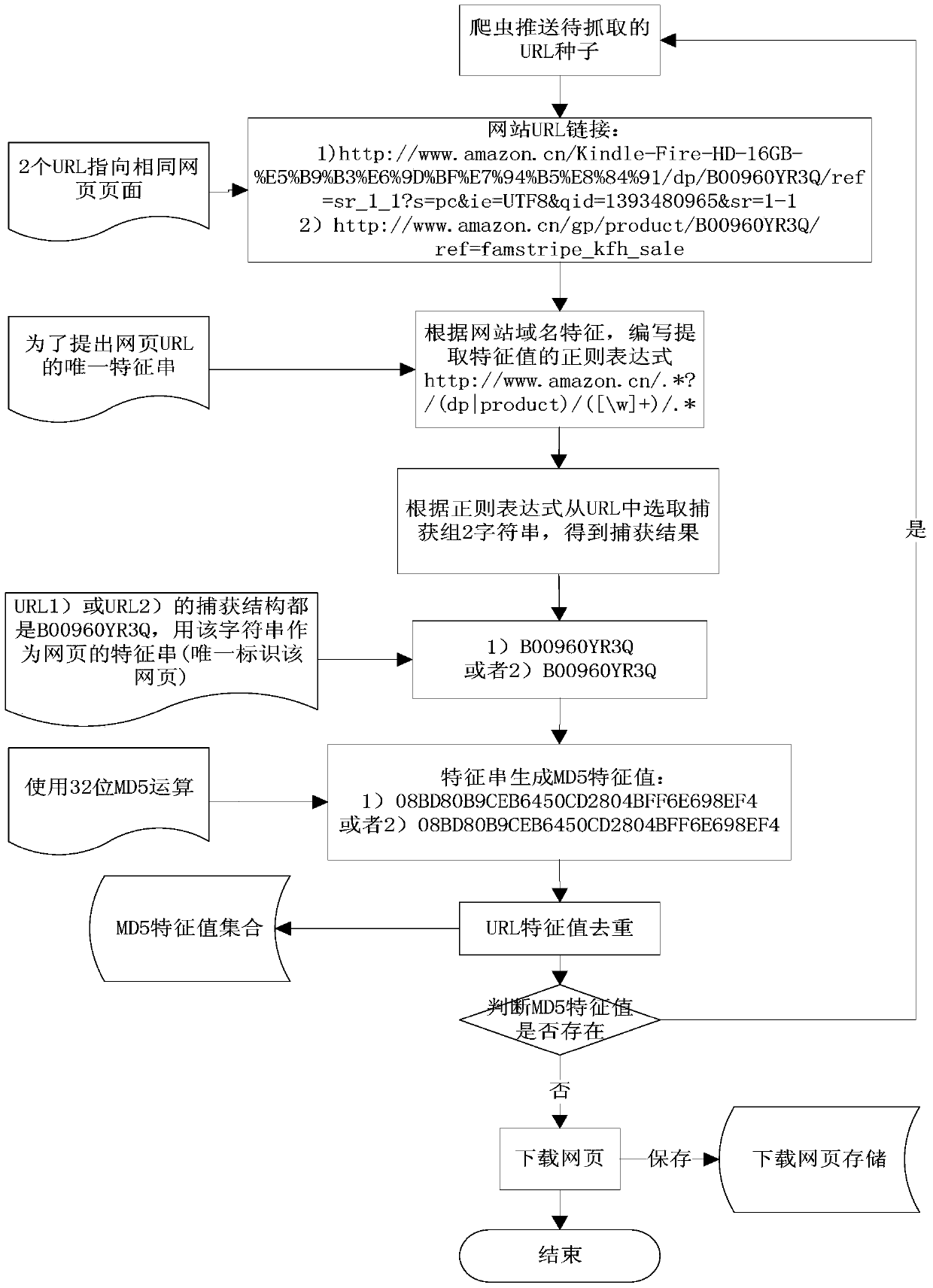
[0024] Based on the characteristics of the URL string of the target website, the invention extracts a substring that can uniquely identify the webpage from the URL link pushed by the crawler as a webpage feature string, and then converts the format of the feature string to obtain a deduplication feature value. In the case of multiple URL links pointing to the same page, after deduplication of the characteristic value of this method, the page is downloaded only once, and repeated downloads will not occur.
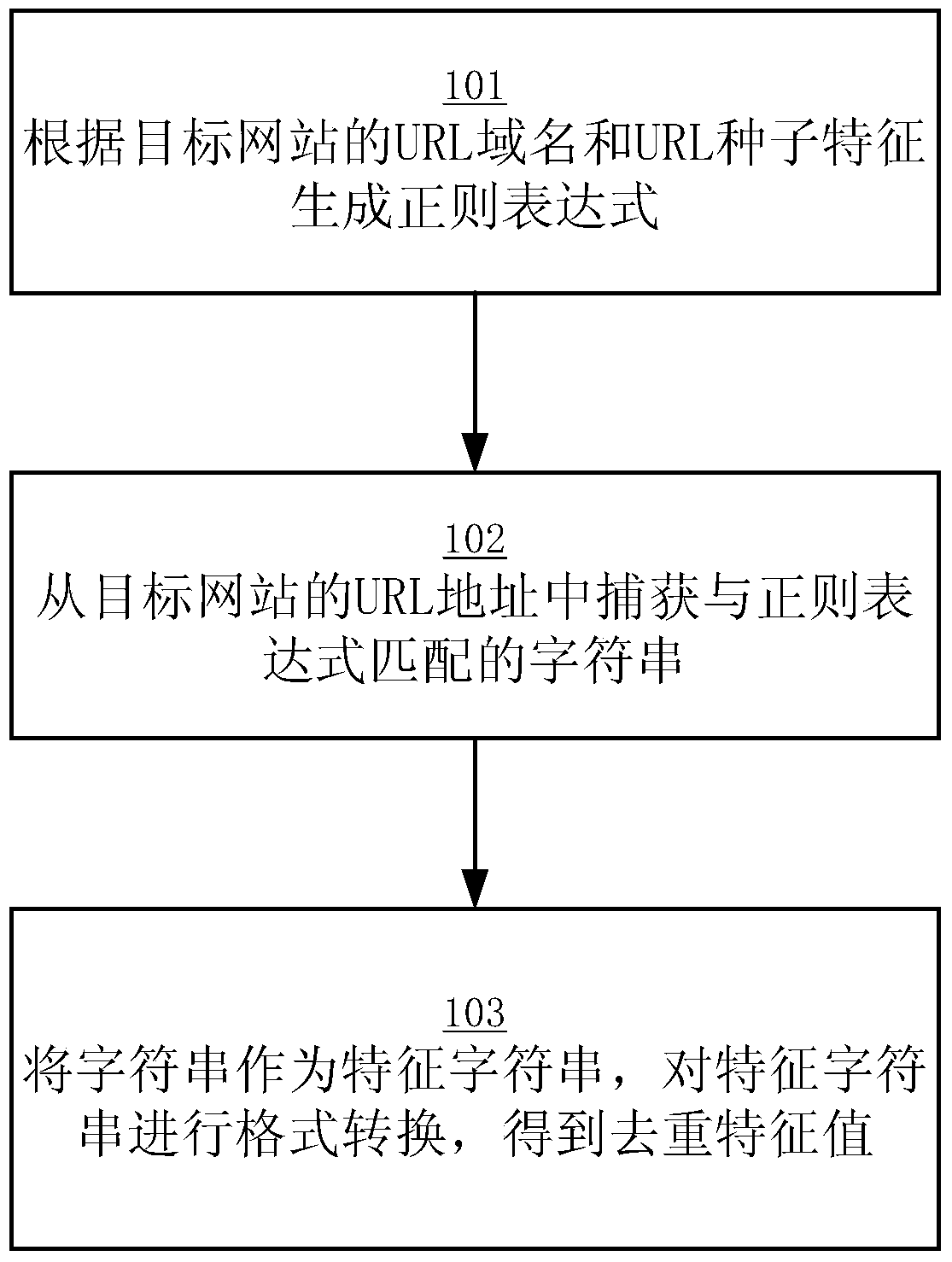
[0025] figure 1 A block flow diagram showing a method for extracting a web crawler deduplication feature value according to an embodiment of the present invention, including:
[0026] S101, generating a regular expression according to the URL domain name and the URL seed feature of the target website;
[0027] S...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com