


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Massive geoscientific data parallel processing method based on distributed file system
A technology for distributed files and data, applied in the fields of ecology and geoinformatics
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
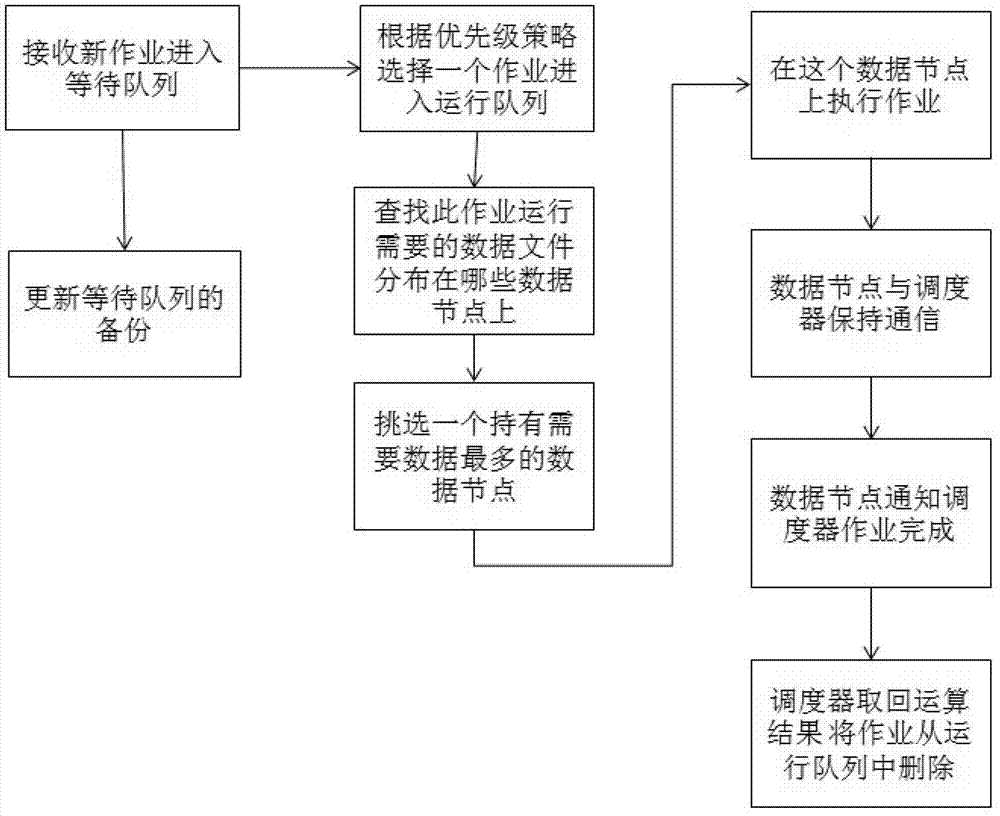
[0026] In many distributed computing frameworks, the biggest problem in processing massive data is that it is difficult to avoid the transmission of large amounts of data on the network. For example, the commonly used open source MapReduce system Hadoop, many algorithms will generate a large amount of traffic on the network during the Reduce phase. Due to the huge difference between the CPU processing speed and the network transmission speed, this is often the biggest bottleneck in the efficiency of the entire computing process. Since geoscience data has the characteristics of large data volume and high calculation complexity, it is difficult to meet the user's requirements for calculation time by using conventional distributed computing methods. In order to solve this problem, the present invention designs a job scheduling system, combined with specific functions (The user is allowed to specify the physical location of the file copy, so that all the data blocks of a file copy ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com