


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Method and device for compensating drop frame after start frame of voiced sound
A compensation method and a start frame technology, applied in the field of speech coding and decoding, can solve the problem that the compensation sound quality is not guaranteed, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
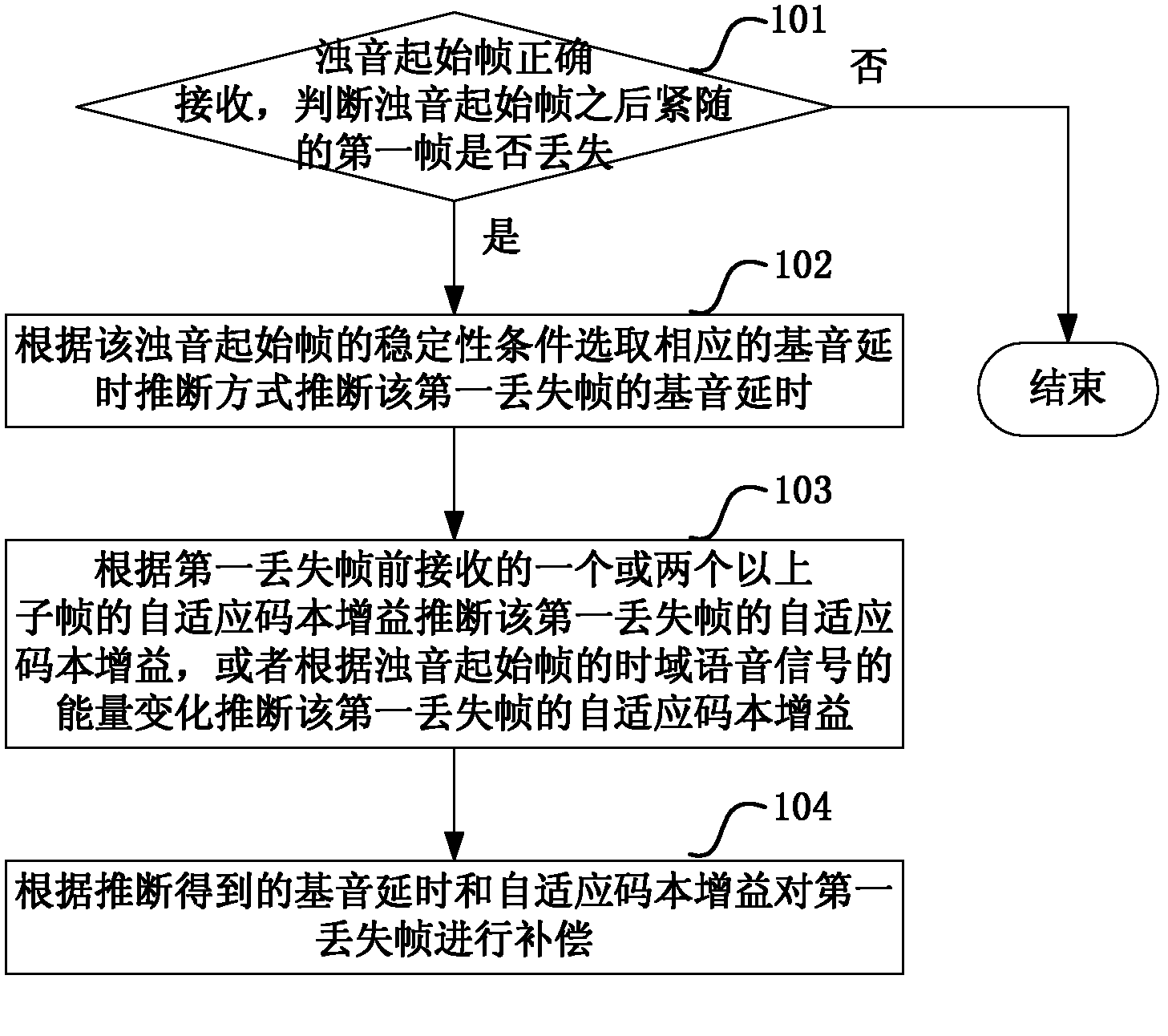
[0032] This embodiment describes a method for compensating after loss of the first frame immediately after the voiced sound start frame, such as figure 1 shown, including the following steps:
[0033] Step 101, the voiced sound start frame is correctly received, and it is judged whether the first frame (hereinafter referred to as the first lost frame) following the voiced sound start frame is lost, if lost, execute step 102, otherwise the process ends;
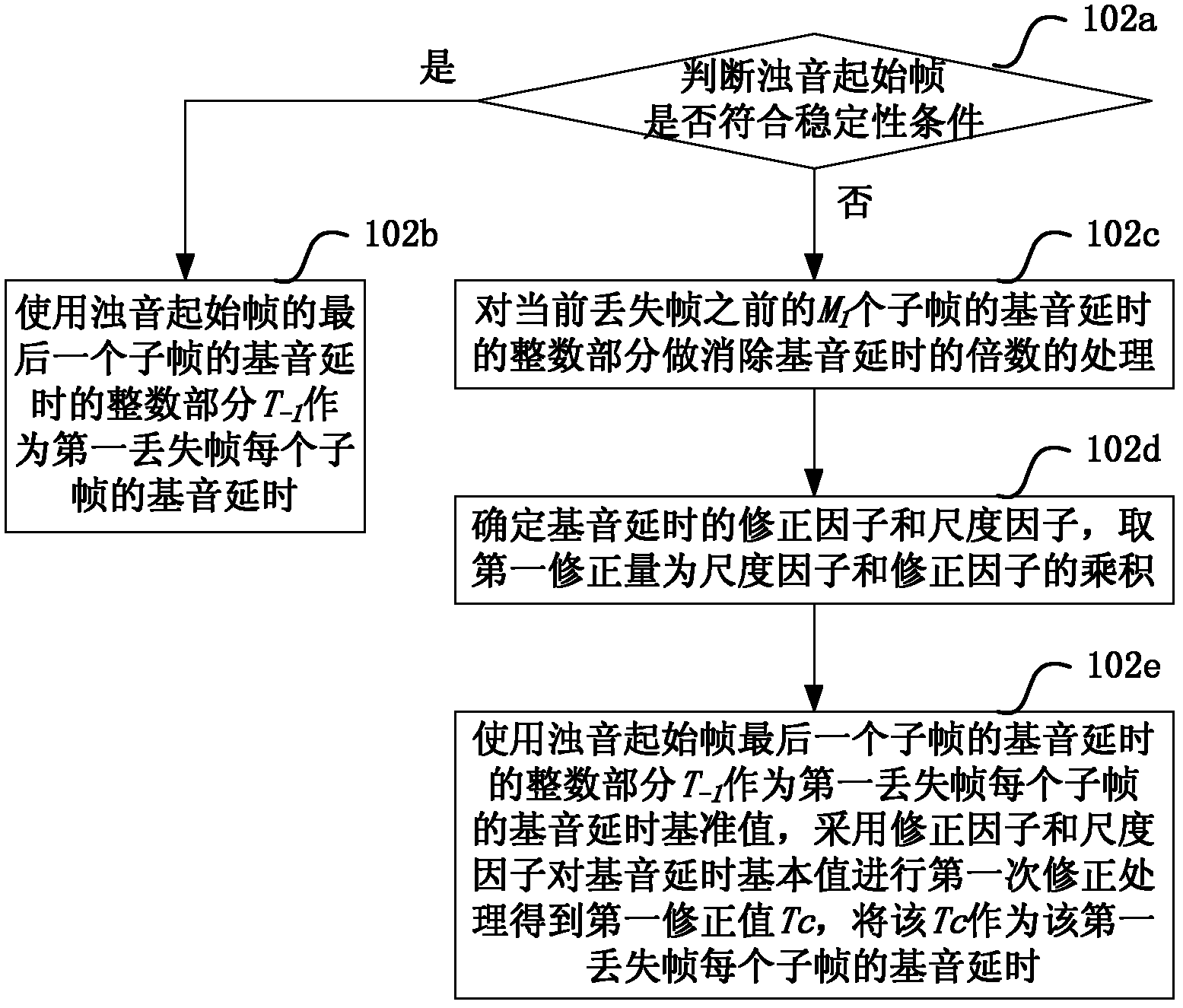
[0034] Step 102, selecting a corresponding pitch delay estimation method according to the stability condition of the voiced sound start frame to infer the pitch delay of the first lost frame;
[0035] Specifically: if the voiced sound onset frame meets the stability condition, the following pitch delay inference method is used to infer the pitch delay of the first lost frame: using the integer part of the pitch delay of the last subframe in the voiced sound onset frame (T -1 ) as the pitch delay of each subframe in the first...
Embodiment 2
[0103] This embodiment describes a method for compensating after loss of the first frame immediately after the start frame of voiced sound, and the difference from Embodiment 1 is that a second correction process is added.
[0104] Step 201 is the same as step 101 in embodiment 1;
[0105] Step 202, the main difference between this step and step 102 is that when the starting frame of voiced sound does not meet the stability condition, use the first correction amount to T -1 After making the correction, the corrected T -1 The second correction process is performed, and the result after the correction process is used as the final estimated value of the pitch delay of each subframe of the first lost frame.
[0106] Specifically, the second correction process is as follows:
[0107] Judging if the following two conditions are met, take T -1 is the median value of the pitch delay: condition 1: modified T -1 (i.e. T c =T -1 +f s *f m ) and T -1 The absolute value of the dif...
Embodiment 3
[0138] This embodiment describes a method for compensating after the loss of two or more frames immediately after the voiced sound start frame, where the lost frames include the first lost frame and one or more lost frames immediately after the first lost frame, such as Figure 4 shown, including the following steps:
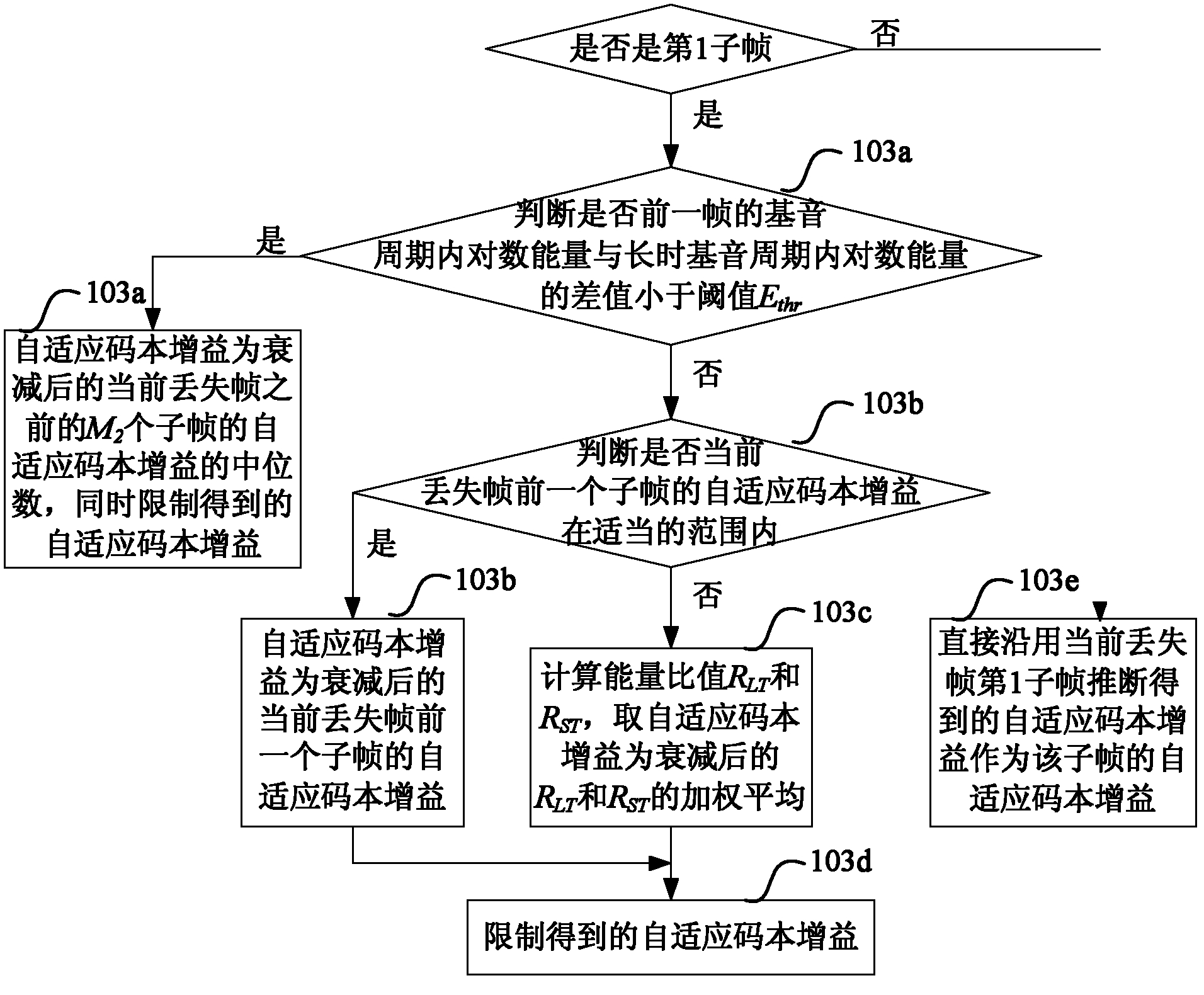
[0139] Step 301, using the method in embodiment 1 or embodiment 2 to infer the pitch delay and adaptive codebook gain of the first lost frame;
[0140] Step 302, for one or more lost frames following the first lost frame, use the pitch delay of the previous lost frame of the current lost frame as the pitch delay of the current lost frame;
[0141] Step 303, the adaptive codebook gain value obtained after attenuation and interpolation of the estimated value of the adaptive codebook gain of the last subframe of the previous lost frame of the current lost frame is used as the adaptive codebook gain value of each subframe in the current lost frame. codebook gain; ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com