Method and device for matching texts
A matching method and text technology, applied in the field of data processing, can solve problems such as large amount of data processing, affecting system performance, slow processing speed, etc., and achieve the goals of improving system performance, simple matching process, strong versatility and universal applicability Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0038] In the text matching method provided in Embodiment 1 of the present application, for each new text in each period, the similarity between each new text and each original text, and between any two new texts is calculated. That is, the similarity data related to the newly added text is determined. For example: when used in the product recommendation process, the new text is obtained based on the product information released in the current cycle. And determine all commodities matching the commodity information released in the current cycle according to the newly added text (the information includes the commodity information released before and the commodity information released in the current cycle).
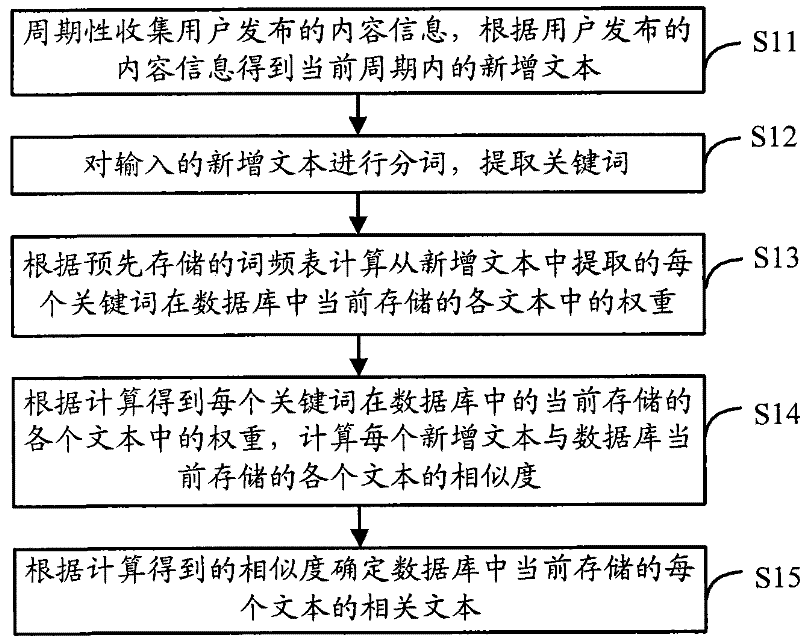
[0039] The flow of the text matching method provided in Embodiment 1 of the present application is as follows figure 2 As shown, the execution steps are as follows:
[0040] Step S11: Periodically collect content information released by users, and obtain new texts in the ...
Embodiment 2
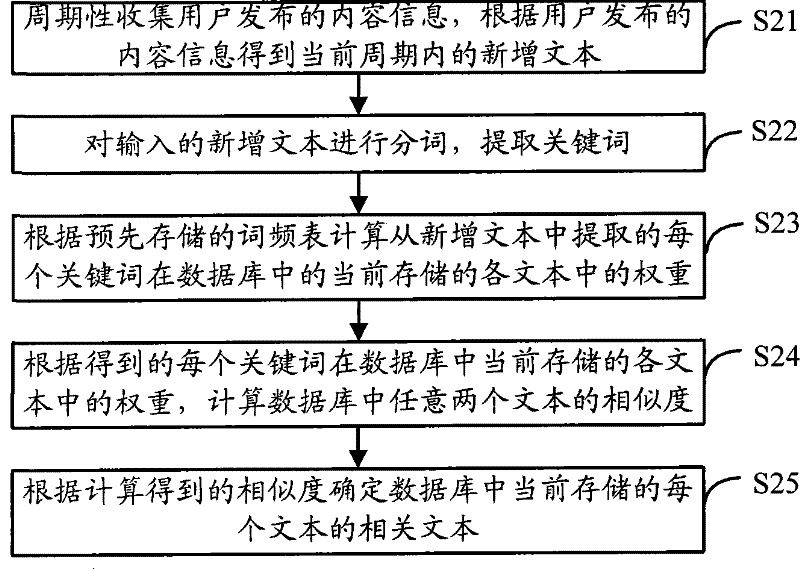
[0079] The text matching method provided in Embodiment 2 of the present application calculates the similarity between any two texts for each text stored in the data after the newly added text is input in each cycle, and its process is as follows image 3 As shown, the execution steps are as follows:
[0080] Step S21: Periodically collect content information released by users, and obtain new texts in the current cycle according to the content information released by users.
[0081] It is the same as step S11 and will not be repeated here.
[0082] Step S22: Segment the newly added text to extract keywords.
[0083] It is the same as step S12 and will not be repeated here.
[0084] Step S23: Calculate the weight of each keyword extracted from the newly added text in each text currently stored in the database according to the pre-stored word frequency table.
[0085] The same as step S13, which will not be repeated here.
[0086] Step S24: Calculate the similarity between an...
Embodiment 3
[0095] The text matching method provided in Embodiment 3 of the present application improves on the solutions of Embodiment 1 and Embodiment 2, and adds an output filtering process. Specifically include:
[0096] After step S14 of embodiment one calculates similarity and before step S15 determines relevant text, increase the step of output filtering, after step S24 of embodiment two calculates similarity and before step S25 determines relevant text, increase the process of output filtering, its flow process like Figure 4 As shown, the execution steps are as follows:
[0097] Step S31: Obtain the calculated similarity between each newly added text and each text currently stored in the database, or the calculated similarity between any two texts in the database.
[0098] For the filtering of the similarity of two texts, the similarity of different texts can be filtered according to the different requirements determined by the subsequent related texts. Therefore, for the first...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com