Bad webpage recognition method based on URL
A technology for identifying methods and webpages, applied in data exchange networks, special data processing applications, instruments, etc., can solve problems such as inability to cope with new sites, large delays, and high complexity of methods
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0066] In order to understand the present invention more clearly, the present invention will be further described in detail below in conjunction with the accompanying drawings.
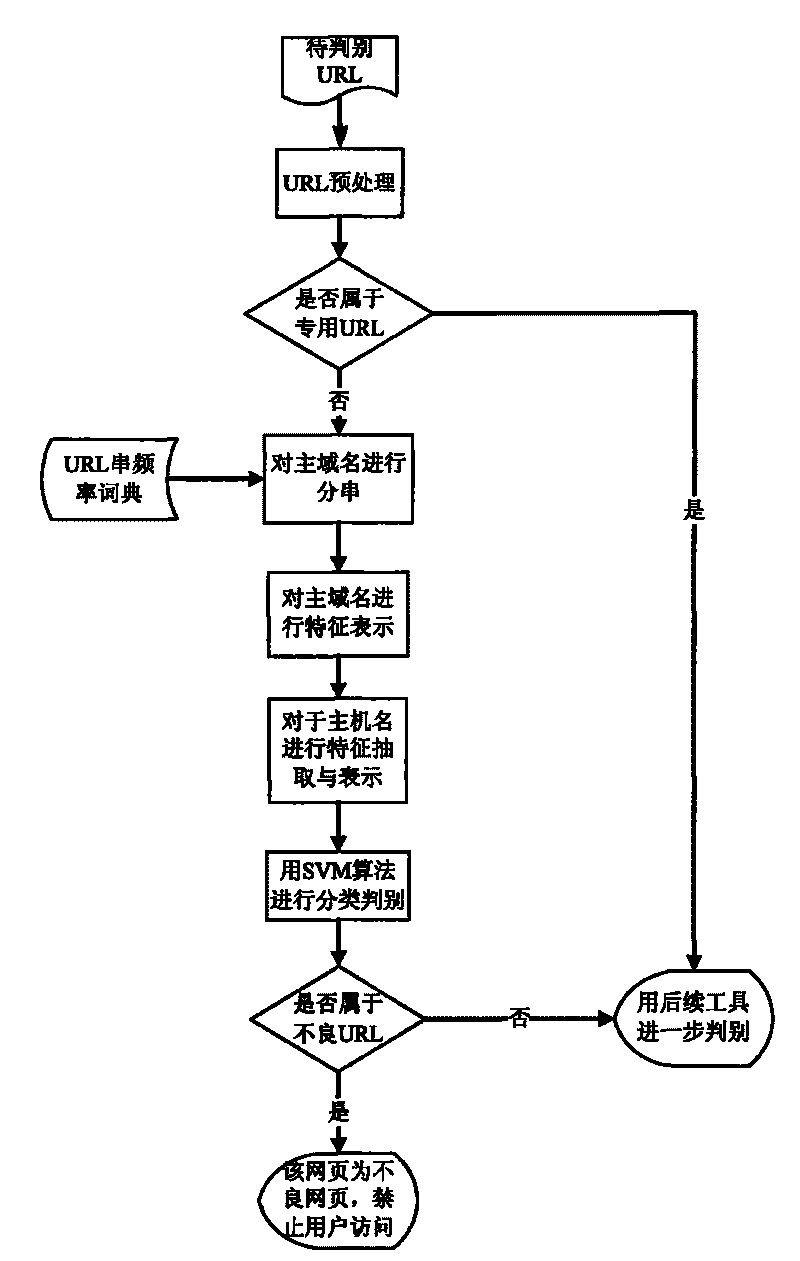
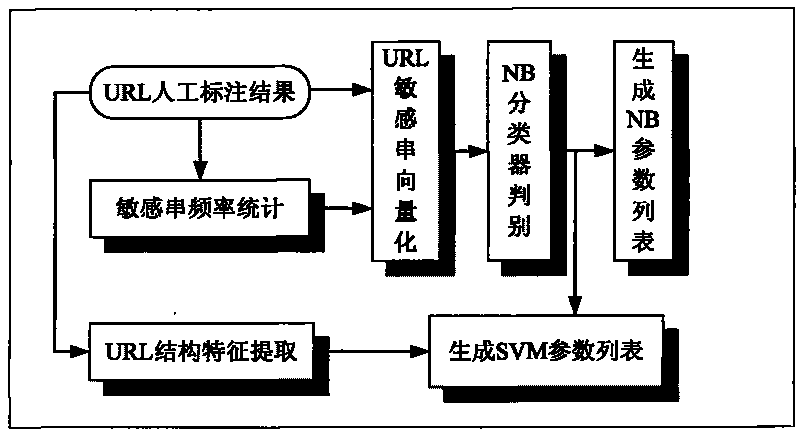
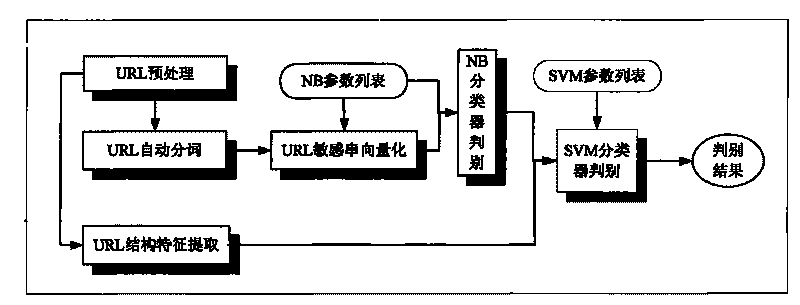
[0067] refer to figure 1 As shown, in the process of identifying URLs, the special characters are first filtered out through the preprocessing module, and the suffixes, main domain names, host names and other parts that have practical effects on the identification are extracted; Belongs to the exclusive suffix (.gov.edu): if it belongs, it will be directly judged as a normal URL, otherwise it will be judged in the next step; in the main judgment process, the domain name part is segmented and feature extraction is performed, and the host name part is Feature extraction: use the combined classifier to classify and judge the extracted results. If the result of the judgment is a normal URL, it will be further confirmed by subsequent tools. If it is bad, the user will be directly prohibited from accessing ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com