Infinite layer collection method based on Web page
A collection method and webpage technology, applied in store-and-forward switching systems, electrical components, transmission systems, etc., can solve the problems of consuming large computer resources and not being able to use multi-threading technology, so as to reduce server load and ensure accuracy easily. The effect of saving network bandwidth
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
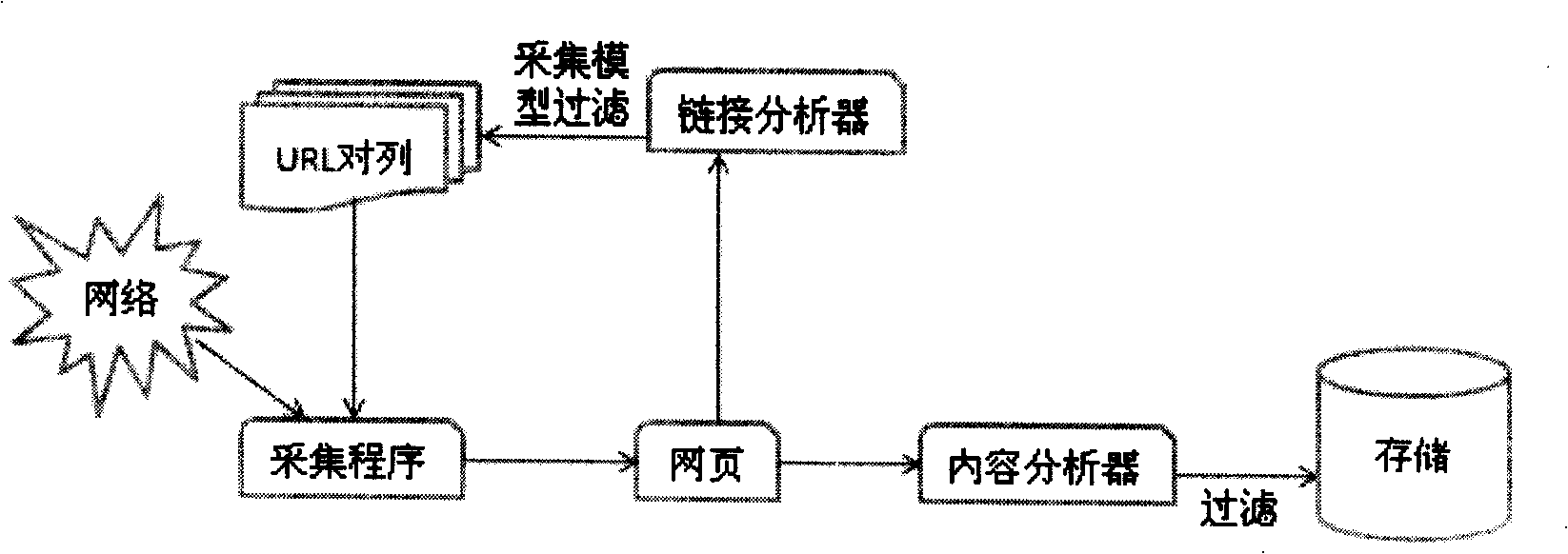
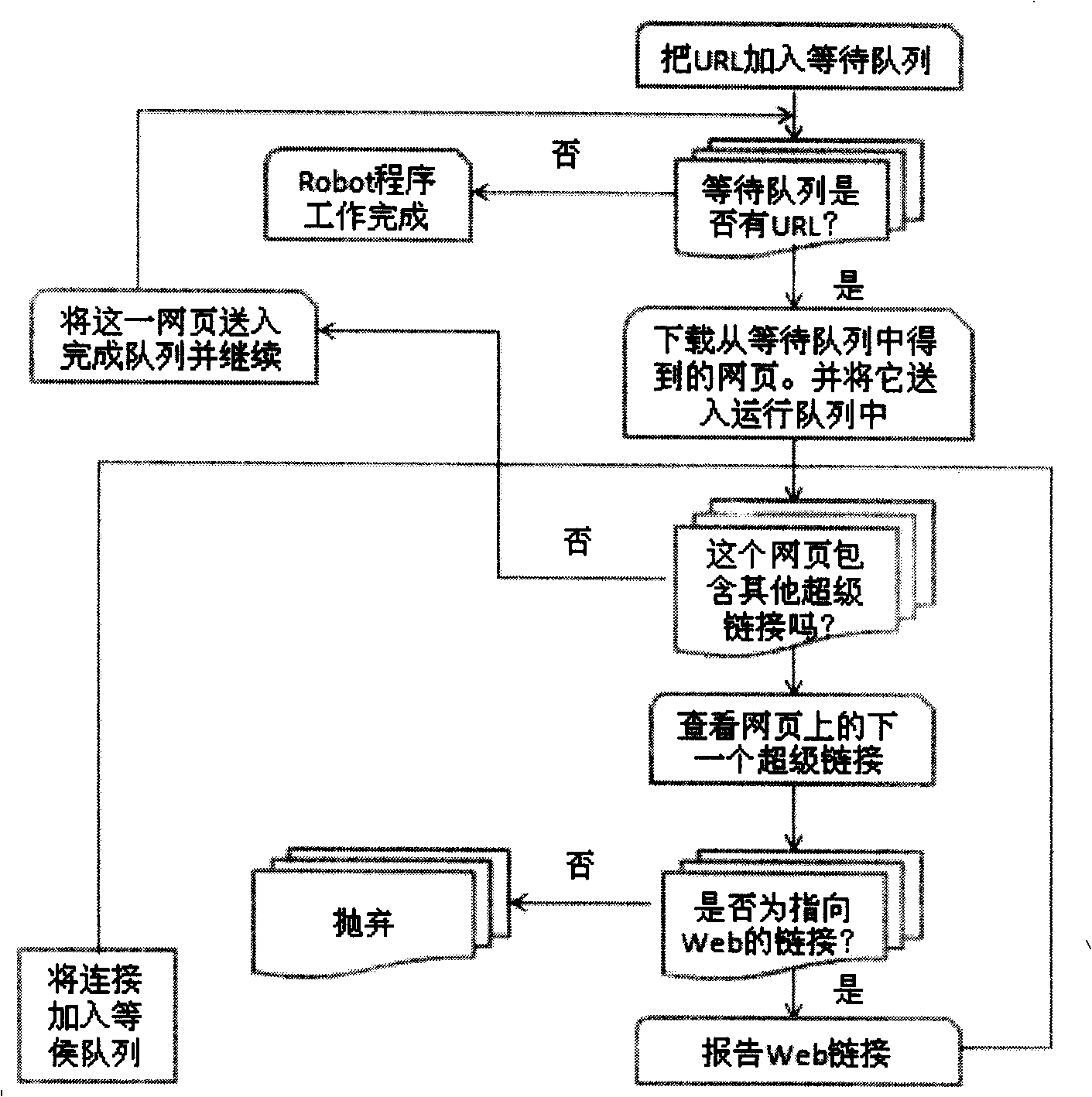
[0019] The present invention uses the entry address of the given website as the initial URL for traversal. Based on the Web page acquisition model, traverse all the links in the Web page that conform to this model, and continuously expand to the required Web pages along with the links. Distinguish the characteristics of the web pages pointed to by these links, filter the noise according to the web page acquisition model, and then perform multi-level link analysis to extract the content that users care about.
[0020] Before starting to collect network information, the website entrance address is given first, and the given website entrance address is used as the starting URL of the traversal. When the acquisition program encounters a certain webpage, it analyzes the webpage according to the acquisition model, and adds the relevant link to the link queue; at the same time, it analyzes the content of the page, and puts the webpage into the page library. Program framework such as...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com