Voice identifying system and compression method of characteristic vector set for voice identifying system
A speech recognition and feature vector technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of inability to meet actual use, a large amount of calculation, slow response speed of speech recognition system, etc., to reduce the amount of decoding calculation and storage. Quantity and the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
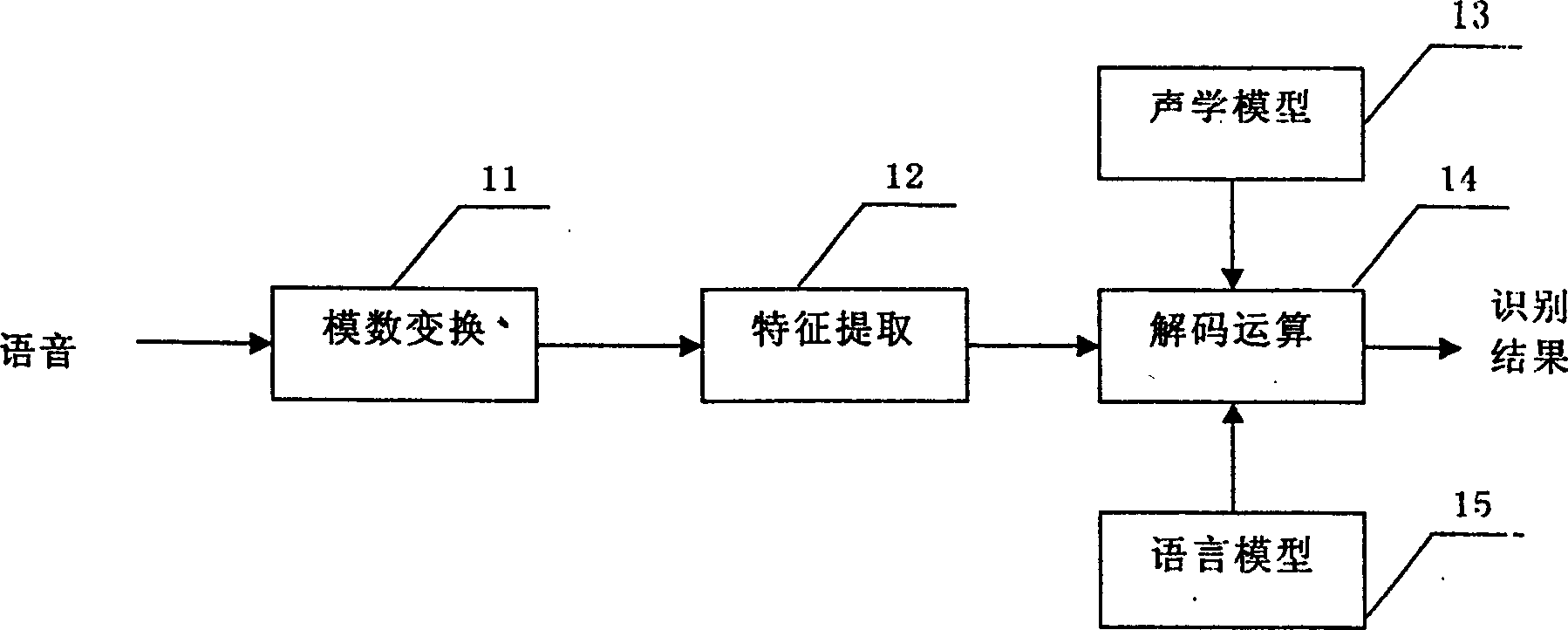
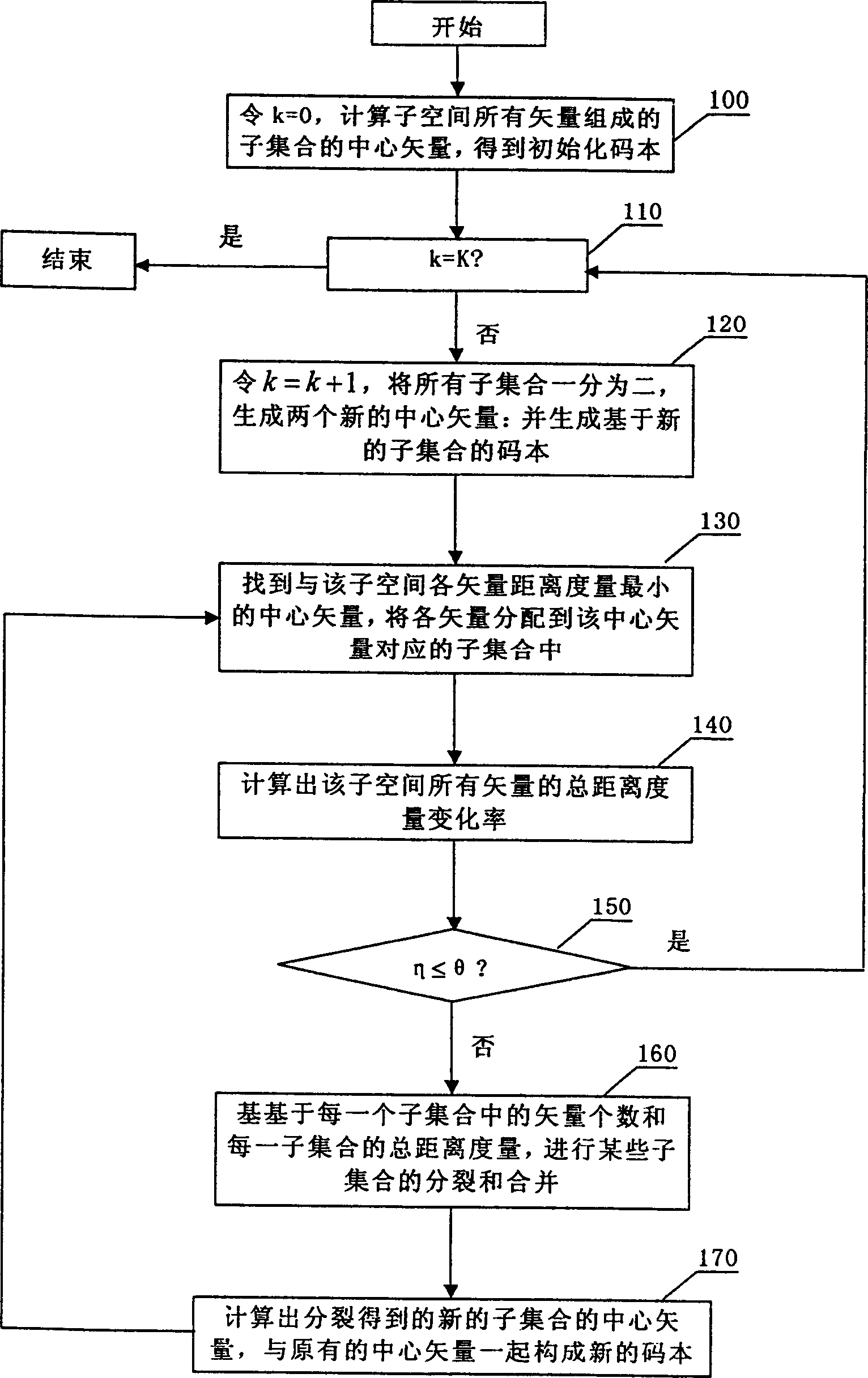
[0053] The method for compressing the feature vector set used in the speech recognition system will be described first below.
[0054] There are many kinds of speech features, such as LPC coefficients, cepstral coefficients, filter bank coefficients, Mel filter frequency coefficients (MFCC), etc. The commonly used feature parameter is MFCC. Here we don't care about which parameters, the present invention is applicable to any kind of characteristic parameters. For the convenience of understanding, the method for compressing the feature vector set of the speech recognition system according to the present invention will be described below by taking MFCC coefficients as an example.
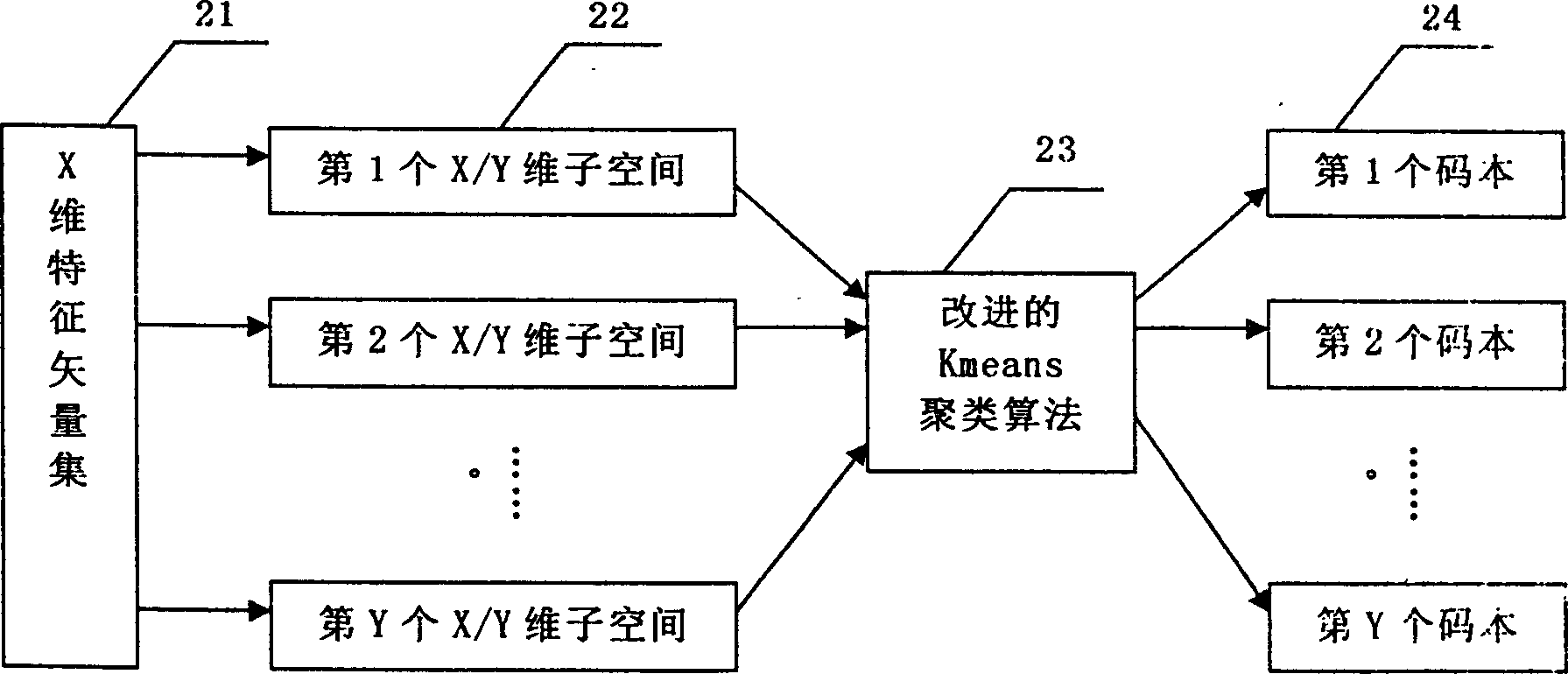
[0055] Assuming that each frame of speech uses L MFCC parameters, L first-order difference MFCC parameters and L second-order difference MFCC parameters are combined into 3*L=X dimension vectors as feature parameters, forming a speech feature set of X dimensions, correspondingly The dimension of the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com