Mixed feature data clustering method and system based on tree base learner
A technology of mixed features and data clustering, applied in machine learning, instrumentation, character and pattern recognition, etc., to achieve the effect of improving the quality of clustering
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
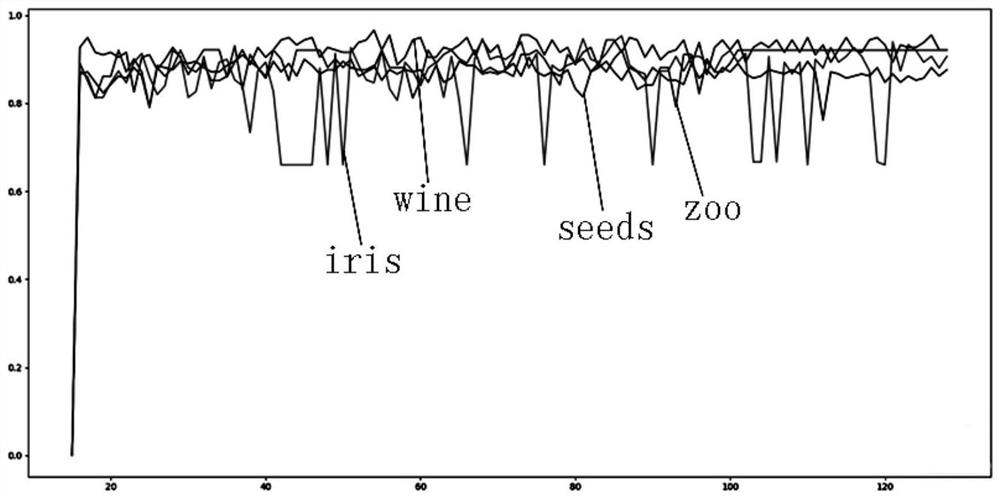
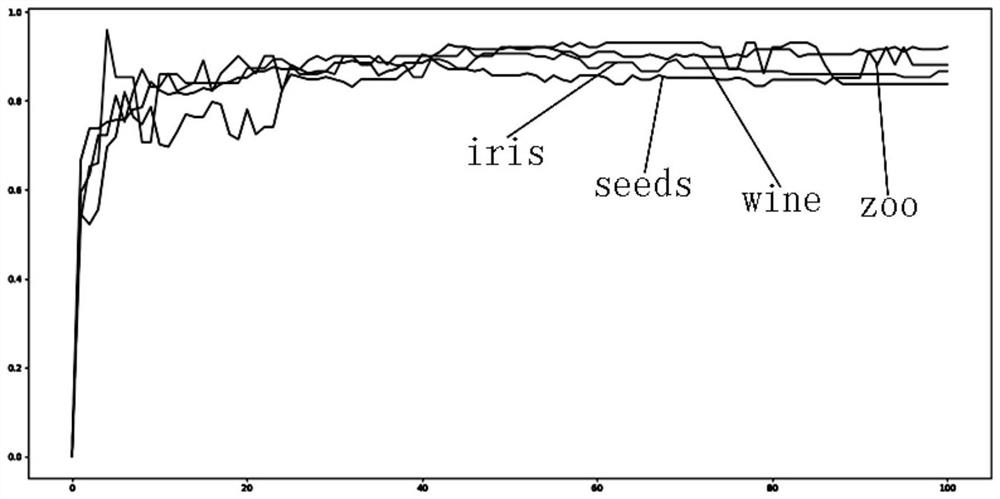
[0055] This embodiment explains the specific operation steps and verifies the effect of the solution of the present invention based on the vehicle data collected by the energy supply station. The number and type of features of the vehicle data set are shown in Table 1 below:
[0056]
[0057] Table 1 Vehicle Data Sheet
[0058] refer to figure 1 , the present embodiment provides a method for clustering mixed feature data based on a tree-based learner, comprising steps:
[0059] S1. Perform random sub-sampling on the sample set to generate N different sub-sample sets;
[0060] S2. Perform tree-based learner training on each sub-sample set, and obtain N trees and the number of clusters K after the training is completed;
[0061] S3. Based on the N trees after the training is completed, count the similarity matrices between any two samples, and normalize all the similarity matrices to obtain multiple normalized similarity matrices;
[0062] S4. The number K of clusters and ...
Embodiment 2
[0093] refer to Figure 7 , the present embodiment provides a hybrid feature data clustering system based on a dendritic base learner, including sequentially connected sub-sample set generation modules, a dendritic base learning module, a similarity matrix module, a clustering module, and a clustering module Also joins with tree-based learning modules;
[0094] A subsample set generating module, configured to perform random subsampling on the sample set to generate N different subsample sets;
[0095] The tree-based learning module is used to train the tree-based learner for each sub-sample set, and obtain N trees and the number of clusters K after the training is completed;
[0096] The similarity matrix module is used to count the similarity matrix between any two samples based on the N trees after the training is completed, and normalize all the similarity matrices to obtain multiple normalized similarity matrices;
[0097] The clustering module is used to use the number ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com