Speech enhancement model construction method and system, speech enhancement method and system
A technology of speech enhancement and construction method, applied in the field of acoustics, can solve the problems of denoising speech intelligibility and poor intelligibility, achieve accurate speech intelligibility, high definition and intelligibility, and improve the effect of enhancement effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
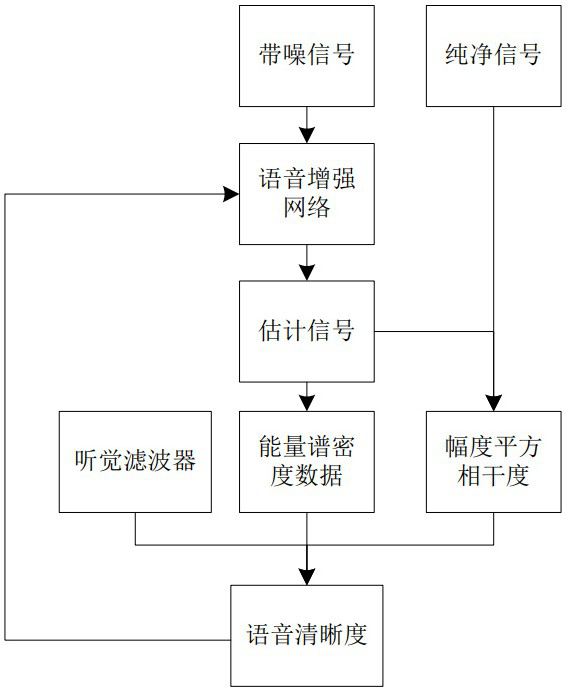
[0069] Embodiment 1, a construction method of speech enhancement model, comprises the following steps:
[0070] S100. Obtain training sample pairs, where the training sample pairs include corresponding pure speech and noisy speech;
[0071] In this embodiment, the pure speech, the noisy speech and the estimated speech all refer to the time-domain sampling point data of the corresponding audio.
[0072] The noisy speech includes real speech to be noised and synthesized speech to be noisy;
[0073] S110. Constructing a synthesized speech to be noised:
[0074] To obtain pure speech, manually adjust the noise energy based on the speech signal-to-noise ratio calculation formula to obtain synthetic noisy speech with different signal-to-noise ratios. The speech SNR calculation formula is as follows:
[0075]
[0076] Among them, t is the time domain subscript, For pure voice energy, is the noise energy, and the synthesized noisy speech is y(t), y(t) = s(t)+n(t).
[0077] S...
Embodiment 2
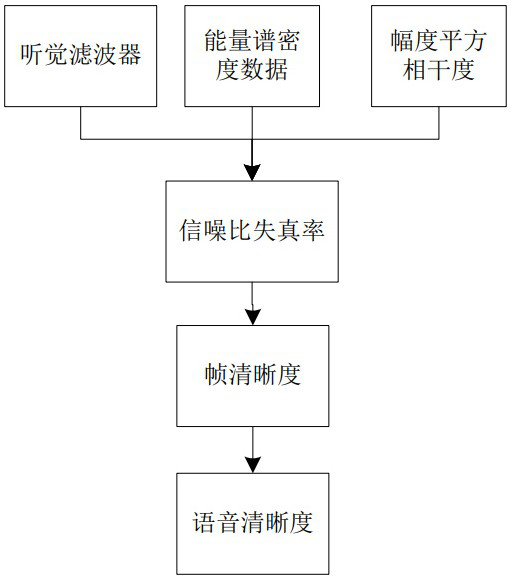
[0142] Embodiment 2, improve the scheme of calculating the speech intelligibility of estimated speech in embodiment 1, all the other are equal to embodiment 1;
[0143] refer to image 3 , step S343 is based on the specific steps of generating the speech intelligibility of the corresponding estimated speech based on each frame intelligibility as follows:
[0144] S410. Group the pure speech frames based on the sound decibel value to obtain several pure speech frame sets, and construct an estimated speech frame set corresponding to the pure speech frame sets;
[0145] Since there is a one-to-one correspondence between the pure speech frames and the estimated speech frames, the estimated speech frame set corresponding to the pure speech frame set can be constructed by extracting the estimated speech frame set corresponding to each clean speech frame in the pure speech frame set.
[0146] Specifically:
[0147] S411, grouping the pure voice frames:
[0148] The pure speech fra...
Embodiment 3
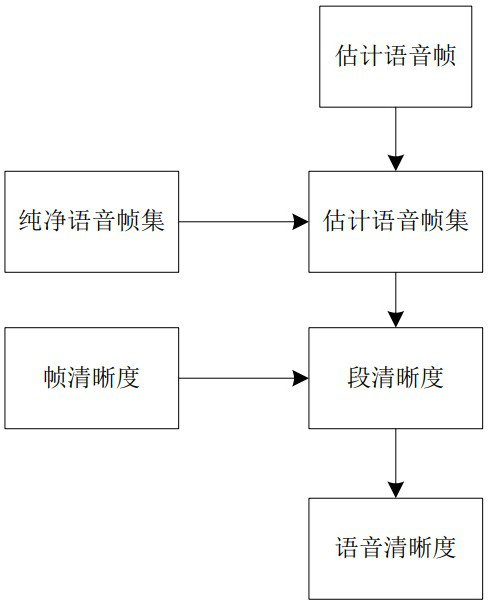
[0173] Embodiment 3, change the weight of the mid-section definition in Embodiment 2 from a fixed weight to an adaptive weight, and all the others are equal to Embodiment 2;
[0174] In this embodiment, the weighted calculation is carried out for each segment of clarity, and the calculation formula for obtaining the voice clarity of the corresponding estimated voice is:
[0175]
[0176] W high , W middle , W low is an adaptive weight, and the calculations are the same, so in this embodiment, W high The steps are illustrated with examples, refer to Figure 4 , the specific calculation steps are as follows:
[0177] ①. Calculate the short-term average amplitude of each pure speech frame, and obtain the corresponding frame amplitude data M m ,Calculated as follows:
[0178]
[0179] in, i is the subscript of the time-domain sampling point of the current frame, I is the length of one frame (number of sampling points), x m (i) is the time-domain sampling point data of...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com