A Synthetic Speech Detection Method Based on Speech Segmentation
A technology for synthesizing speech and detection methods, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of high threat degree of ASV system, and achieve the effect of improving accuracy, improving detection accuracy, and high detection accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
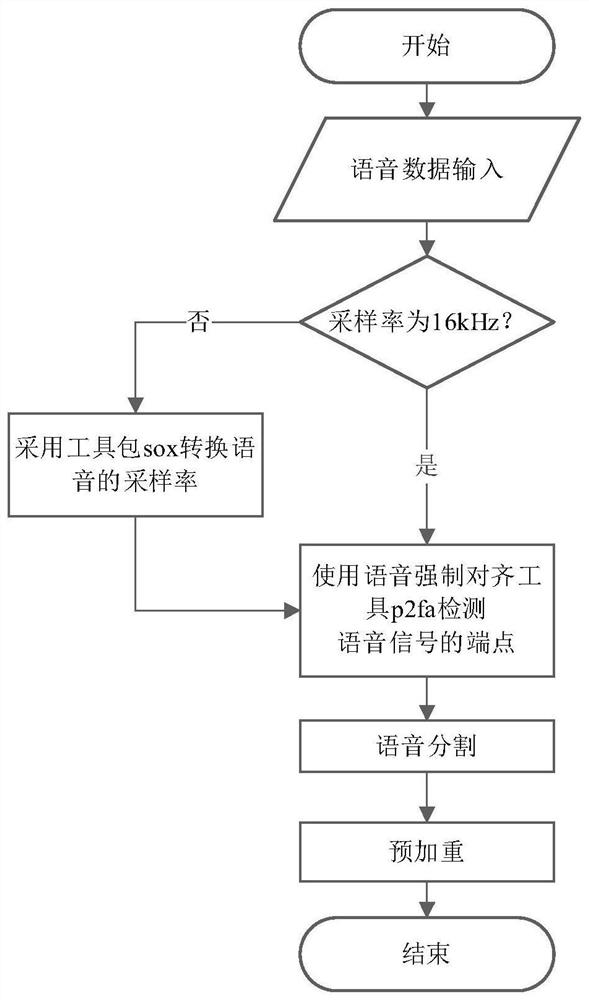
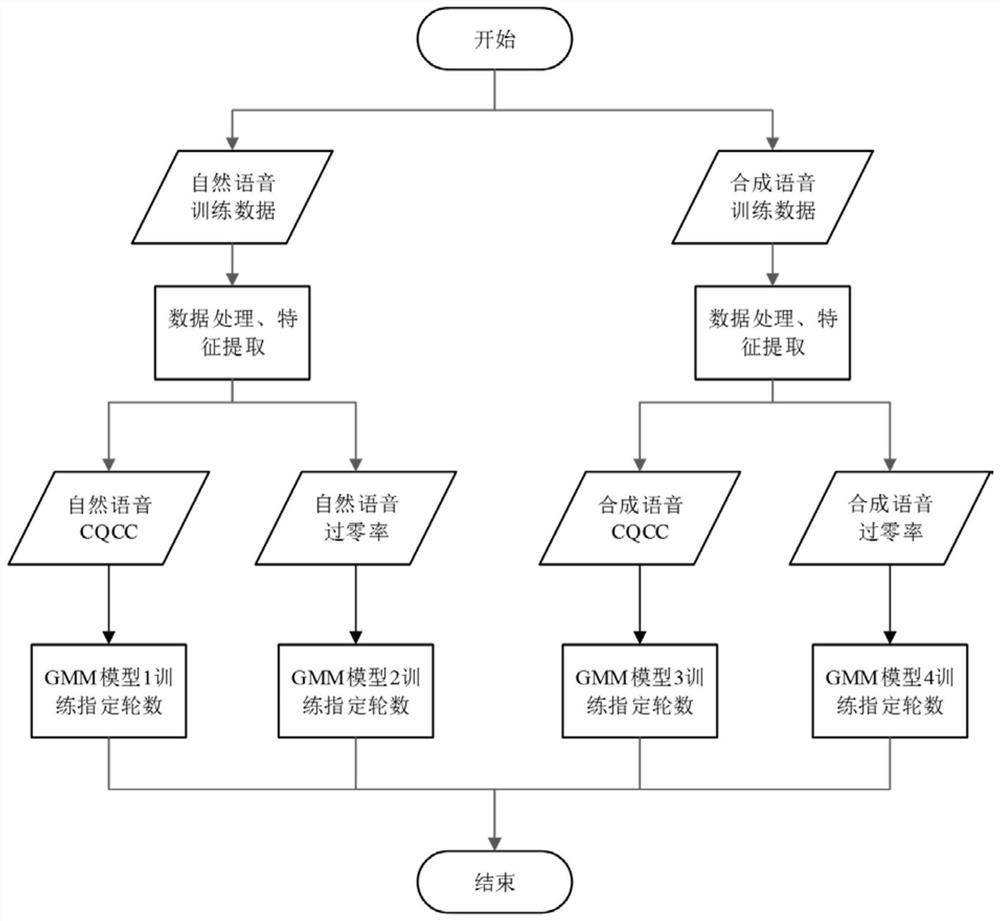
[0040] The training phase mainly includes two parts: data processing and model training.
[0043] Step A1: Obtain all training data from the training set, and check the sampling rate of speech recognition in the training set.
[0050] y
[0052] Step B2: the voice data is divided into short segments by 10ms, and there should be some overlap between each segment. speech signal in macro
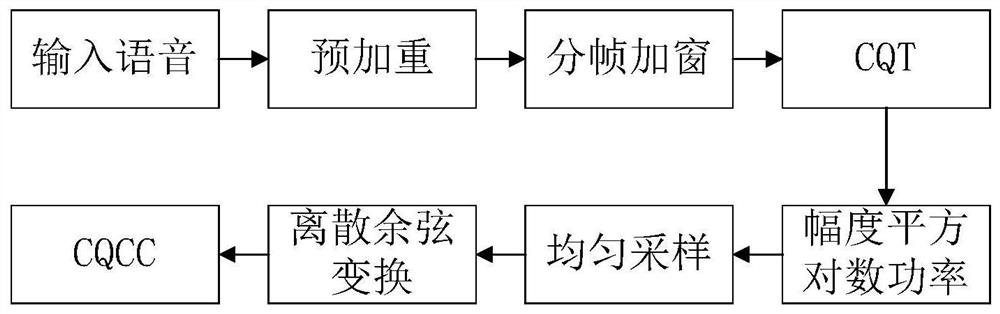
[0054]
[0063] The main purpose of the deployment stage is to put the model that has been trained on the parameters into the synthetic speech detection pusher on the device.
[0064] Use the trained model for inference detection. The inference detection is mainly divided into three parts, the data processing part, the inference part
[0065] As shown in Figure 4, the deployment stage is divided into high-precision requirement detection effect deployment and rapid detection deployment.
[0066] Step D: High-precision inference deployment stage. The detailed steps are as follows:
[0068] Step D2:...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com