


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Application of complete blood count in predicting sars-cov-2 infection
A blood cell counting and sars-cov-2 technology, applied in the biological field, can solve problems such as unpublished data reports, and achieve great value, attractiveness, and easy-to-measure effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

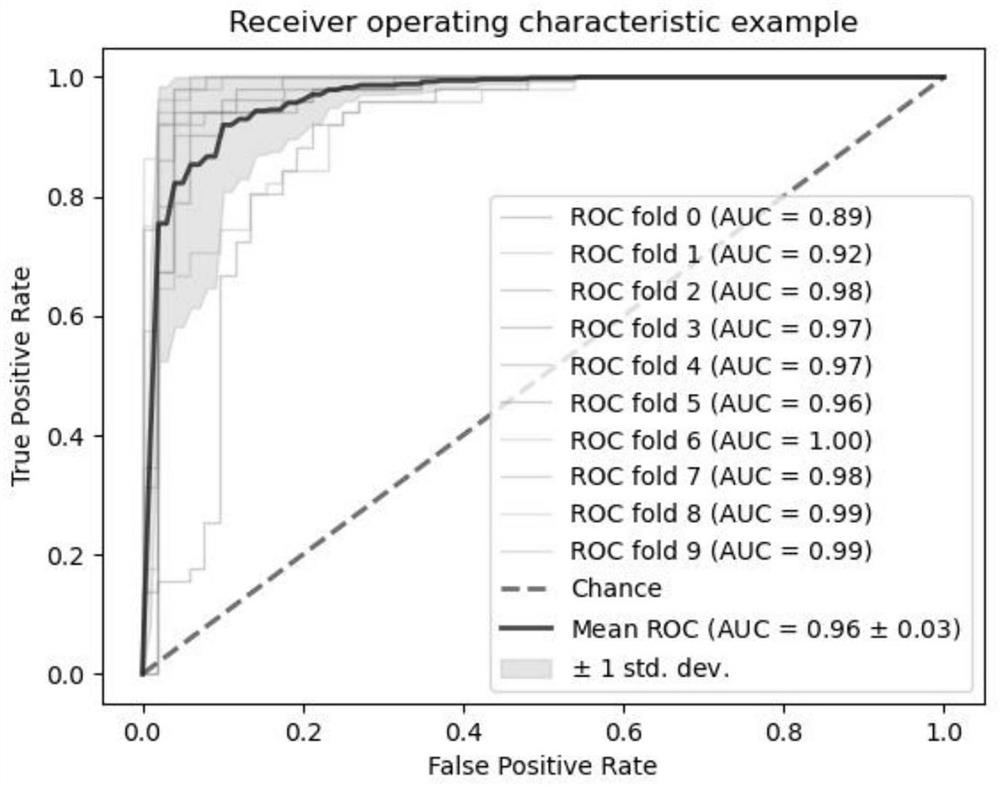
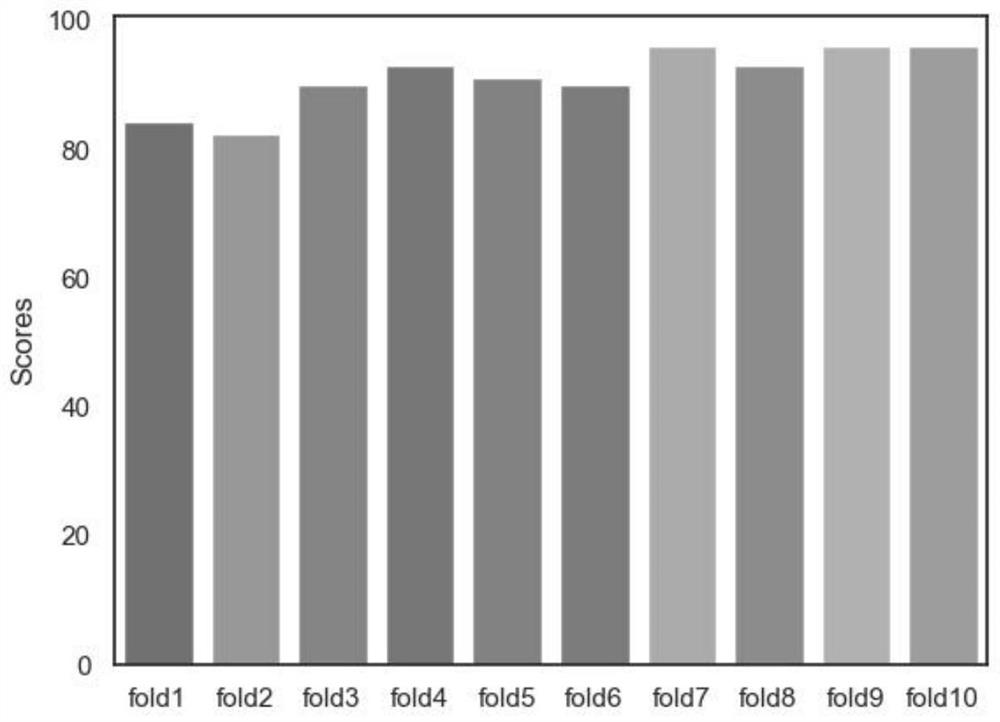
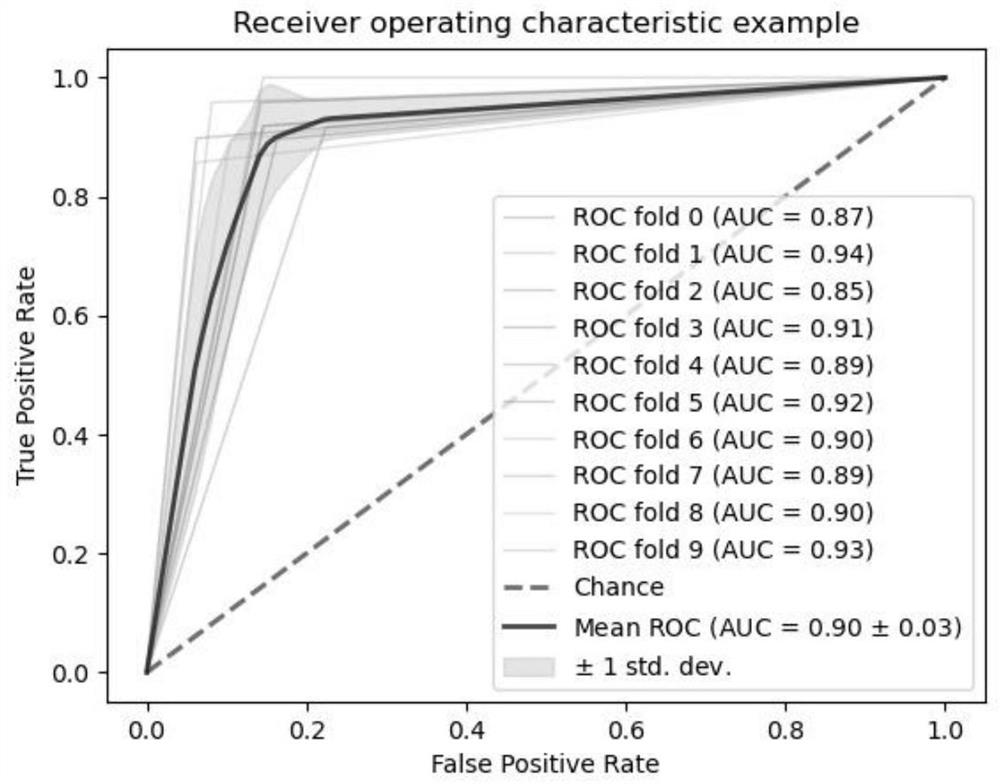
Examples
Embodiment 1
[0031] Example 1, Patient Data Set Collection
[0032] The dataset includes anonymized data from patients during hospitalization at the Iserletta Albert Einstein Hospital in São Paulo, Brazil, who have obtained samples for SARS-CoV-2 rt-PCR and other laboratory studies. All data was collected in accordance with best international practice and anonymously. All clinical details were normalized to have zero mean and unit standard deviation.
[0033] The dataset includes RtPCR SARS-CoV-2 test results and normal total blood counts: hematocrit, hemoglobin, red blood cells (RBC), lymphocytes, mean platelet volume (MPV), white blood cells, basophils, neutrophils , mean corpuscular hemoglobin (MCH), eosinophils, platelets, mean corpuscular volume (MCV), monocytes, red blood cell distribution width (RBCDW) and mean corpuscular hemoglobin concentration (MCHC). 5644 individual patients examined between March 28, 2020 and April 3, 2020 were included in the published comprehensive dataset...
Embodiment 2
[0034] Example 2, Model Definition Classification
[0035] For our SARS-CoV-2 positive and negative classification, we employ a machine learning model for comparison that applies Decision Tree, K-Nearest Neighbors (KNN), Support Vector Machines (SVM) and Naive Bayes ( Bayes) for classification. A decision tree is a supervised automatic learning technique for solving classification and regression tasks that extracts rules from a set of objects represented by various attributes in the class; KNN is the simplest instance-based supervised classification One of the learning algorithms, the classification is based on the agreement between groups of the nearest k neighbors of an unknown object; the SVM classifier is statistically dependent on the dimension of Vapnik-Chervonenkis (VC) and obeys the soft boundary assumption; based on Naive Bayes The naive Bayesian classifier is particularly well suited for high-dimensional datasets, and given its apparent simplicity, the method can ...
Embodiment 3
[0044] Example 3, K-fold cross-validation
[0045] Perform K-fold cross-validation, a resampling procedure for evaluating machine learning models on limited data samples. This process has a single parameter called k, which represents the number of groups to split a given data sample into, and the process is called k-fold cross-validation. When choosing a specific value for k, it can be used in the reference model instead of k, taking K = 10, i.e. 10-fold cross-validation.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com