Personalized speech translation method and device based on speaker features
A voice translation and speaker technology, applied in the field of voice translation, can solve the problem of not solving the speaker's characteristics and applying a personalized translation system
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

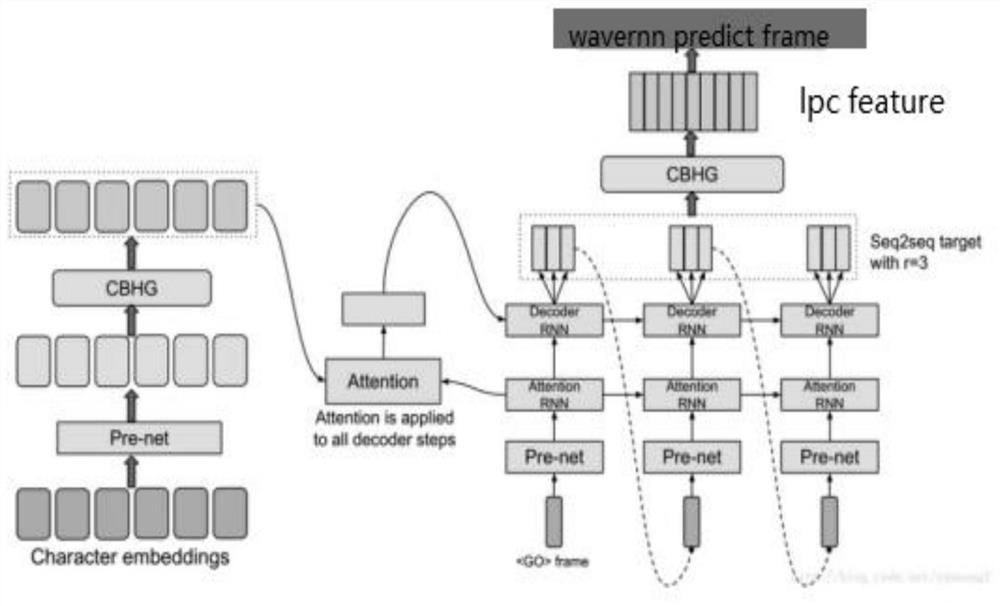
Examples
Embodiment 1
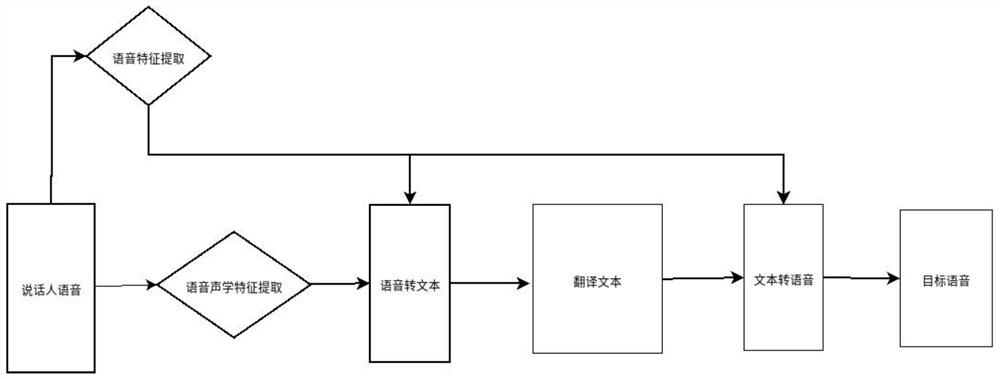
[0043] see Figure 1-3 , a method for personalized speech translation based on speaker characteristics, comprising the following steps:
[0044] Step 1, collecting the speaker's voice, extracting the speaker's voice acoustic feature, and converting it into a speaker feature vector;
[0045] The method for extracting the acoustic features of the speaker's speech is specifically to perform windowed Fourier transformation on the speaker's voice to obtain linear features, and then process the acoustic features of the speaker's speech through a Mel filter.
[0046] The speaker's speech acoustic features extracted by collecting people with different intonation features are input into the deep speech recognition model, and then trained with a deep learning network to obtain the speaker feature vector model corresponding to the speech acoustic features of different speakers.
[0047] The speaker's speech acoustic features extracted by the speaker are input into the speaker feature ve...
Embodiment 2
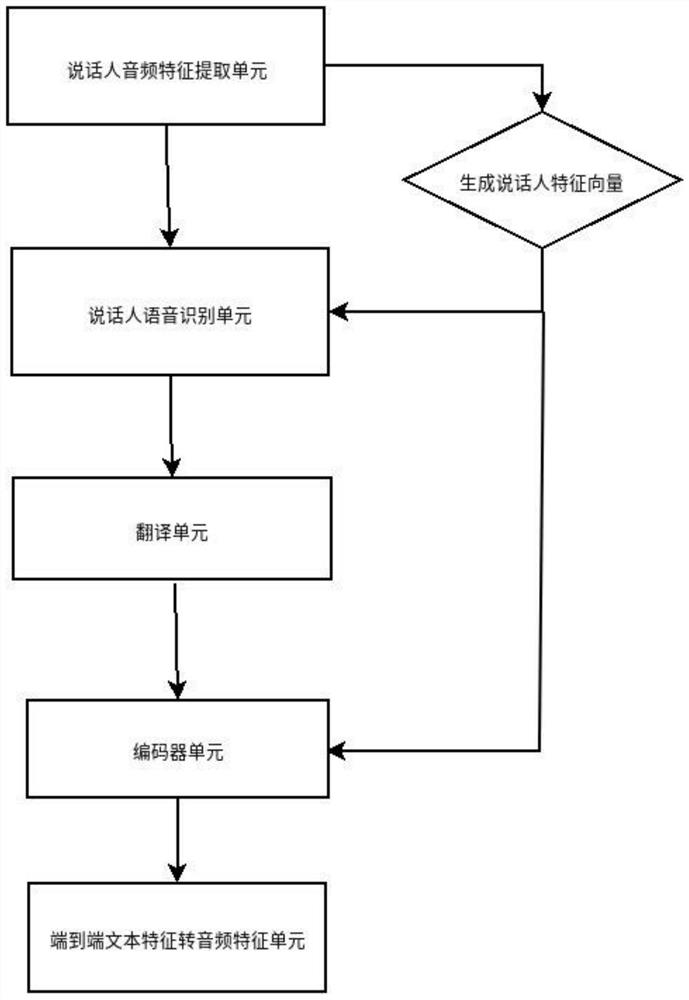
[0062] In this embodiment, a personalized speech translation device based on speaker features includes a speaker audio feature extraction unit, a speaker speech recognition unit, a translation unit, an encoder unit, and an end-to-end text feature-to-audio feature unit.
[0063] Speaker audio feature extraction unit, which performs windowed Fourier transformation on the speaker's voice to obtain linear features, and then obtains the speaker's voice acoustic features through Mel filter processing, and inputs the target voice acoustic features into the speaker feature vector model to get the speaker feature vector.
[0064] The speaker's speech recognition unit, which recognizes the speech as corresponding text according to the speaker's feature vector combined with the speaker's speech acoustic feature as the neural network input of the text recognition model.
[0065] The translation unit is used to translate the speaker's language into the target language. This unit translatio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com