Silent speech recognition method and system
A technology of speech recognition and vocal cord vibration, which is applied in character and pattern recognition, pattern recognition in signals, instruments, etc. It can solve problems such as unusable and system recognition preparation rate decline, and achieve high recognition accuracy, application fields and applications promising effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
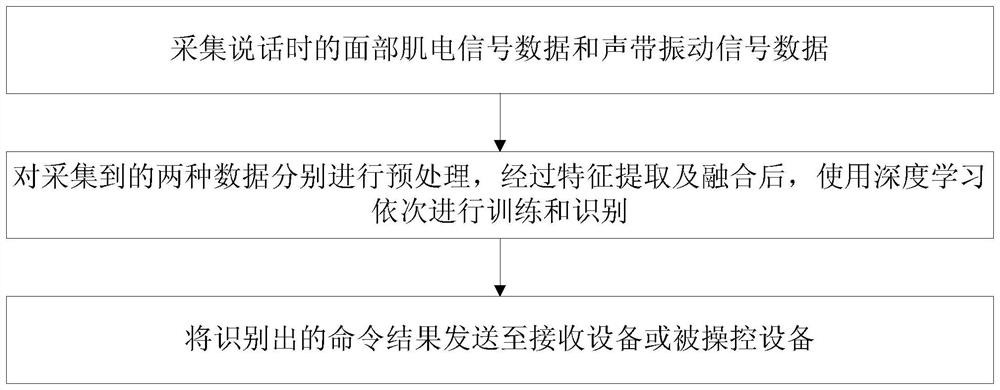
[0037] A silent speech recognition method, see figure 1 , the method includes the following steps:
[0038] 101: collecting facial electromyographic signal data and vocal cord vibration signal data when speaking;
[0039] 102: Preprocess the two collected data separately, and after feature extraction and fusion, use deep learning to perform training and recognition in sequence;
[0040] 103: Send the recognized command result to the receiving device or the controlled device.
Embodiment 2
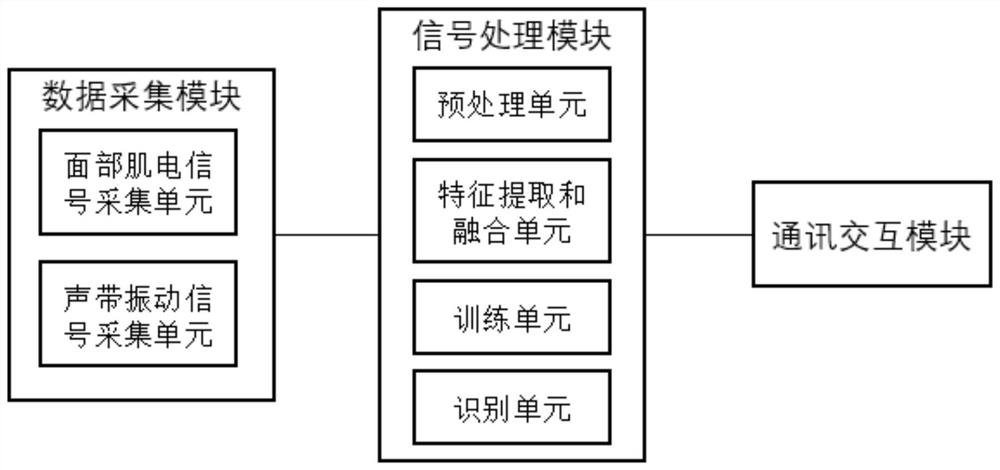
[0042] A silent speech recognition system, see figure 2 , the system mainly includes: data acquisition module, signal processing module and communication interaction module.
[0043] Among them, the data acquisition module includes two information acquisition units: a facial electromyography signal acquisition unit and a vocal cord vibration signal acquisition unit, which respectively synchronously collect electrical signal data generated by facial muscle movement and vibration signal data during vocal cord movement when speaking in a silent manner.
[0044] Further, the signal processing module includes: a preprocessing unit, a feature extraction unit and a recognition unit.
[0045] Wherein, the preprocessing unit is used for processing the facial myoelectric signal data and the vocal cord vibration signal data received by the data acquisition module. The two kinds of data signals are preprocessed, feature extracted, and feature fused, and machine learning algorithms or de...
Embodiment 3
[0054] Combine below Figure 3-Figure 5 The scheme in embodiment 2 is further introduced, see the following description for details:
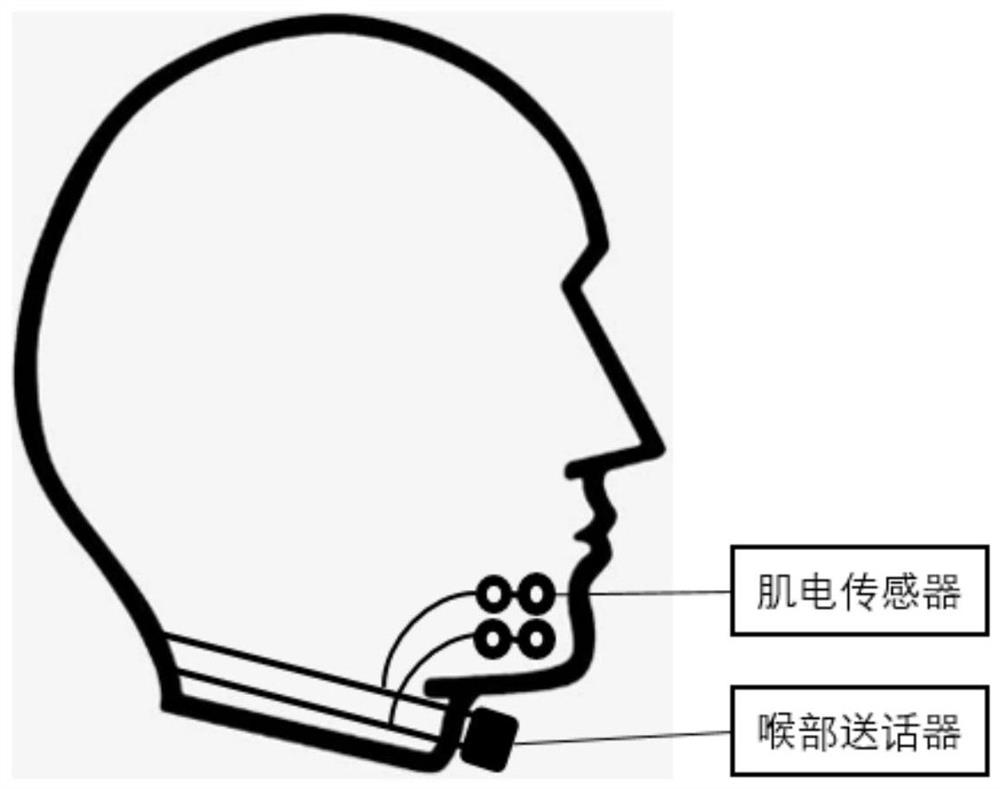
[0055] like image 3 As shown, it is a schematic diagram of the data acquisition equipment of the system, including: myoelectric sensor and throat microphone. Since the movement of facial muscles corresponds to different nerve electrical activities when people speak, the surface electrode is used as the guide electrode and placed on the On the facial skin around the mouth, the facial myoelectric signal is obtained by measuring the comprehensive potential of the muscle electrical activity at the detection electrode by close contact with the skin surface of the area where the active muscles are located. The sampling rate is 1000Hz. The collected original myoelectricity The signal is a one-dimensional signal of 4 channels. Through the laryngeal microphone close to the larynx, the vocal cord vibration of the larynx when the user speaks will cause...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com