Text data clustering method, device and equipment based on non-parametric VMF hybrid model
A hybrid model and text data technology, applied in text database clustering/classification, unstructured text data retrieval, electrical digital data processing, etc., can solve the problems that are difficult to converge, difficult to determine the convergence state, and unable to obtain analytical solutions, etc. question
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0098] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
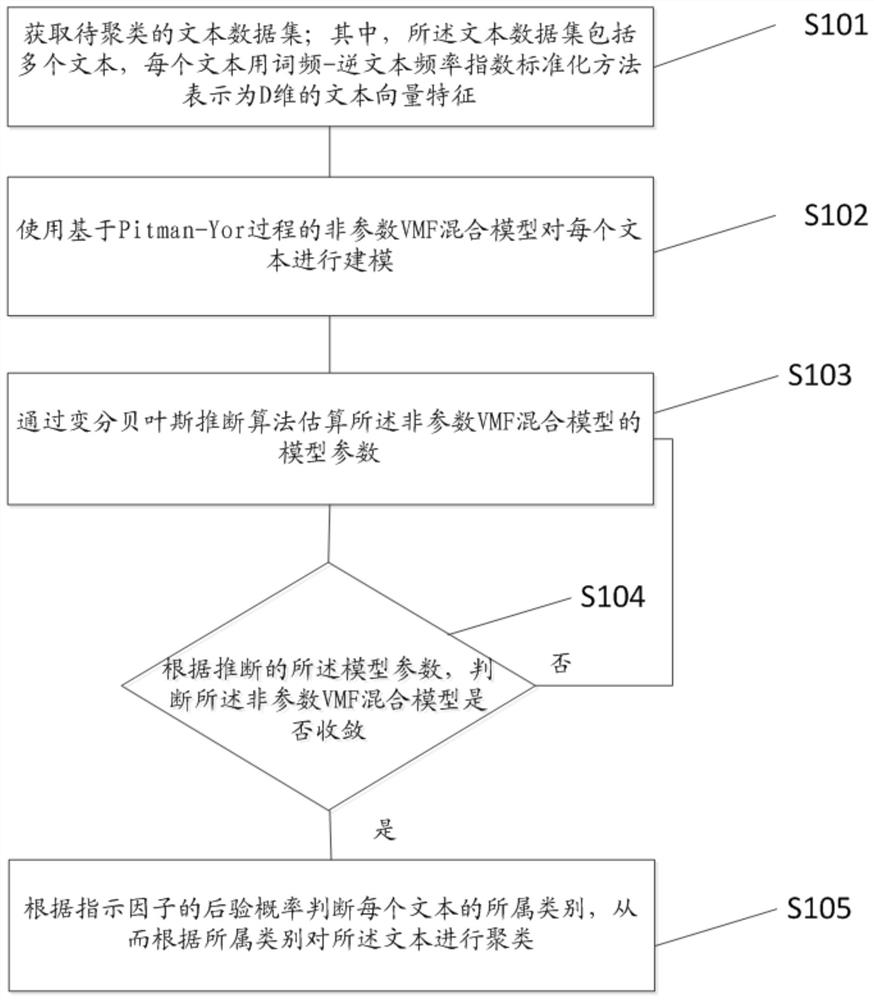
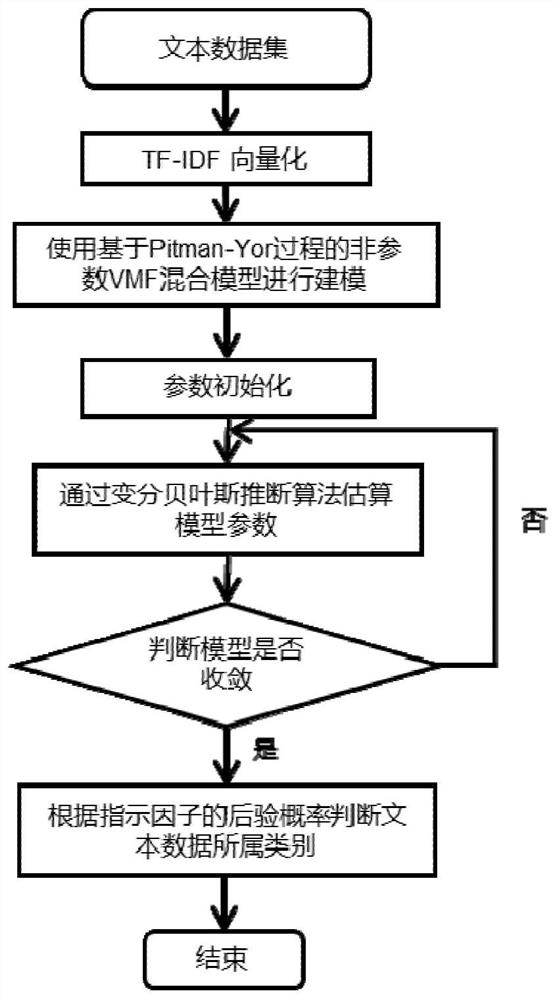
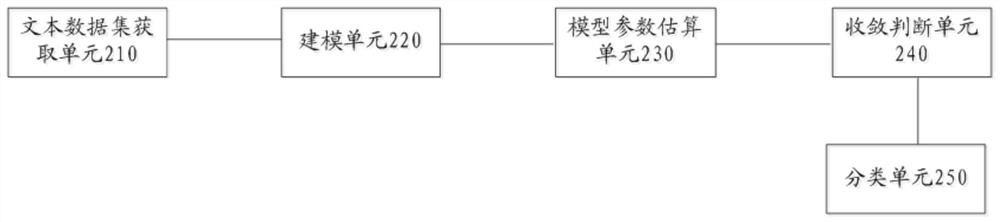
[0099] see figure 1 , the first embodiment of the present invention provides a text data clustering method based on a non-parametric VMF mixed model, which can be performed by a text data clustering device based on a non-parametric VMF mixed model (hereinafter referred to as a clustering device), and at least include:
[0100] S101. Acquire a text data set to be clustered; wherein, the text data set includes a plurality of texts, and each text is expressed as...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com