Method and system for generating video by using cross-modal characters based on dual learning
A technology for generating videos and cross-modalities, applied in the fields of electronic digital data processing, digital data information retrieval, instruments, etc., can solve the problems of unstable learning process and lack of diversity, and achieve reduced information loss and good time continuity. , the effect of stable performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0029] Embodiments of the present invention are described in detail below, examples of which are shown in the drawings, wherein the same or similar reference numerals designate the same or similar elements or elements having the same or similar functions throughout. The embodiments described below by referring to the figures are exemplary and are intended to explain the present invention and should not be construed as limiting the present invention.
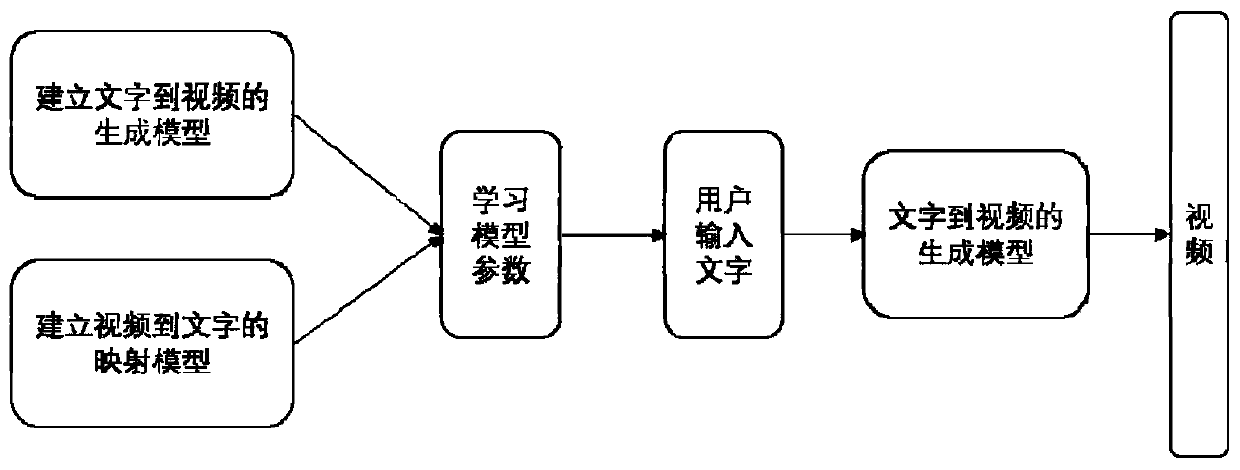
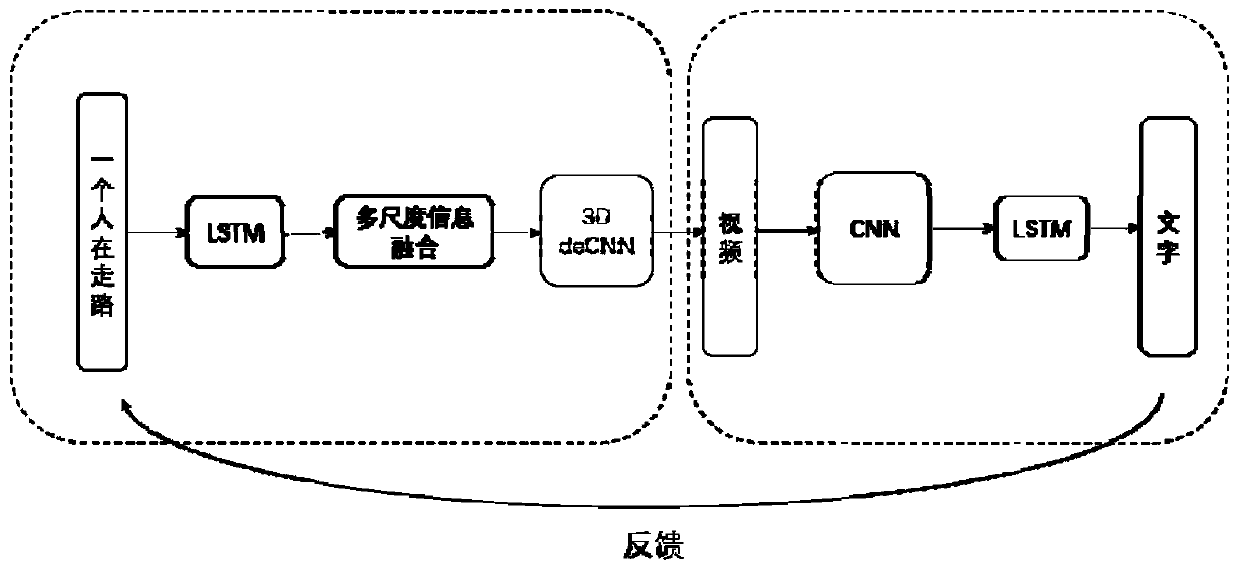
[0030] The following describes the method and system for generating videos based on dual learning based on cross-modal text according to the embodiments of the present invention with reference to the accompanying drawings. Methods.
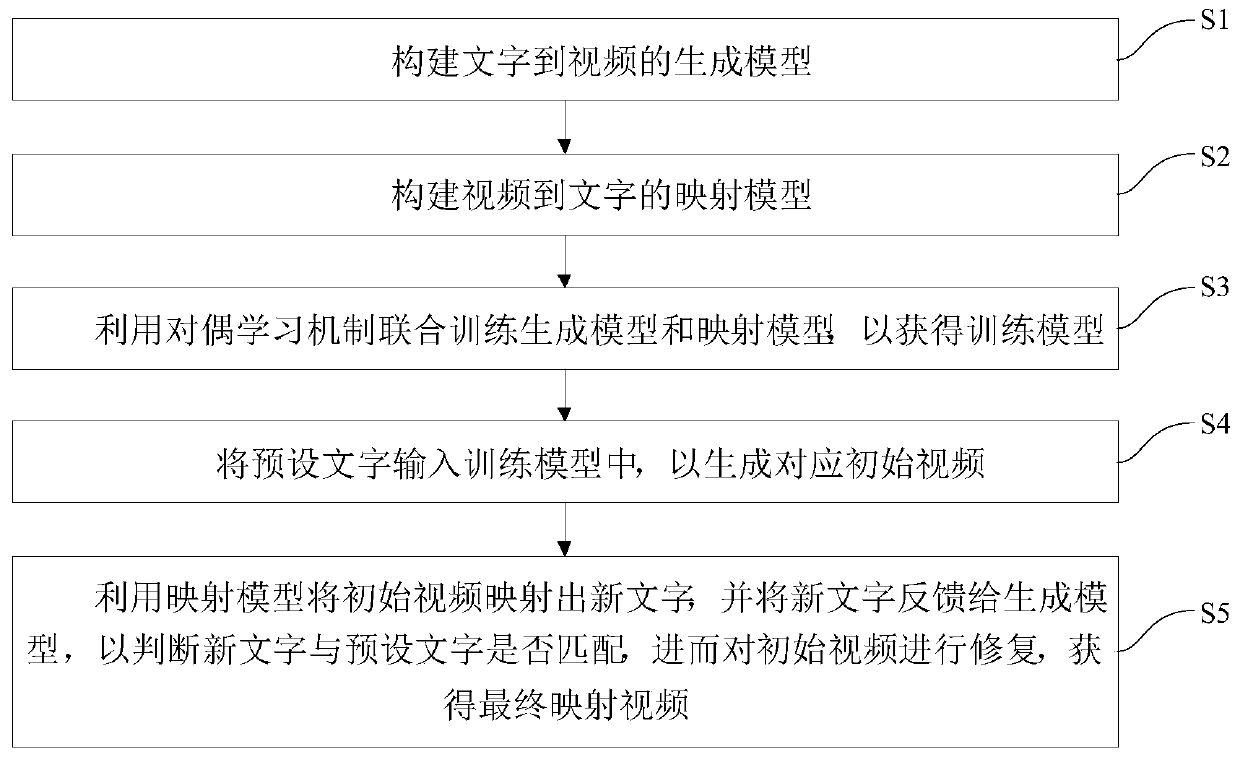
[0031] figure 1 It is a flow chart of a method for generating videos based on dual learning cross-modal text in an embodiment of the present invention.
[0032] Such as figure 1 As shown, the method for generating video based on dual learning cross-modal text includes the following steps:
[0033...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com