Distributed data crawling system, method and device, equipment and storage medium
A distributed data and distributed technology, which is applied in the direction of network data indexing, network data retrieval, and other database retrieval, etc., can solve the problems of changing job tasks, fixed job tasks, poor data crawling efficiency, etc., and achieve task volume Convenience and speed-enhancing effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
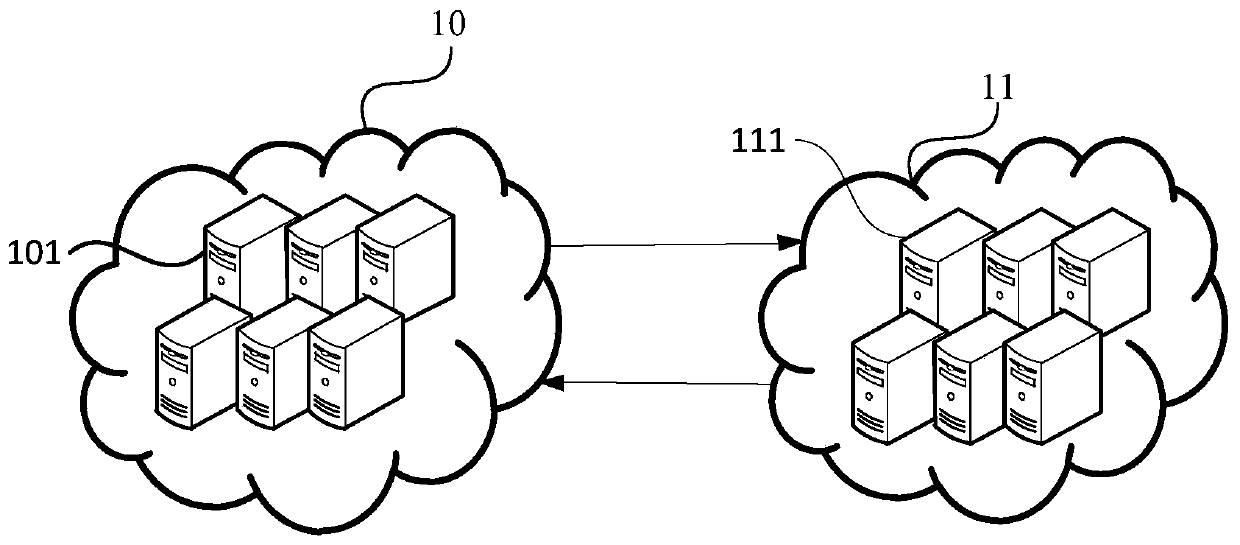
[0039] figure 1 It is a schematic diagram of the architecture of a distributed data crawling system provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation of network data crawling. See figure 1 , the system may include a task queue cluster 10 and a data crawling cluster 11;
[0040] Wherein, the task queue cluster 10 includes at least one terminal 101, an initial task queue and an intermediate task queue are arranged in the task queue cluster 10, and the initial task queue and the intermediate task queue are respectively used to save the initial crawling address and an intermediate crawling address; the data crawling cluster 11 includes at least one terminal 111 for accessing the task queue cluster 10 to obtain an initial crawling address and an intermediate crawling address, and according to the initial crawling address and The intermediate crawl address crawls the target webpage.
[0041] In the embodiment of the present invention...
Embodiment 2
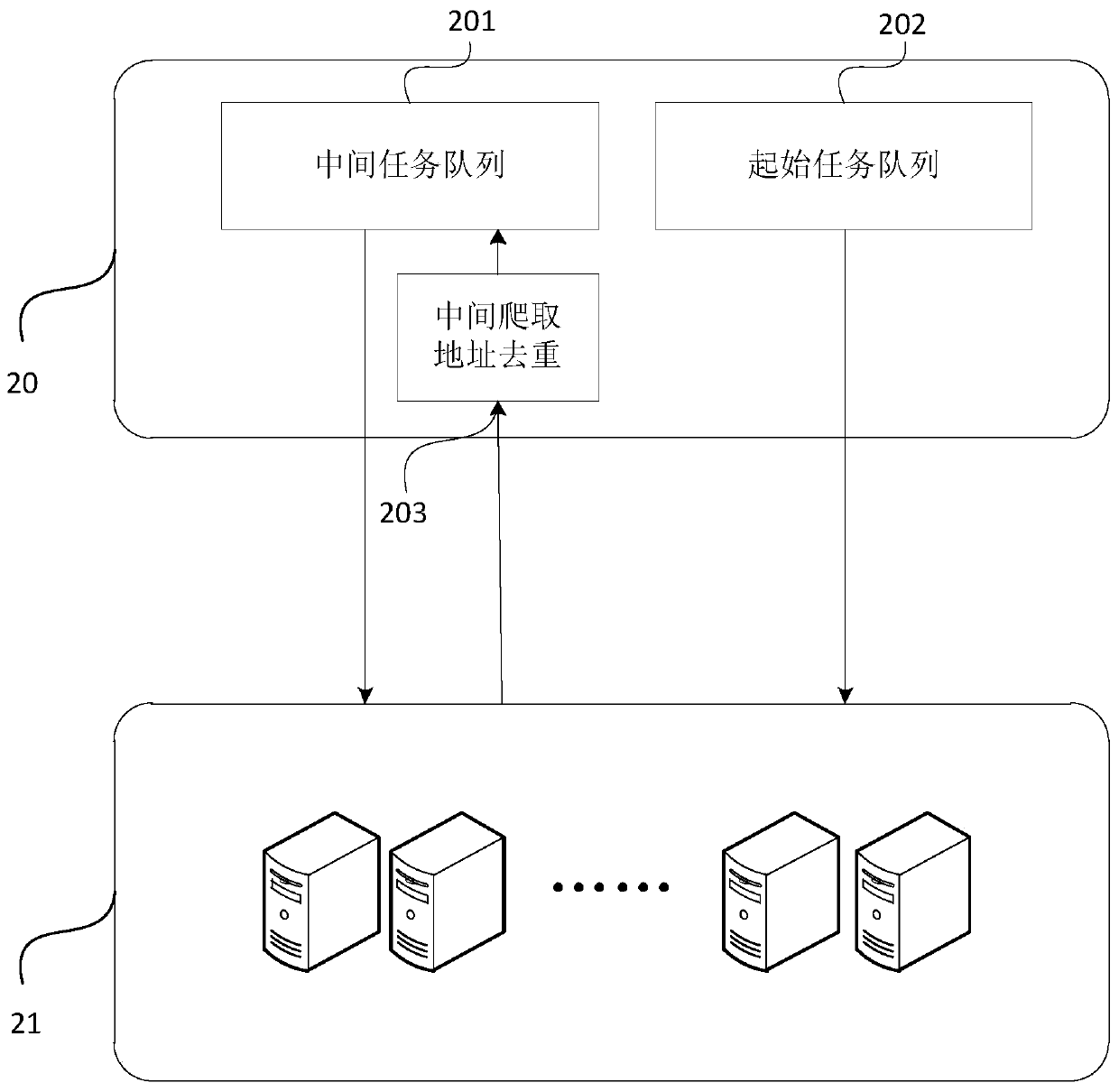
[0046] figure 2 It is a schematic diagram of the architecture of a distributed data crawling system provided by Embodiment 2 of the present invention. This embodiment is embodied on the basis of the above-mentioned embodiments of the invention. See figure 2, the distributed data crawling system provided by the embodiment of the present invention includes: a task queue cluster 20 and a data crawl cluster 21, wherein the task queue cluster 20 includes at least one terminal, and the task queue cluster 20 is provided with an initial task Queue 202 and intermediate task queue 201, the initial task queue 202 and intermediate task queue 201 are respectively used to save the initial crawling address and the intermediate crawling address; the data crawling cluster 21 includes at least one terminal for accessing all The above task queue cluster is used to obtain the initial crawling address and the intermediate crawling address, and the target webpage is crawled according to the initi...
Embodiment 3
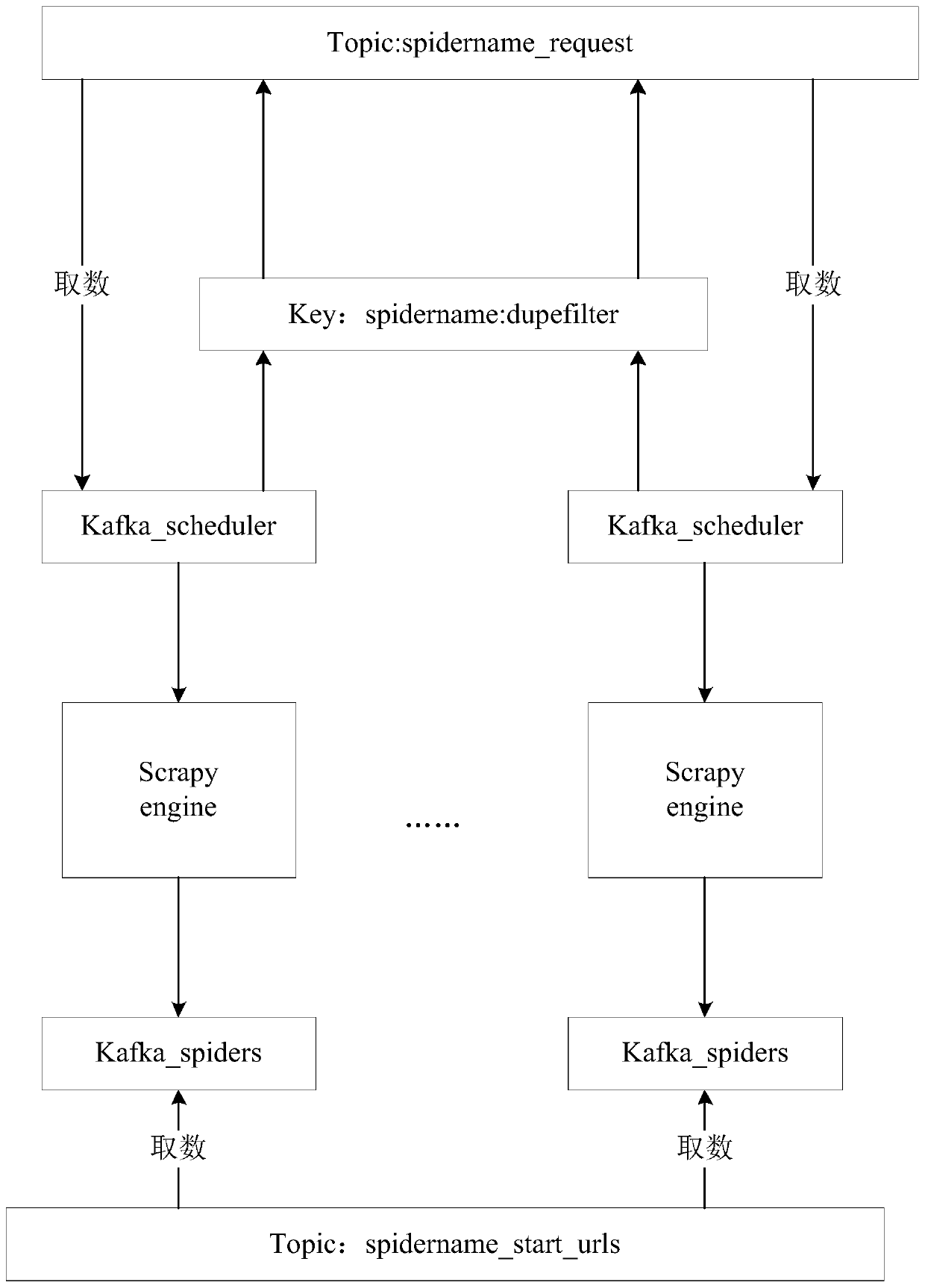
[0053] Figure 4 It is a flow chart of the steps of a distributed data crawling method provided by Embodiment 3 of the present invention. This embodiment is applicable to the data crawling cluster of a distributed crawler system, and the data crawling cluster can be composed of multiple terminals. , the method can be executed by the distributed data crawling device in the embodiment of the present invention, and the device can be realized by means of software and / or hardware. The method in the embodiment of the present invention specifically includes the following steps:
[0054] Step 301, when detecting that the initial task queue and / or the intermediate task queue set by the task queue cluster has a crawling address, access the task queue cluster to obtain the crawling address.
[0055] Wherein, the initial task queue may be a queue for storing initial tasks, and terminals in the data crawling cluster may start crawling network data according to crawling addresses in the ini...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com