A Method of Error Detection and Proofreading of Text Shapes and Near Characters
It is a kind of near-character and error detection technology, which is applied in the fields of electrical digital data processing, instruments, calculations, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

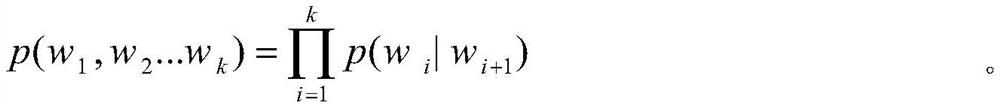
Examples
Embodiment 1
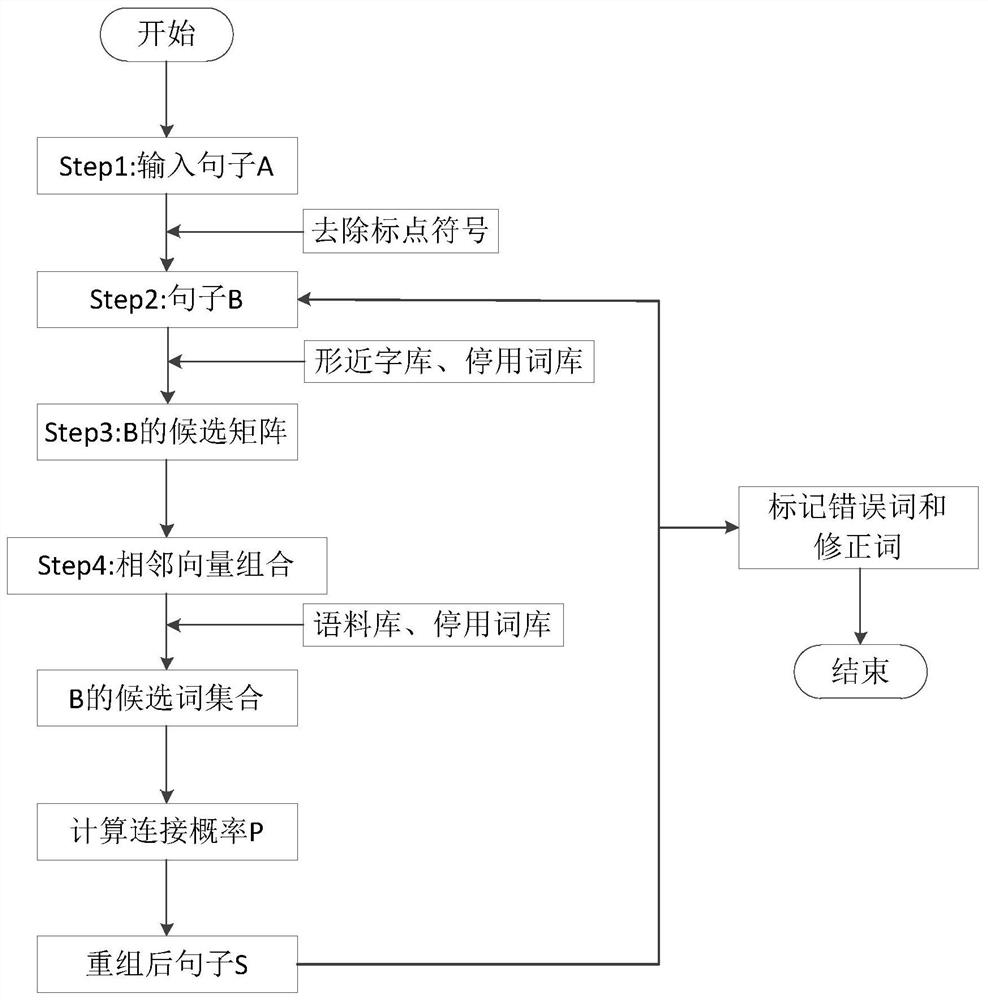
[0028] Embodiment 1: as Figure 1-2 As shown, a kind of error detection and proofreading method of text shape near word, concrete steps are as follows:
[0029] Step0.1. Create a database, which includes font library X, corpus Y, commonly used font library Q, and disabled thesaurus T.
[0030] Step1, select the sample sentence A to be processed, such as 'I am a Tai student. '.
[0031] Step2, the sentence A is preprocessed, the punctuation marks in the sentence are removed, and a new character string is obtained, B='I am a Tai student' and n is the length of the character string B.
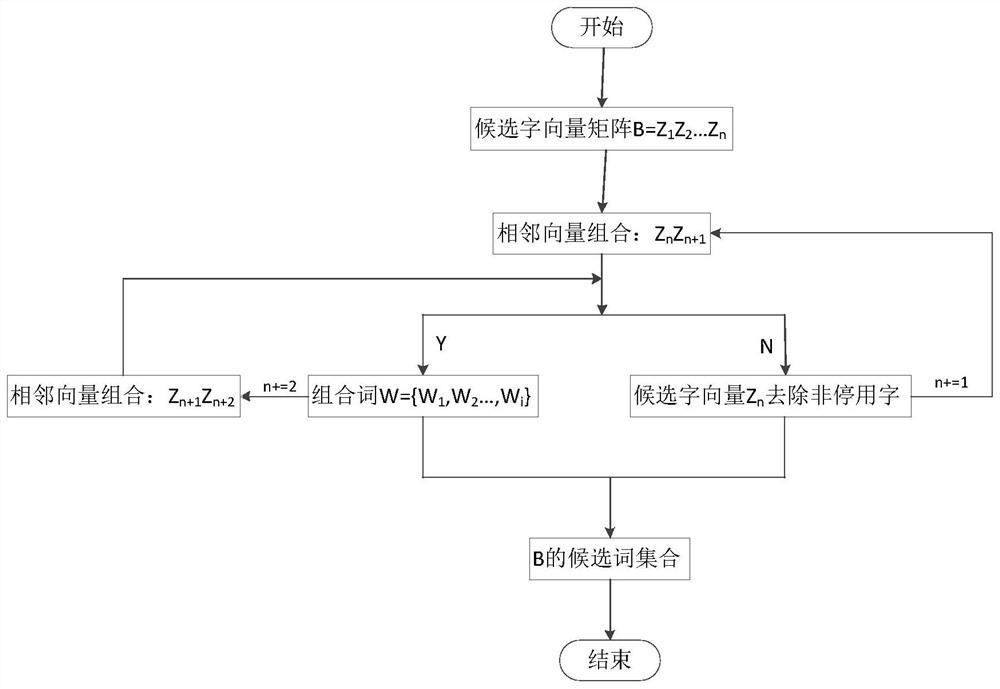
[0032] Step3, with each word in B='I am a student of Tai', in the shape near character library X, find out the similar shape near word {c n1 ,c n2 ... c nm} as c n Candidate word, with c n The degree of similarity decreases from left to right, we temporarily take m=3, that is, with c n The first three similar characters with the highest similarity, for example, the similar characters of 'I...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com