Rapid text clustering method on large corpus
A text clustering and corpus technology, applied in the field of relational databases, can solve problems such as large documents, unsatisfactory convergence speed, and sparseness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

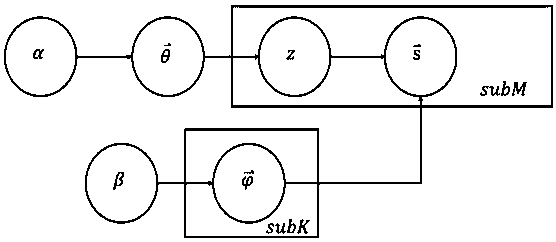


Examples
Embodiment Construction
[0038] For the convenience of description, we refer to the fast text clustering method with index optimization as IGSDMM in the following.
[0039] Two data sets will be taken as examples to introduce the advantages of the present invention over existing clustering algorithms. The introduction of the dataset is as follows:
[0040] NG20. The dataset contains 18,846 documents from 20 mainstream western newsgroups. This is a classic way to measure text clustering algorithms. The average length of documents in NG20 is 137.85, and the average number of words is 91.
[0041] Tweets. The dataset consists of 2472 tweets and is associated with 89 queries. The relationship between tweets and queries is annotated by humans. The average length of tweets is 8.56, and the average number of words is 7.
[0042] Normalized mutual information (NMI) is widely used to measure the quality of clustering results. NMI measures the statistics shared between random variables representing clus...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com