Massive Network Data Search Method Based on Data Flow Structure
A network data and data flow technology, applied in text database indexing, electronic digital data processing, digital data information retrieval, etc., can solve the problems of large storage space occupied by information summaries, small storage space of index structure, high probability of query errors, etc. , to achieve the effects of fast index matching search, high query efficiency, and fast processing speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
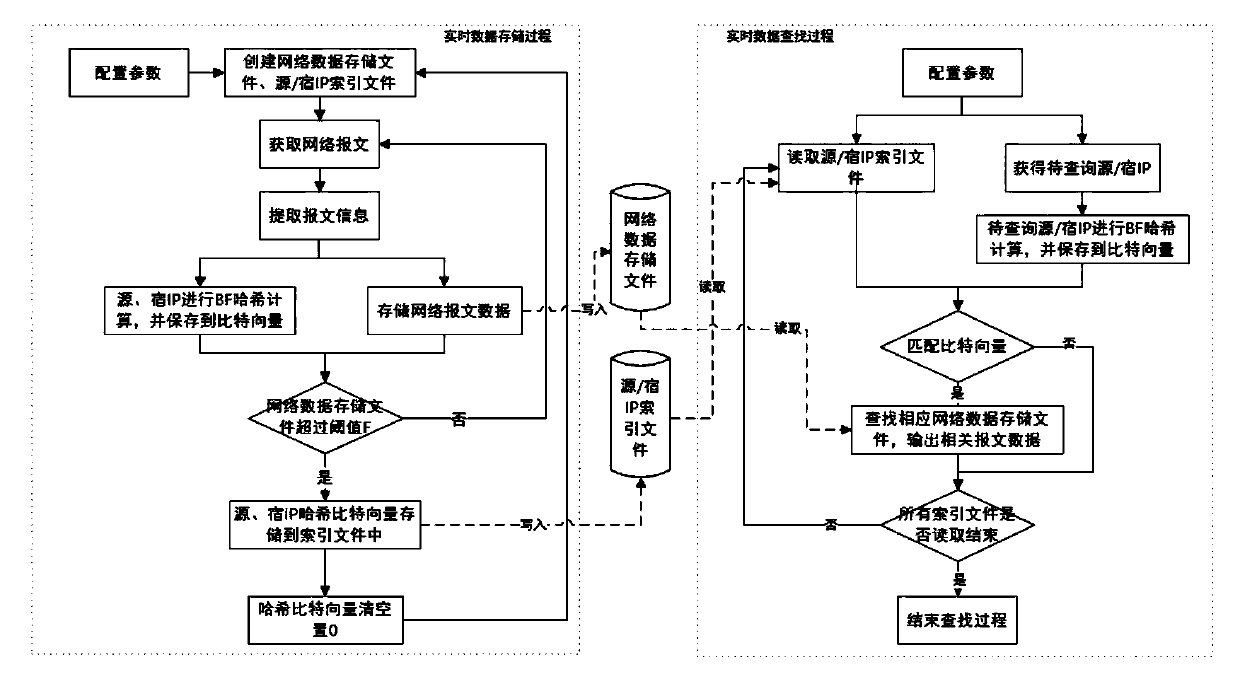
[0027] A massive network data search method based on a data flow structure, including: a real-time data storage method and a real-time query method,
[0028] The storage method of the real-time data is:
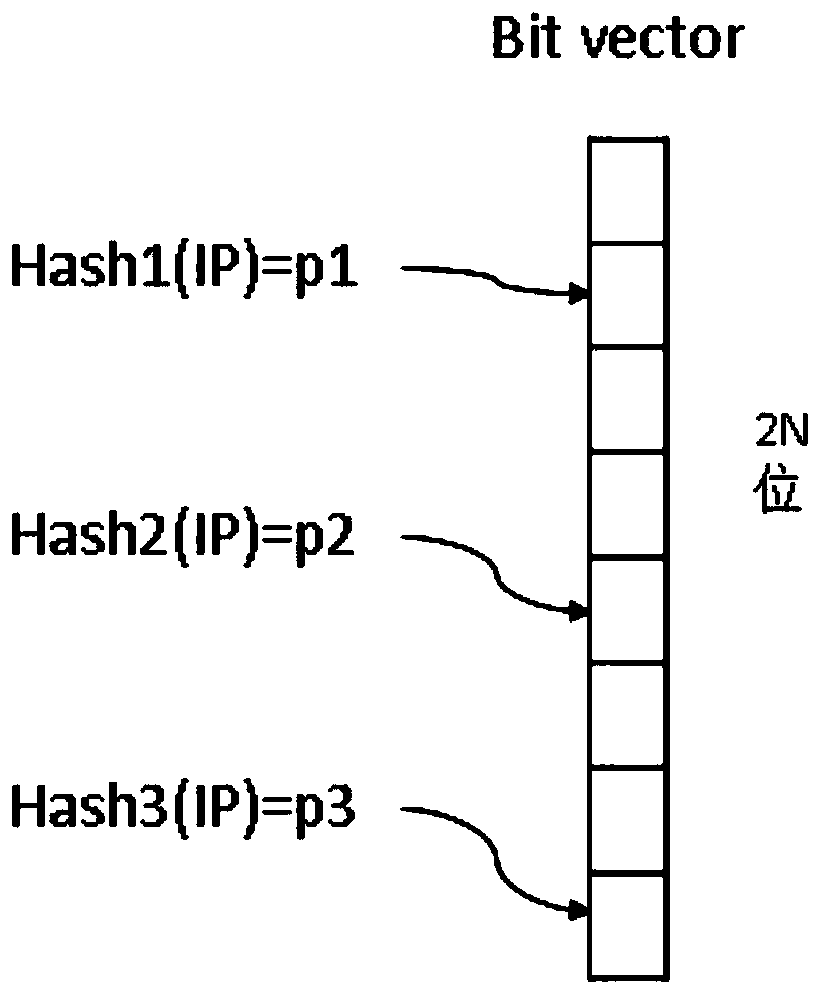
[0029] Step 101 configuration parameters, set a file threshold F, set two bit vectors Bsip and Bdip that are 2N in size, N is a positive integer greater than 1, and the initial values of all 2N bits in the bit vectors Bsip and Bdip are set to 0,
[0030] Step 102 creates a new empty network data storage file and source IP and destination IP index file, the threshold of the network data storage file is taken as the file threshold F set in step 101,
[0031] Step 103 obtains the network message, intercepts the byte stream of the first K bytes of the obtained network message and the byte stream of the first K bytes includes source IP, destination IP and network data, and from the intercepted Extract source IP and sink IP in the byte stream, K is the byte number of the interce...
Embodiment 2
[0040] A method for searching massive network data based on a data flow structure, comprising: a storage method for real-time data and a real-time query method, characterized in that,
[0041] The storage method of the real-time data is:
[0042] Step 101 configuration parameters, set a file threshold F, set two bit vectors Bsip and Bdip that are 2N in size, N is a positive integer greater than 1, and the initial values of all 2N bits in the bit vectors Bsip and Bdip are set to 0,
[0043] Step 102 creates a new empty network data storage file and source IP and destination IP index file, the threshold of the network data storage file is taken as the file threshold F set in step 101,
[0044] Step 103 obtains the network message, intercepts the byte stream of the first K bytes of the obtained network message and the byte stream of the first K bytes includes source IP, destination IP and network data, and from the intercepted Extract the source IP and destination IP from the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com