User group division method based on anti-fake traceability system and system thereof
A user group and user technology, applied in the field of anti-counterfeiting and traceability, can solve the problems of insufficient comprehensive user-related characteristic information and ineffective mining of data information value, etc., and achieve the effect of high robustness, large amount of calculation, and obvious effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

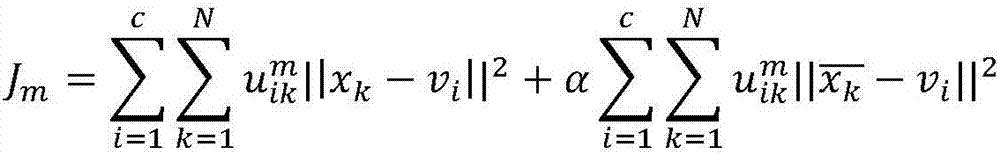
Examples
Embodiment 1
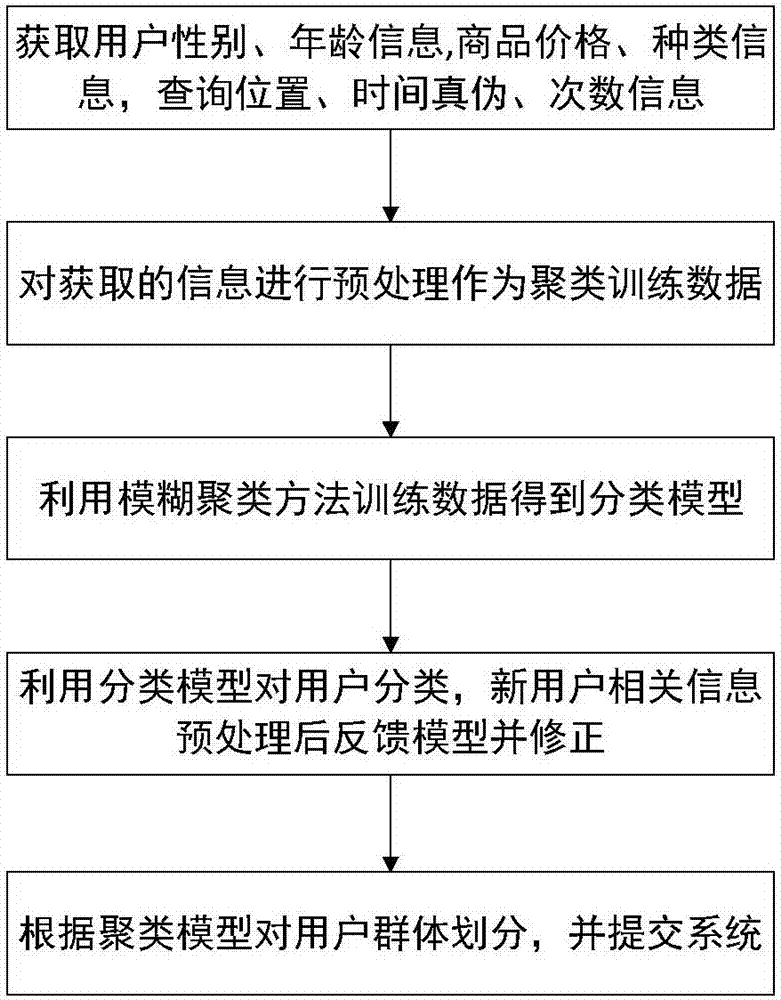
[0046] Such as figure 1 As shown, a user group division method based on an anti-counterfeiting traceability system includes the following steps:
[0047] S1: Obtain the characteristic information of the user, the characteristic information of the commodity and the characteristic information of the query;
[0048] S2: According to the obtained information, use data cleaning, data integration, data transformation and data reduction methods to preprocess the data, and obtain the sample set D, D={x 1 ,x 2 ,...,x m} contains m unlabeled samples, each sample x i =(x i1 ; x i2 ,...,xin ) is an n-dimensional feature vector, which reflects the relevant feature information of the user;
[0049] S3: According to the sample set obtained by preprocessing, use the improved fuzzy clustering algorithm to divide and mark the user groups, and obtain the classification model at the same time;
[0050] S4: Divide the new users according to the classification model, and correct the model pa...
Embodiment 2
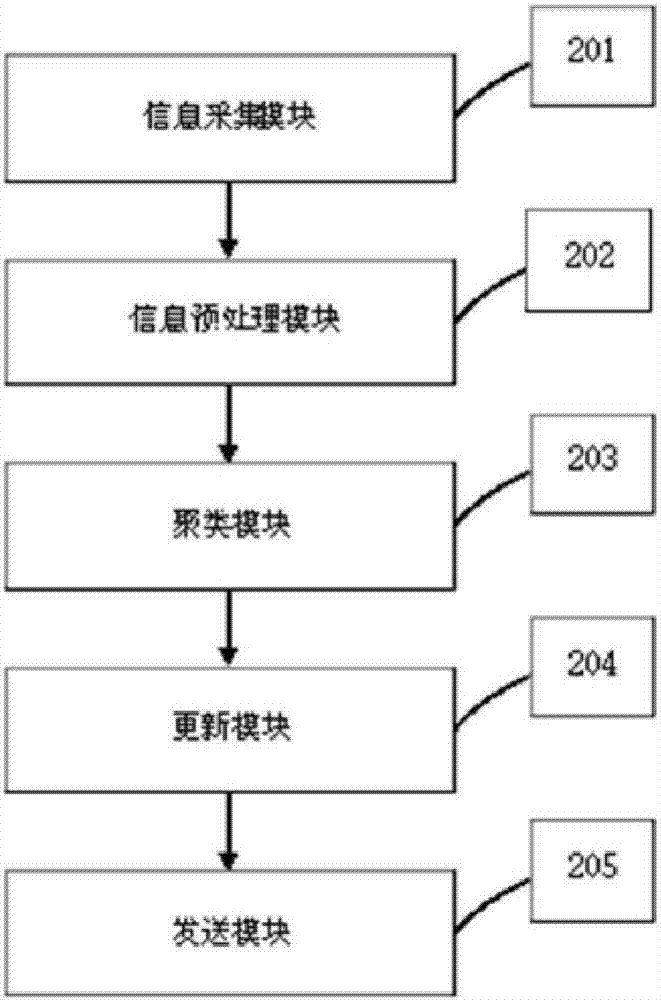
[0072] Such as figure 2 As shown, a user group classification system based on an anti-counterfeiting traceability system includes:
[0073] Information collection module 201: used to collect information required for clustering, user feature information, product feature information and query feature information;
[0074] Information preprocessing module 202: used for preprocessing the data obtained by the information collection module, the obtained sample set D={x 1 ,x 2 ,...,x m} contains m unlabeled samples, each sample x i =(x i1 ; x i2 ,...,x in ) is an n-dimensional feature vector, which reflects the relevant feature information of the user;
[0075] Fuzzy clustering module 203: used to divide D into k disjoint clusters {C l |l=1,2,...,k}, where and lambda j ∈{1,2,...,k} represents the "cluster label", that is A cluster label vector λ containing m elements j =(λ 1 ,λ 2 ,...,λ m ) represents the result of clustering, which reflects the division of user g...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com