Method and device for deleting duplicated data
A data and database technology, applied in the field of data processing, can solve problems such as heavy system load, data storage and query performance degradation, and achieve the effect of reducing usage and cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0046] figure 1 It is a flow chart of a method for deduplication of data provided by Embodiment 1 of the present invention. This embodiment is applicable to the case of effectively deduplication of massive data, and the method can be performed by a data deduplication device. The method is specific Including the following steps:
[0047] S110. Obtain the MD5 value of the data to be processed and the corresponding data identifier.
[0048] Among them, MD5 (Message-Digest Algorithm 5, Information-Digest Algorithm 5) is used to ensure the integrity and consistency of information transmission. It is one of the hash algorithms widely used by computers. It has compressibility, easy calculation, anti-modification and strong anti-collision, etc. features. The type of data to be processed can be a text type, and the data can be read by row or by column and the corresponding MD5 value of the data can be calculated. The data identifier can be used as a mark for each piece of data to dis...
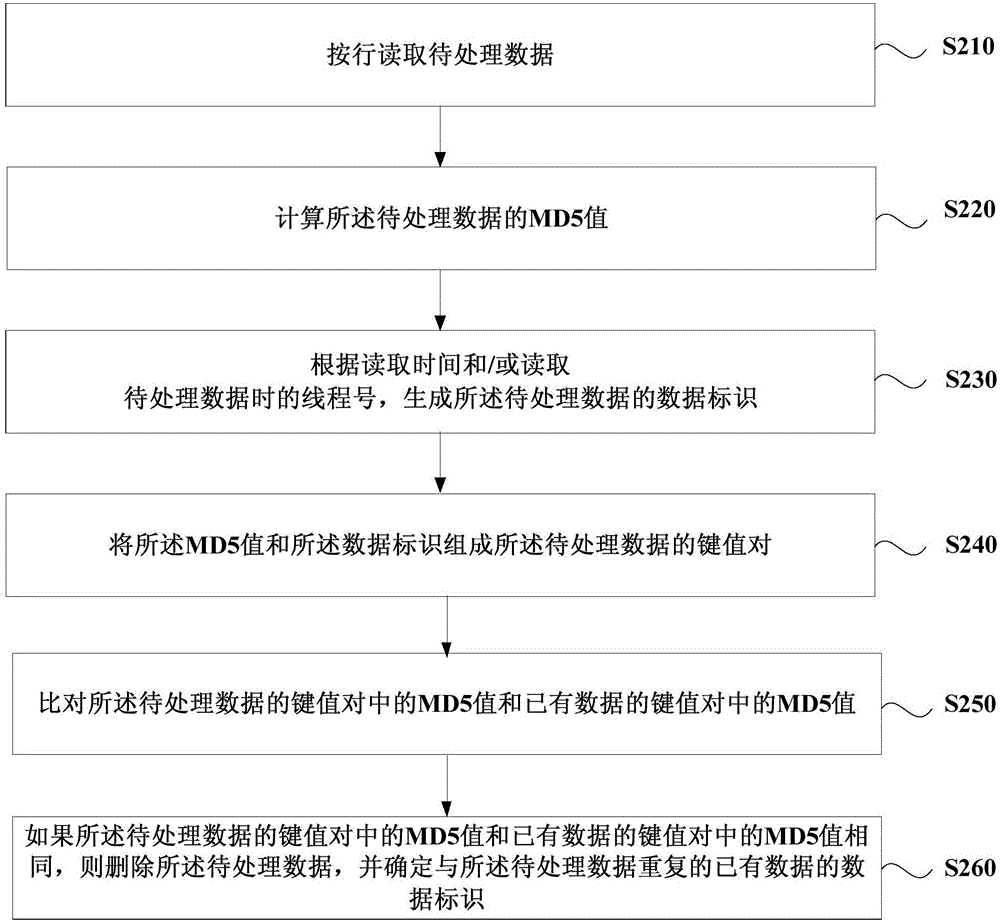
Embodiment 2
[0066] figure 2 It is a flowchart of a data deduplication method provided by Embodiment 2 of the present invention. This embodiment is further optimized on the basis of the above embodiments, and "acquires the MD5 value of the data to be processed and the corresponding data identifier" It is further refined as "reading the data to be processed by row; calculating the MD5 value of the data to be processed; generating the data identifier of the data to be processed according to the reading time and / or the thread number when reading the data to be processed. "This method specifically comprises the following steps:
[0067] S210. Read the data to be processed row by row.
[0068] Among them, the data can be a data access link before the preprocessing, and the data can be moved to the preprocessing server through a moving tool, and wait for the data to be processed. In the preprocessing server, the program reads data row by row. The commonly used moving programs are all transmi...
Embodiment 3
[0078] Figure 4 It is a flow chart of a data deduplication method provided by Embodiment 3 of the present invention. This embodiment further optimizes the above-mentioned embodiment on the basis of further refinement of "calculating the MD5 value of the data to be processed" "If the data to be processed contains preset ignored data, remove the preset ignored data from the data to be processed; calculate the MD5 value of the data to be processed after removing the preset ignored data, as the The MD5 value of the data to be processed." The method specifically includes the following steps:
[0079] S410. Read the data to be processed row by row.
[0080] S420. If the data to be processed includes preset ignored data, remove the preset ignored data from the data to be processed.
[0081] Among them, before reading the data to be processed, some data content can be set as preset ignore data according to actual needs, for example, it can be the port number of the data or some unn...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com