


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
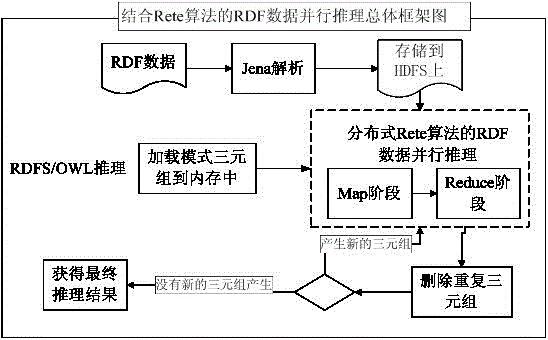
RDF data distributed parallel inference method combined with Rete algorithm
A reasoning method and distributed technology, applied in the field of semantic web, can solve problems such as unable to meet the needs of massive data, unable to process data reasoning, reasoning is not efficient enough, etc., to achieve efficient reasoning, obvious effects, and far-reaching effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
example
[0036]Instance triples refer to subject and object, which are usually not found in ontology files, and are specific instances: for example, instance triples (s2, p2, o2):
[0037] Subject S2: http: / / www.Department0.University0.edu / AssistantProfessor4 / Publication5
[0038] Predicate P2: http: / / swat.cse.lehigh.edu / onto / univ-bench.owl#publicationAuthor
[0039] Object O2: http: / / www.Department0.University0.edu / GraduateStudent41
example 3
[0040] The instance triplet is a specific instance, for example, the subject S2 of the instance triplet is Publication5; Publication5 is the specific instance of Publication in the pattern triplet
[0041] S12: Set the key (key) output by the Map stage as the rule name, and the value (value) is an instance triplet that satisfies the antecedent of the corresponding RDFS / OWL rule; if the antecedent satisfied by an instance triplet data is For the antecedents of multiple rules, different keys (keys) are used to redundantly store the instance triplet data, and the output of each value (value) includes the instance triplets in the antecedents that satisfy the corresponding RDFS / OWL rule; In this embodiment, the rule rule1:p rdfs:domain x & s p o =>s rdf:type x, if the input RDF triple data (s1,p1,o1) satisfies the condition "p rdfs:domain x", after After the Map stage, the output here is .
[0042] In order to ensure the correctness of the reasoning results, it is necessary to ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com