Document similarity calculation method and near-duplicate document detection method and device
A technology of document similarity and calculation method, applied in the computer field, can solve the problems of similar duplicate documents, increase the complexity of duplicate content, and the accuracy is easily affected by the order of word segmentation.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
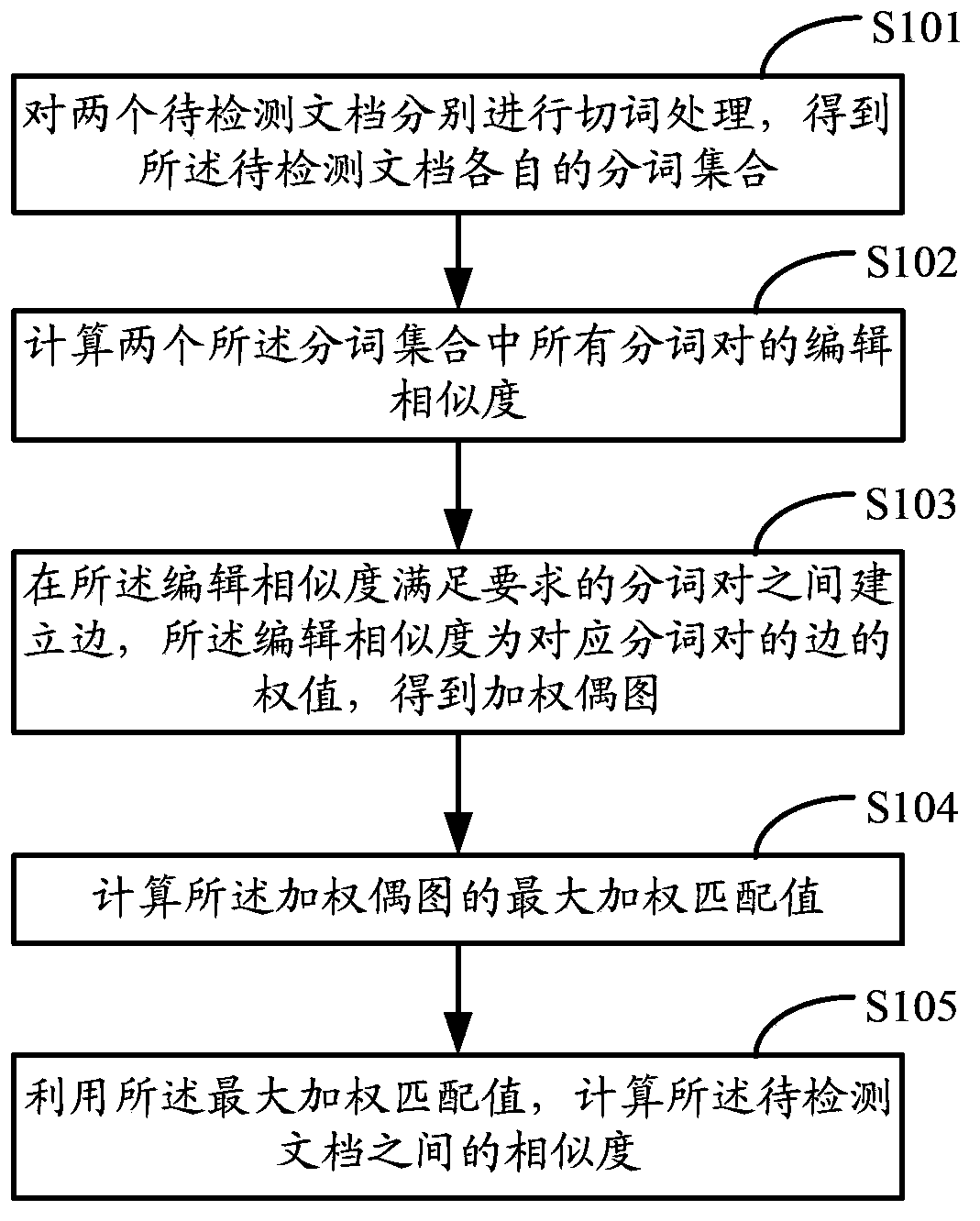
[0118] figure 1 It is a flowchart of the method for calculating document similarity provided by this embodiment, such as figure 1 As shown, the document similarity calculation method of the present invention includes:
[0119] S101: Perform word segmentation processing on two documents to be detected respectively to obtain respective word segmentation sets of the documents to be detected.
[0120] For two documents to be detected 1 ,s 2 Perform word segmentation separately to obtain the word segmentation set T 1 ,T 2 .
[0121] S102. Calculate the editing similarity of all word segmentation pairs in the two word segmentation sets.
[0122] Wherein, the two word segmentation of each word segmentation pair are derived from the two word segmentation sets respectively.
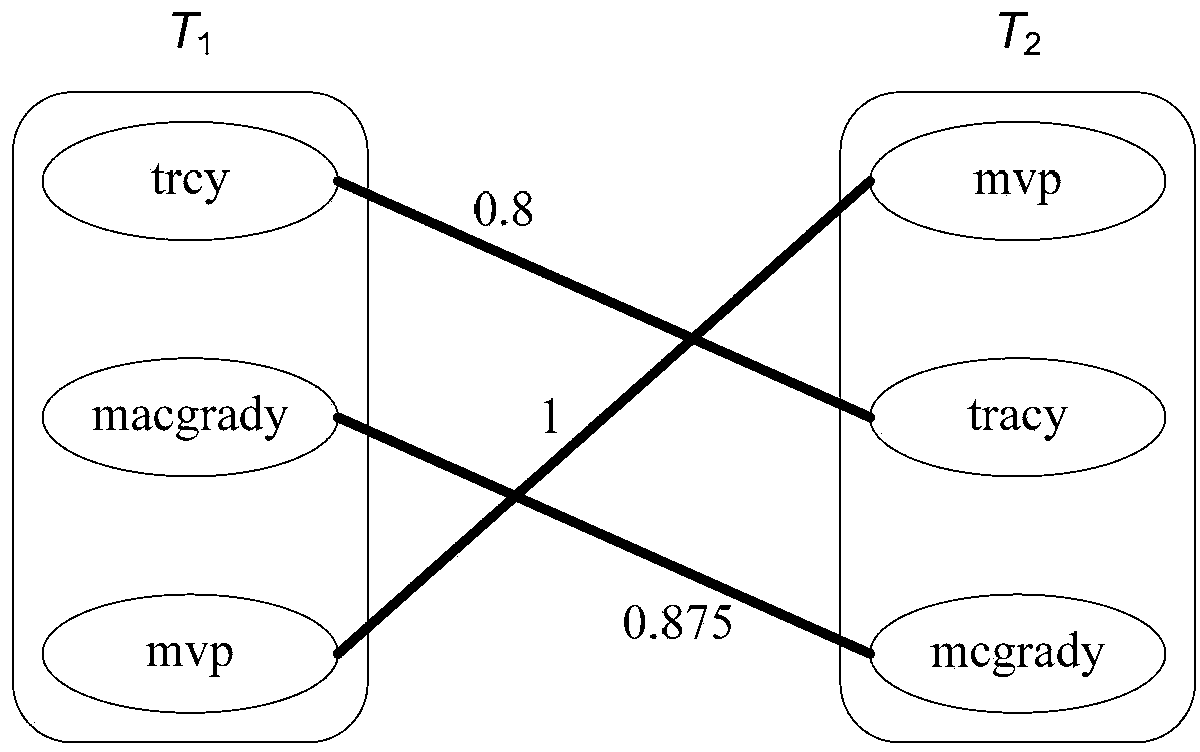
[0123] Specifically, the word set T 1 With T 2 All participle t 1,i ∈ T 1 , T 2,j ∈ T 2 Build a Bipartite Graph for the vertices, where 1≤i≤m, 1≤j≤n, m and n are the word segmentation set T 1 With T 2 , Calculate all word...
Embodiment 2
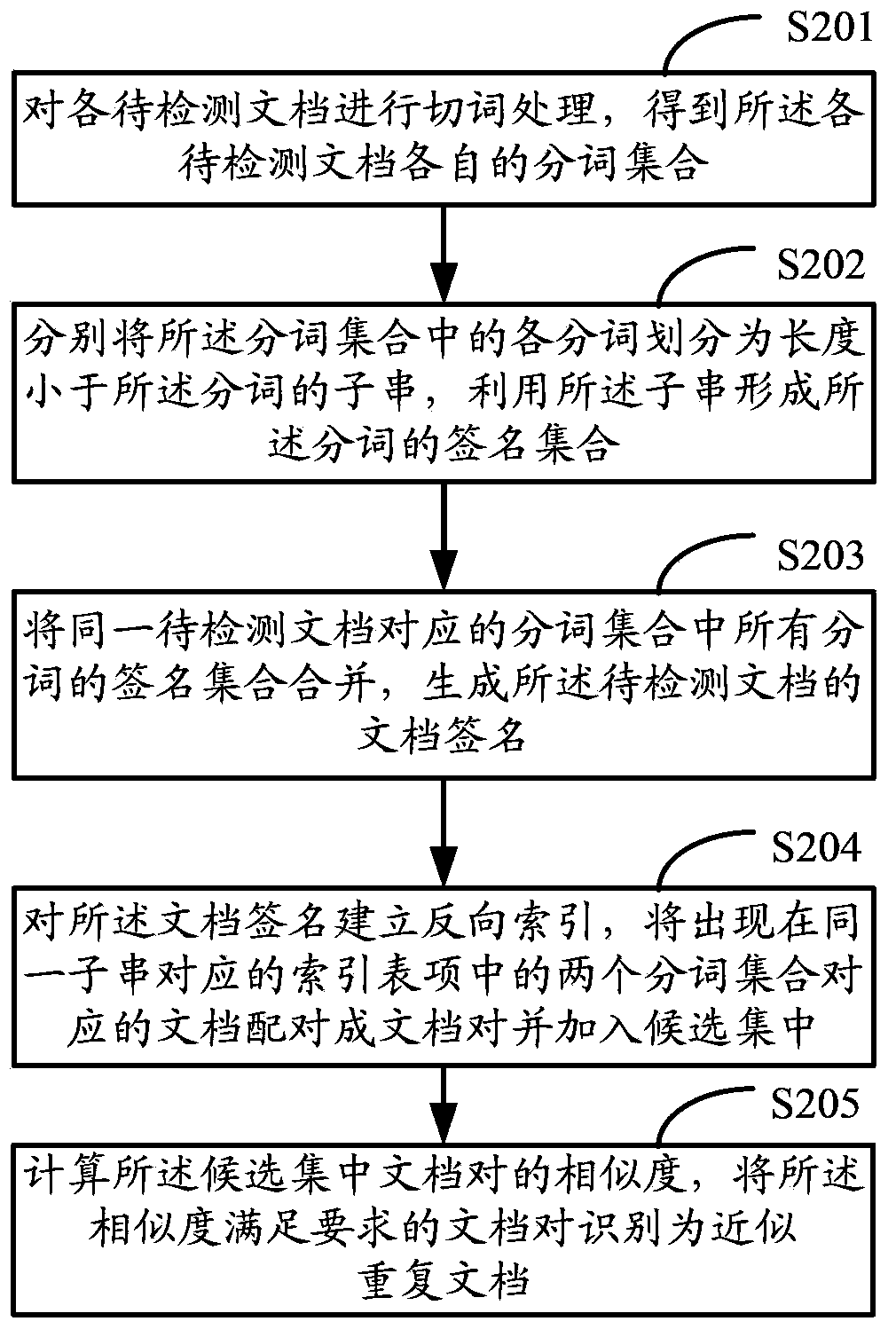
[0140] figure 2 It is the flow chart of the approximate duplicate document detection method provided by this embodiment, such as figure 2 As shown, the approximate duplicate document detection method of the present invention includes:
[0141] S201: Perform word segmentation processing on each document to be detected to obtain a respective word segmentation set of each document to be detected.
[0142] Using existing word segmentation methods, for example, by identifying specific non-English characters (such as punctuation, numbers, etc.), the word segmentation method, the forward maximum matching method, etc., the word segmentation process is performed on each document to be detected to obtain the word segmentation set .
[0143] Optionally, number the word segmentation obtained by the word segmentation process and record the word segmentation number, where the word segmentation number indicates the order in which the word segmentation appears in the document to be detected.
[014...
Embodiment 3
[0187] Figure 4 It is a schematic diagram of the document similarity calculation device provided by this embodiment, such as Figure 4 As shown, the document similarity calculation device of the present invention includes: a word segmentation module 401, a first calculation module 402, a weighted even picture establishment module 403, a second calculation module 404, and a third calculation module 405.
[0188] The word segmentation module 401 is configured to perform word segmentation processing on two documents to be detected respectively to obtain respective word segmentation sets of the documents to be detected.
[0189] The word segmentation module 401 analyzes the two documents to be detected 1 ,s 2 Perform word segmentation separately to obtain the word segmentation set T 1 ,T 2 .
[0190] The first calculation module 402 is configured to calculate the editing similarity of all word segmentation pairs in the two word segmentation sets obtained by the word segmentation module 4...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com