


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Method for identifying websites and finely classifying web pages in medical field
A technology for websites and web pages, used in website identification and web page segmentation, in the field of Internet search
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0098]本发明的关键点在于:
[0099]本发明解决方案的整体框架包括先对网站进行粗分,再进行小类细分的整体流程,只有这一整套流程才能够保证分类的实现,流程中的每一步都不可以改变。
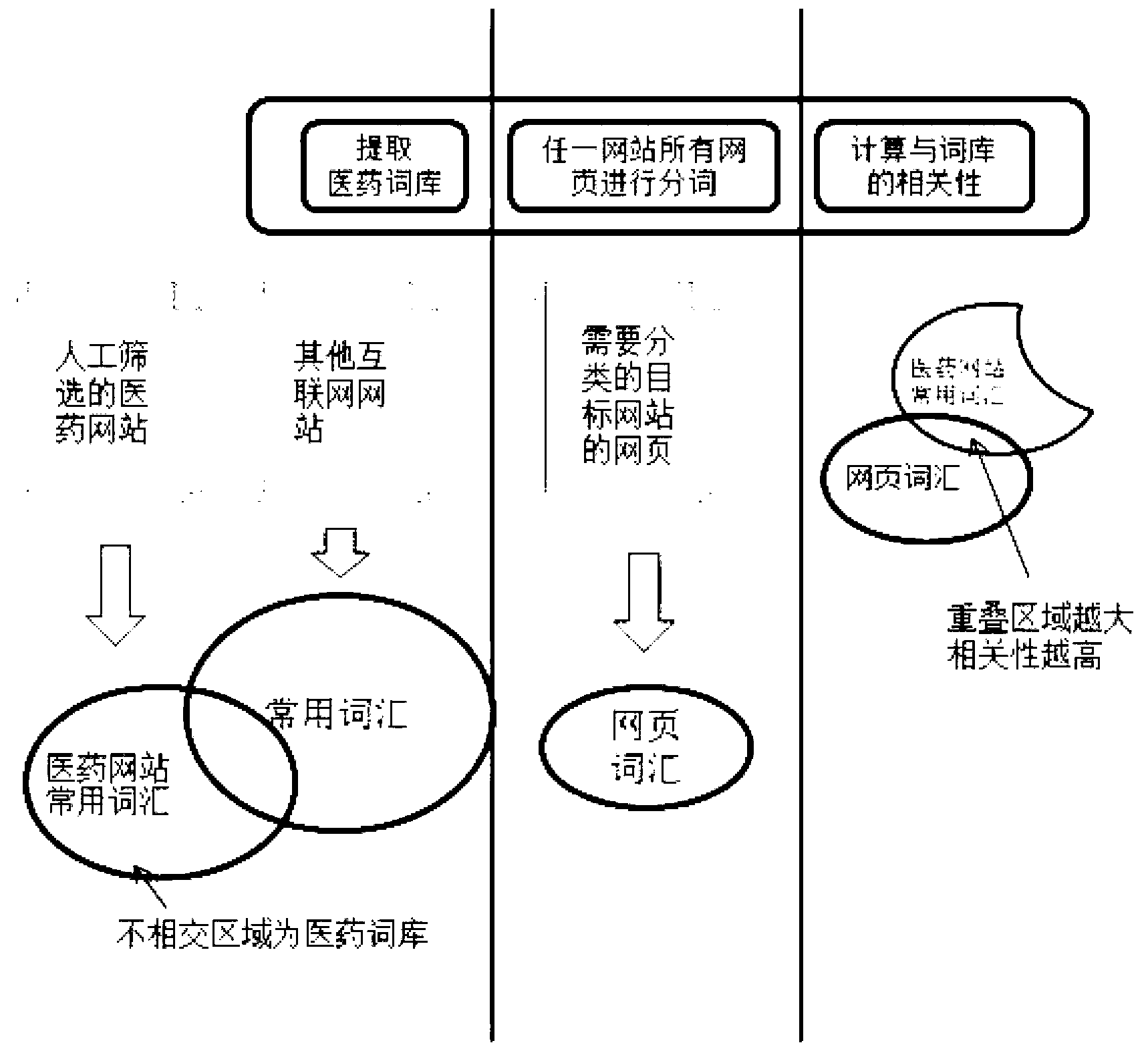
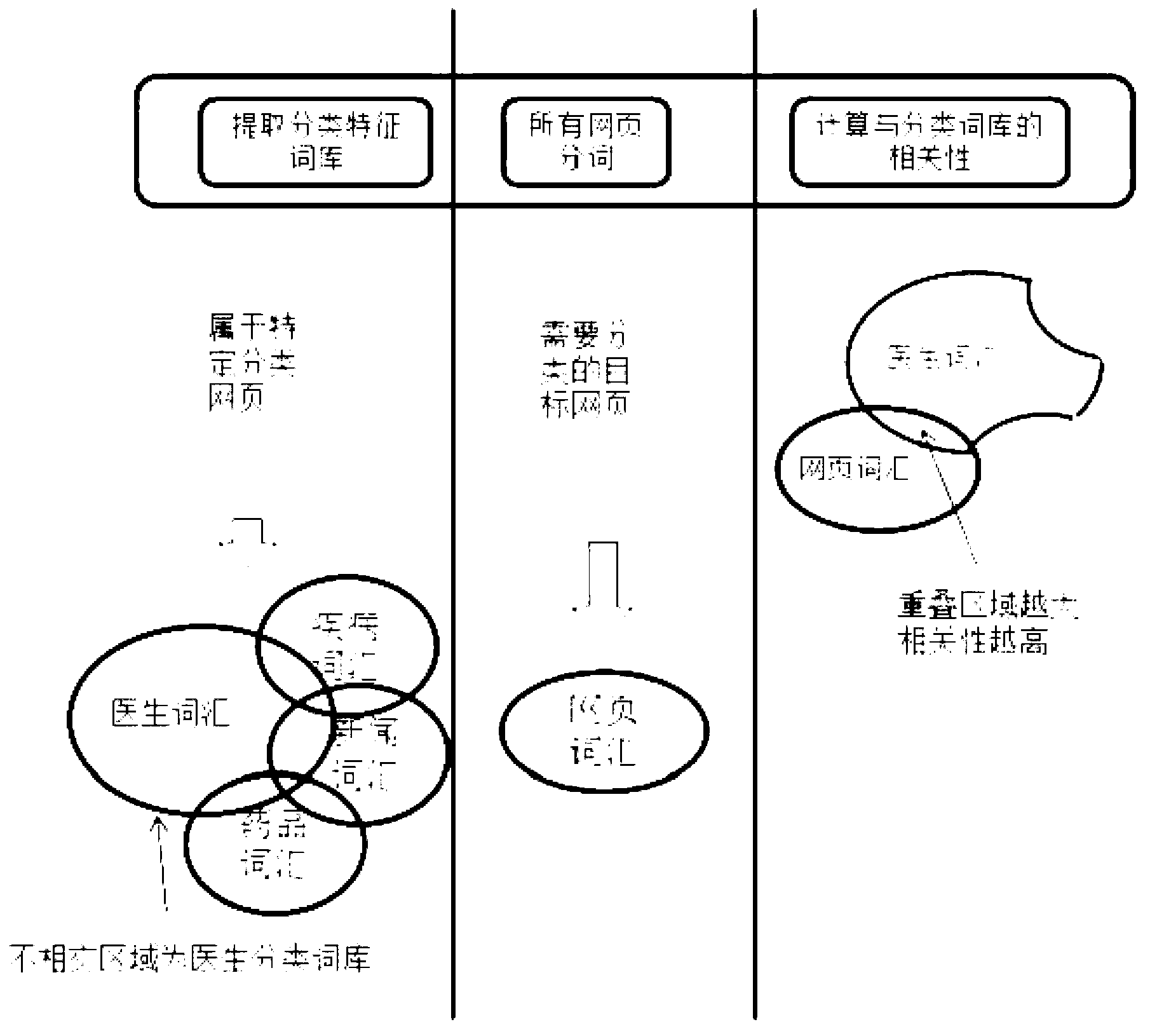
[0100]本发明的整体框架中,从现有网站中提取医学分类主题词库的算法,以及将网站及网页根据分类主题词库进行打分,并根据打分结果进行分类的算法。打分算法根据网页的内容特征,不过分依赖词频。这种训练医学数据得到词库、并使用训练好的数据打分的分类算法也是关键点。
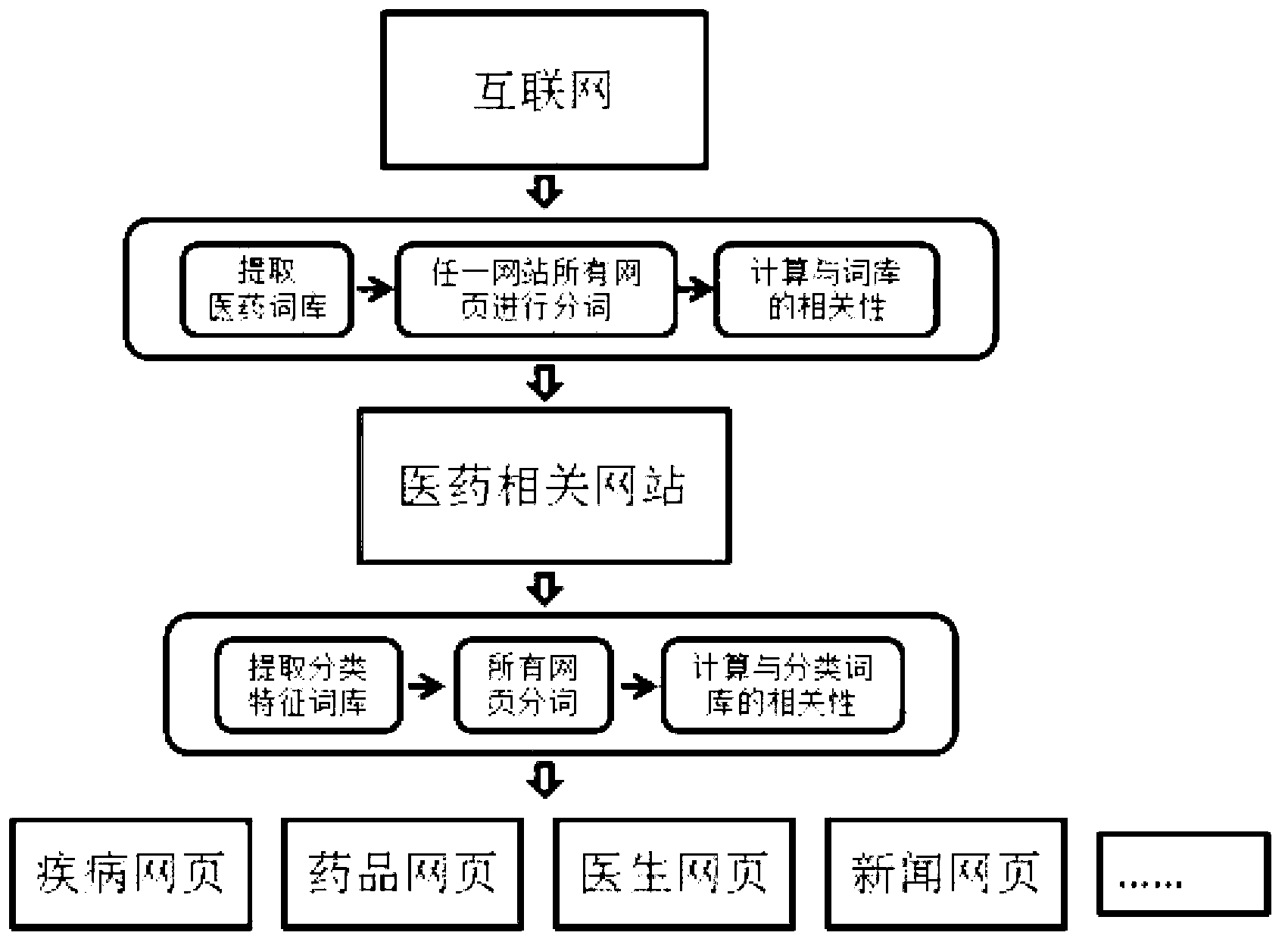
[0101]本发明主要是分两步,如图1所示,先从全网中提取医药相关的网站,然后将这些网站中的网页进行分类,从中提取出包括但不限于医生、疾病、药品、新闻等四类网页。
[0102]面向医学领域的网站识别方法,是从全网提取医药相关的网站,具体包括以下步骤:
[0103](一)获得综合类网站的词语集合
[0104](1)从全网中采集非医药相关的综合类网页;
[0105]这一步使用web采集器,也就是网络蜘蛛下载网页的内容。
[0106]随机选取的网站为国内比较大的五个门户网站:新浪(www.sina.com.cn),网易(www.163.com),腾讯(www.qq.com),搜狐(www.sohu.com)和凤凰网( www.ifeng.com),使用爬虫抓取每个网站的网页(设定从单个网站抓取的网页数量上限为30w)。
[0107]这一步是准备工作,目的是获取一些综合类的网页,所以在网站的选取方面自由度比较大,只要是综合类的网站均可,但为了保证效果,网页的总个数应该在四五十万左右。
[0108](2)提取其中所有网页的内容,并进行分词,记录分词结果以及对应词频,归纳出综合类网站特征词集合,记为Tall;
[0109]在这一步中,首先过滤HTML网页中的代码,即把网页中的所有标签以及标签中的部分删除,然后过滤HTML标签(即所有能够匹配正则表达式的内容)。
[0110]过滤所有的非中文字母和符号,之后使用ICTCLAS分词器(Institute of Computing Technology, Chinese Lexical Analysis System,中科院汉语分词器,主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典等)对剩余的部分进行分词,记录所有词的词频。
[0111]计算出词频的平均值μ和标准差σ,词频的分布满足正态分布...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com