Path planning Q-learning initial method of mobile robot
A technology of mobile robot and initialization method, which is applied in the field of Q-learning initialization of mobile robot path planning, can solve the problems of not being able to objectively reflect the environment state of the robot, algorithm instability, etc., and achieve the goal of improving learning ability, accelerating convergence speed, and improving learning efficiency Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054] The present invention will be further described below in conjunction with accompanying drawings and examples.
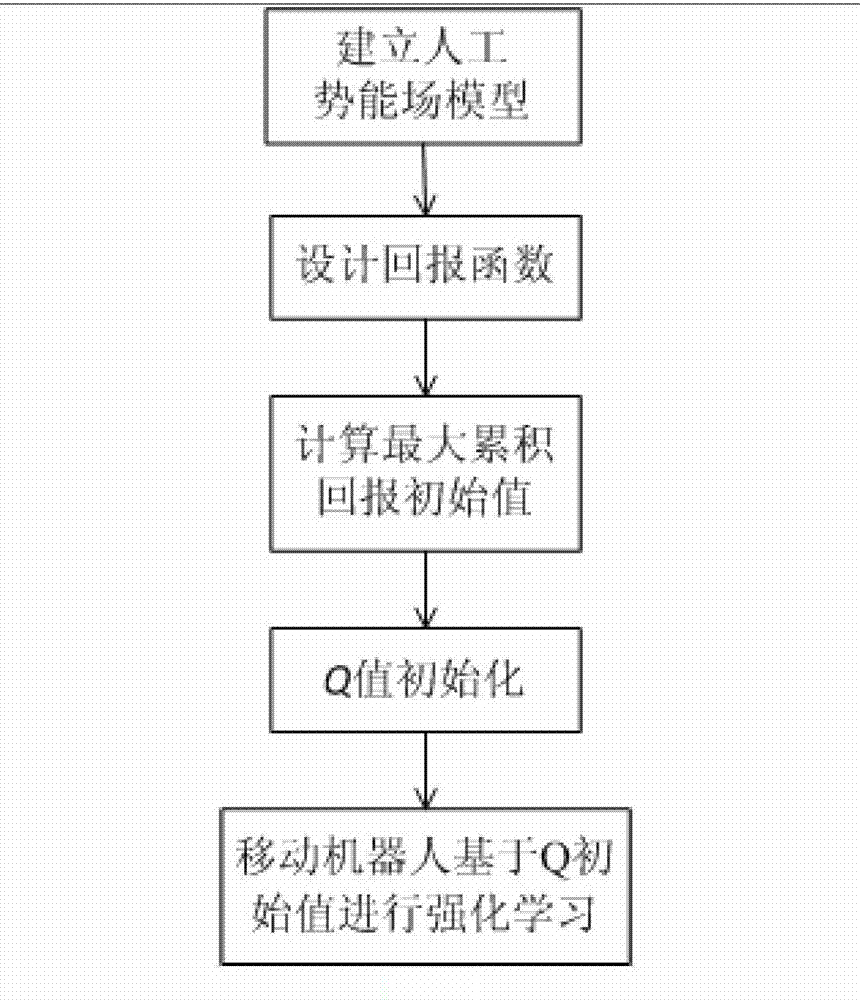
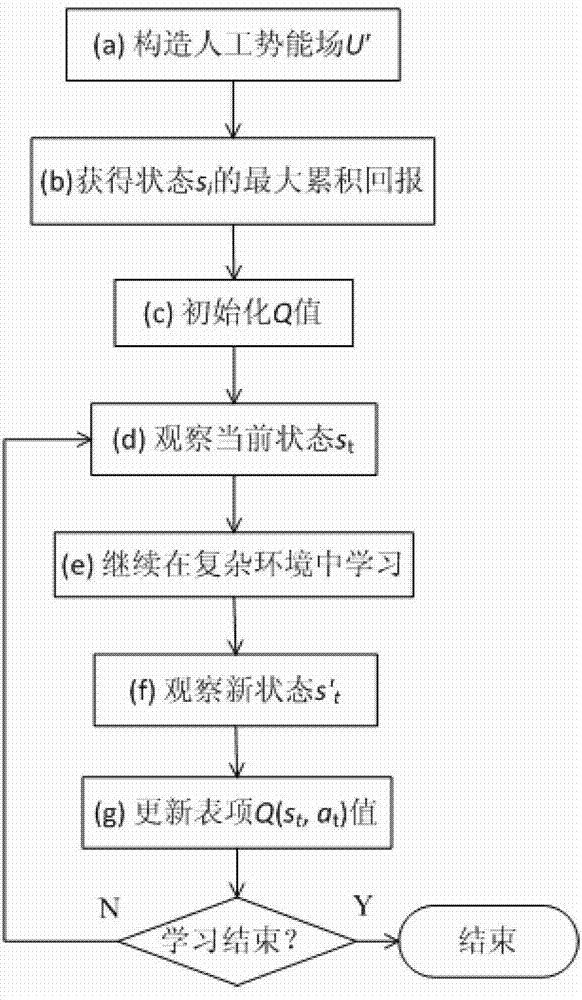
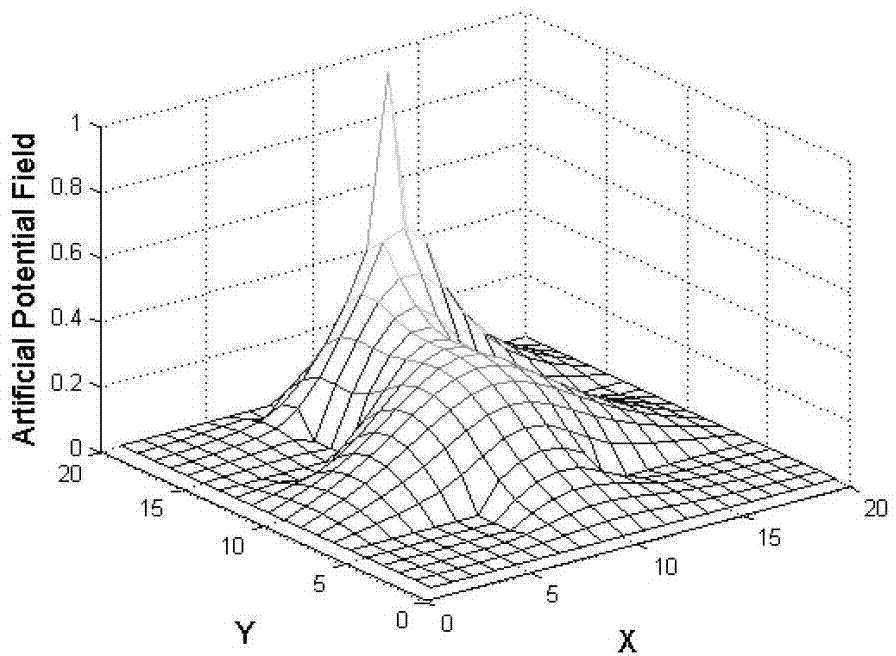
[0055] The invention initializes the robot reinforcement learning based on the artificial potential energy field, virtualizes the working environment of the robot into an artificial potential energy field, and constructs the artificial potential energy field by using prior knowledge, so that the potential energy value of the obstacle area is zero, and the target point has the global maximum potential energy At this time, the potential energy value of each state in the artificial potential energy field represents the maximum cumulative return that the corresponding state can obtain by following the optimal strategy. Then define the initial value of Q as the immediate reward of the current state plus the maximum discounted cumulative reward of the subsequent state. By initializing the Q value, the learning process converges faster and the convergence process is ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com