A method and system for providing sound bank hybrid training model
A technology for training models and sound libraries, applied in the direction of dot-dash line transmission devices, etc., can solve the problem of high cost and achieve the effect of reducing requirements, reducing costs, and making the process of training models easier
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
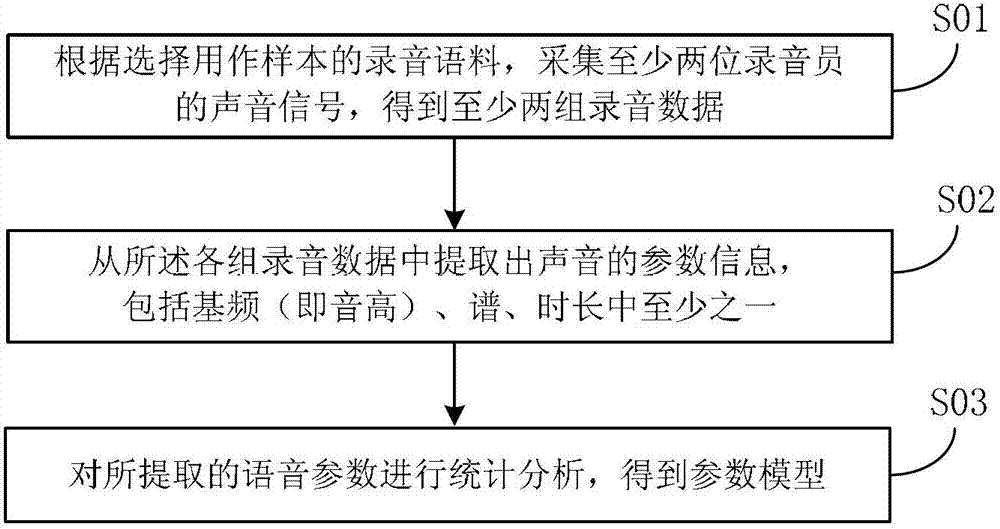
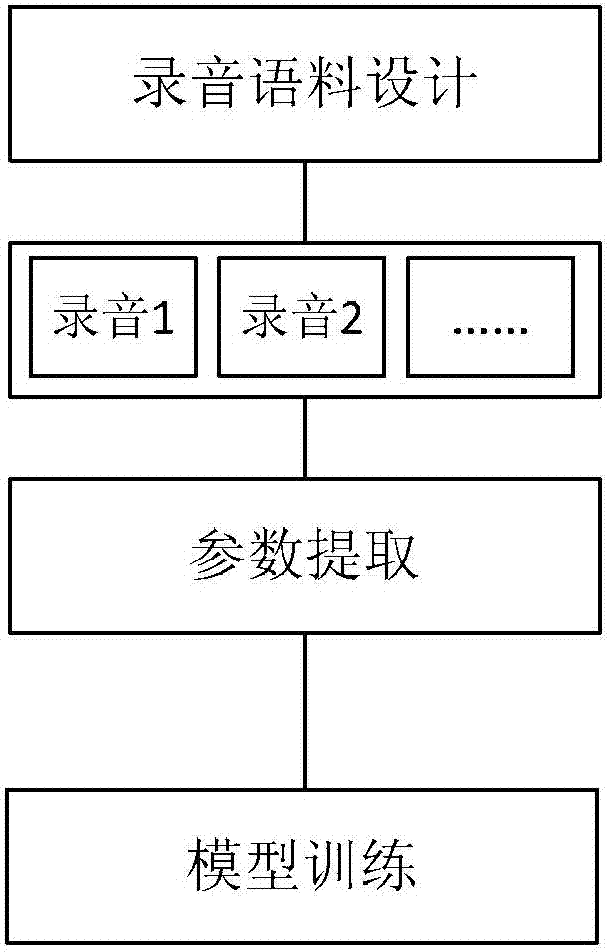
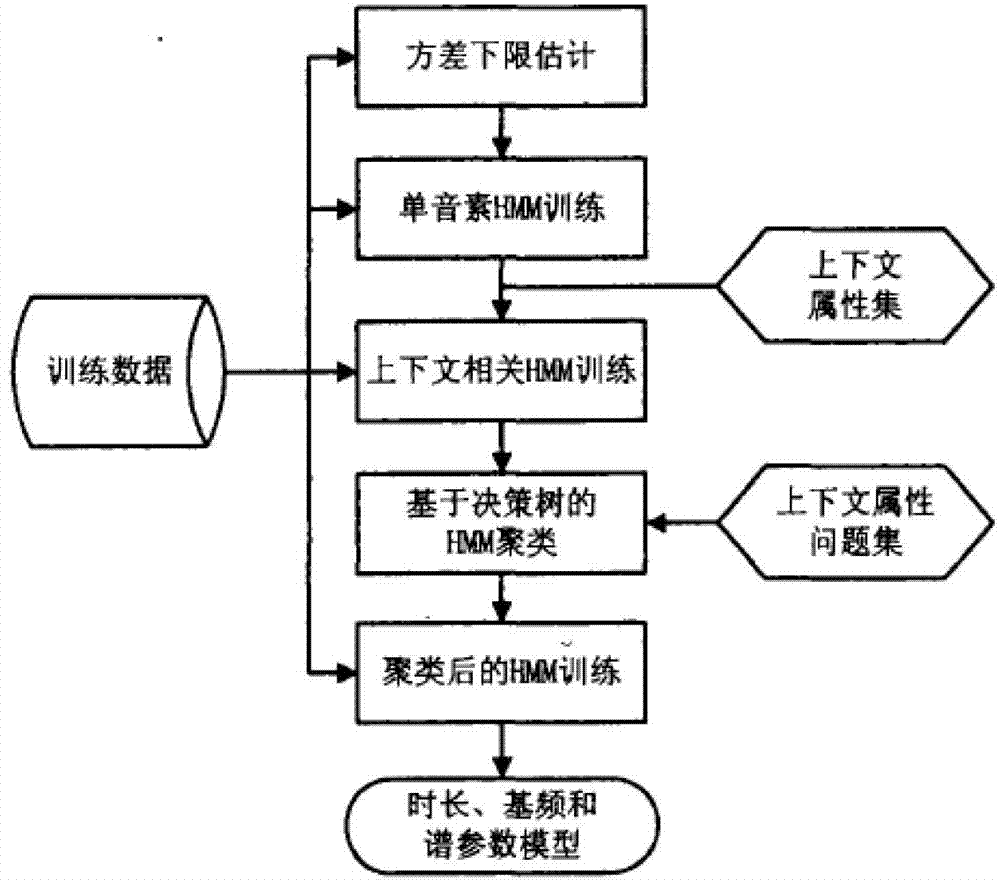
[0028] In view of the deficiencies in the prior art, the present invention proposes a sound bank mixed training model method, which can solve some or all of the aforementioned problems, and can establish a relatively stable model. The method of a mixed training model provided by the present invention: firstly select several speakers to record sound banks, and when training the model, mix multiple sound banks to train the model, that is, put the sound bank data of several speakers together for training. The advantage is that training with multiple speakers will blur the shortcomings of a single speaker, and the final trained model tends to be an average of multiple speakers, thus obtaining a more stable model. Secondly, each speaker has its own characteristics, through mixed training, different advantages can be combined. Third, the parameter characteristics of real speakers are not optimal, and training with multiple speakers can significantly optimize the speech synthesis eff...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com