Personalized speech synthesis model construction method and device, speech synthesis method and device, and personalized speech synthesis model test method and device
A technology of speech synthesis and construction method, which is applied in speech synthesis, speech analysis, speech recognition, etc., which can solve the problems of unable to synthesize speakers and achieve the effect of improving user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
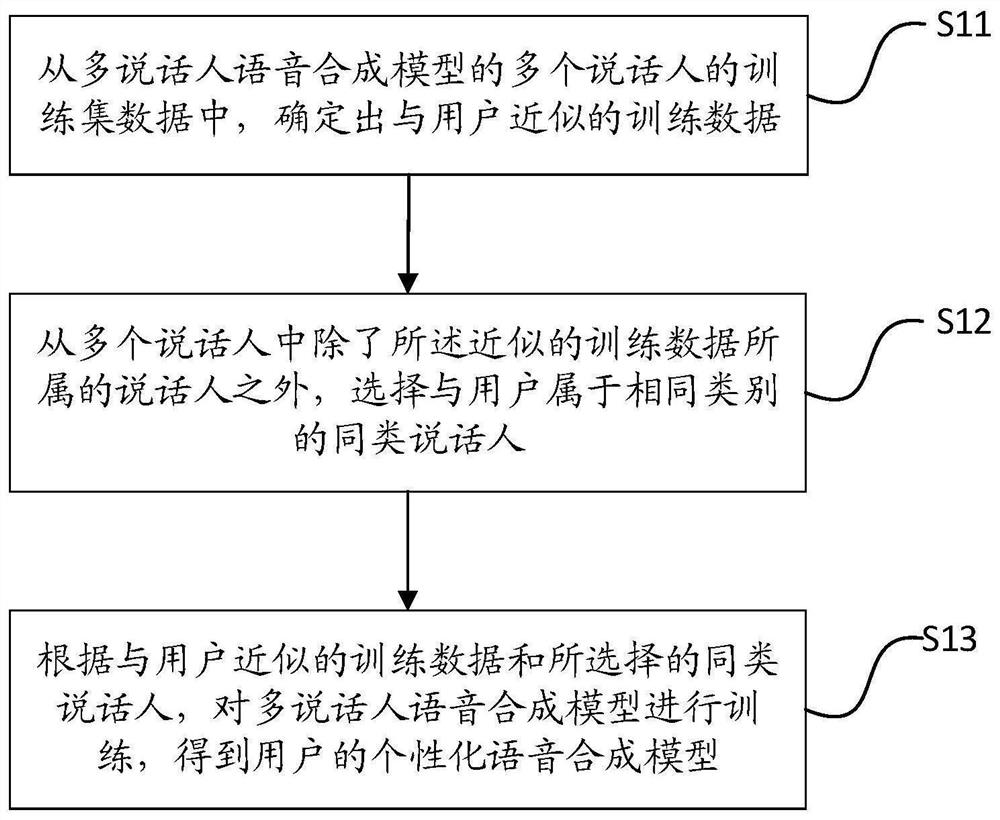
[0177] Assuming that the training set data of multiple speakers of the multi-speaker speech synthesis model includes speaker A, speaker B, speaker C, speaker D and speaker E, their IDs in the multi-speaker speech synthesis model ID1, ID2, ID3, ID4 and ID5 respectively. Use the training data of these speakers to train the multi-speaker Neural TTS model to obtain a trained multi-speaker Neural TTS model.
[0178] Currently there is a personalized speaker as speaker F, refer to Figure 6A In the flow chart shown, the personalized data of the speaker F, that is, speech data and text, are respectively subjected to speech synthesis, automatic labeling and speech data preprocessing, and corresponding linguistic features and acoustic features are extracted.
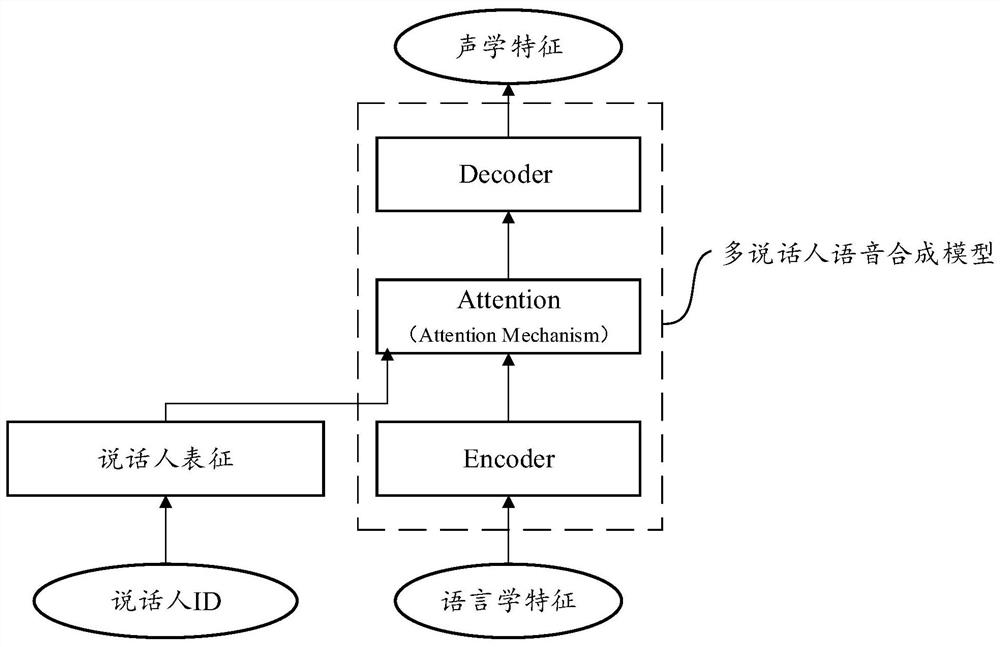
[0179] Figure 6B Shown is the process of how to extract linguistic features from text and speech. For example, the pronunciation annotation and prosodic annotation in the text are first extracted through the TTS front-end, and...
Embodiment 2
[0185] Similar to Embodiment 1, the training set data of multiple speakers of the multi-speaker speech synthesis model in Embodiment 2 includes speaker A, speaker B, speaker C, speaker D and speaker E The IDs of all training data in the multi-speaker speech synthesis model are ID1, ID2, ID3, ID4 and ID5 respectively. Use the training data of these speakers to train the multi-speaker Neural TTS model to obtain a trained multi-speaker Neural TTS model.
[0186] Currently there is a personalized speaker as speaker F, refer to Figure 7A In the flow chart shown, the personalized data of the speaker F, that is, speech data and text, are respectively subjected to speech synthesis, automatic labeling and speech data preprocessing, and corresponding linguistic features and acoustic features are extracted. Specifically how to extract can refer to the Figure 6B with Figure 6C .
[0187] The difference from Embodiment 1 is that the corresponding vectors are calculated for each sent...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com