Audio-based personalized recommendation method and device and mobile terminal
An audio and audio recognition technology, applied in special data processing applications, instruments, biological neural network models, etc., can solve the problems of low recommendation success rate and failure to consider the characteristics of the anchor's voice
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
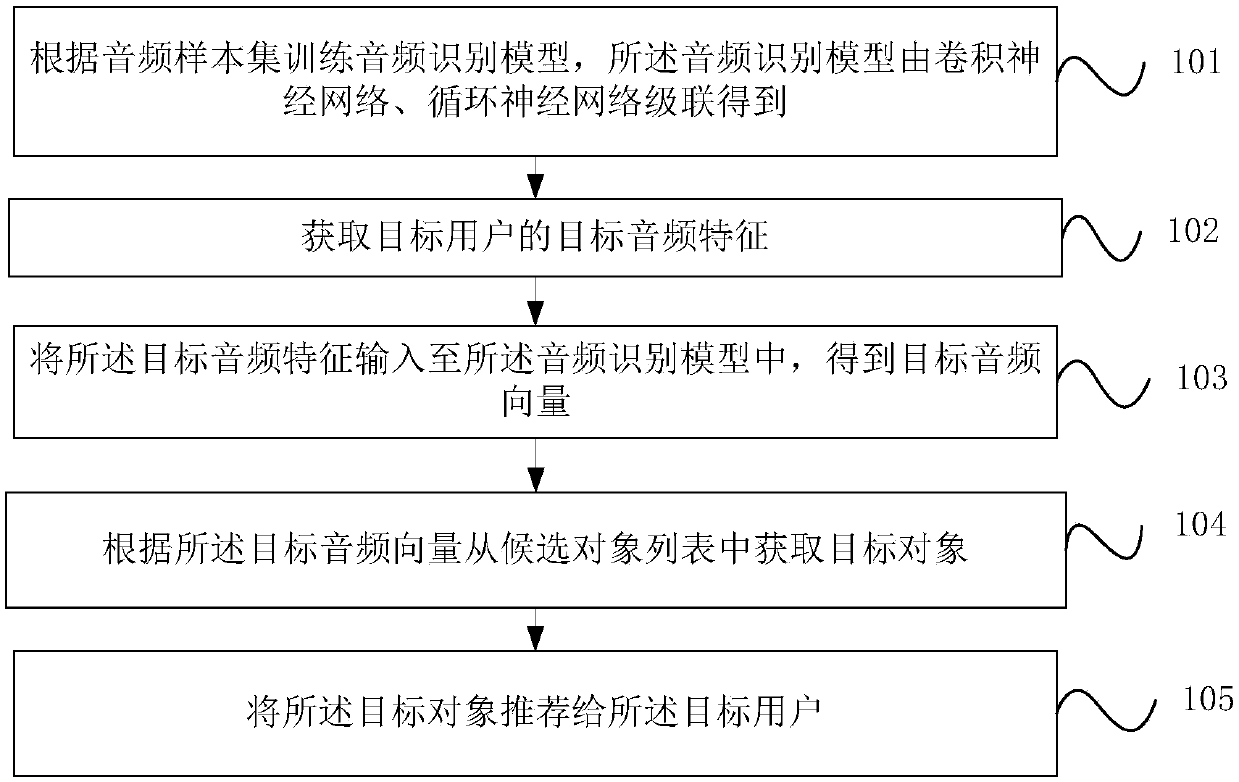
[0085] refer to figure 1 , which shows a flow chart of the steps of an audio-based personalized recommendation method according to the present invention, which may specifically include the following steps:
[0086] Step 101, train an audio recognition model according to the audio sample set, and the audio recognition model is obtained by cascading a convolutional neural network and a cyclic neural network.
[0087] Among them, the audio sample set is several pre-marked audio samples, and each audio sample is marked as a positive sample or a negative sample or a reference sample. The positive sample and the reference sample have the same characteristics, and the negative sample and the reference sample have different characteristics.
[0088] In the embodiment of the present invention, the training of the audio recognition model is the training of the convolutional neural network and the cyclic neural network. By continuously adjusting the parameters of the convolutional neural...
Embodiment 2
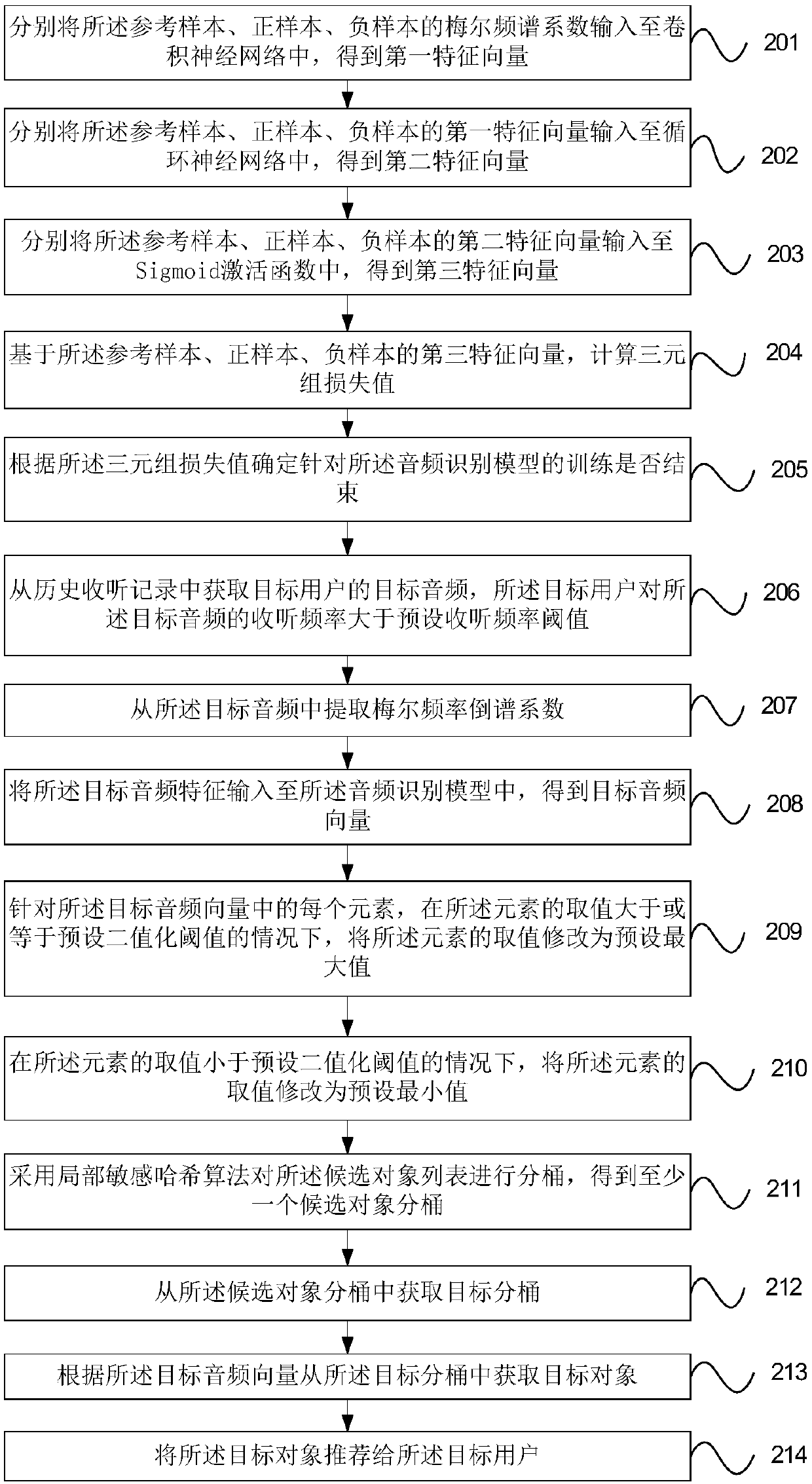
[0104] refer to figure 2 , which shows a flow chart of steps of another audio-based personalized recommendation method of the present invention, which may specifically include the following steps:
[0105] Step 201, respectively input the mel spectral coefficients of the reference sample, positive sample, and negative sample into the convolutional neural network to obtain a first feature vector.
[0106] In an embodiment of the present invention, the audio sample set includes: a reference sample, a positive sample, and a negative sample, wherein the reference sample is a standard sample, the audio features of the positive sample and the reference sample are similar, and the audio features of the negative sample and the reference sample are not similar.
[0107] Among them, the convolutional neural network may include one or more convolutional units, so that the sample is input to the first convolutional unit, and the output of the first convolutional unit is the input of the ...
Embodiment 3
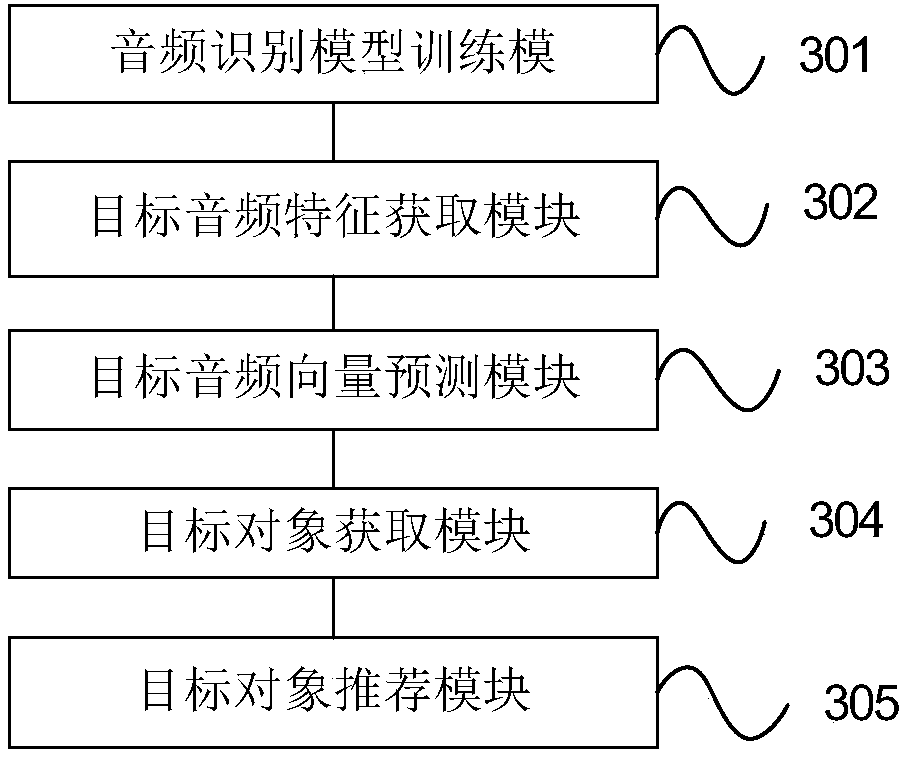
[0175] refer to image 3 , which shows a structural block diagram of an audio-based personalized recommendation device according to the present invention, which may specifically include the following modules:
[0176] The audio recognition model training module 301 is used to train the audio recognition model according to the audio sample set, and the audio recognition model is obtained by cascading a convolutional neural network and a cyclic neural network.
[0177] The target audio feature acquisition module 302 is configured to acquire target audio features of the target user.
[0178] A target audio vector prediction module 303, configured to input the target audio feature into the audio recognition model to obtain a target audio vector.
[0179] A target object acquiring module 304, configured to acquire the target object from the candidate object list according to the target audio vector.
[0180] A target object recommending module 305, configured to recommend the tar...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com