


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A Chinese word segmentation method based on naive Bayesian algorithm
A Bayesian algorithm and Chinese word segmentation technology, which is applied in computing, computer components, special data processing applications, etc., and can solve problems such as inconsistency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
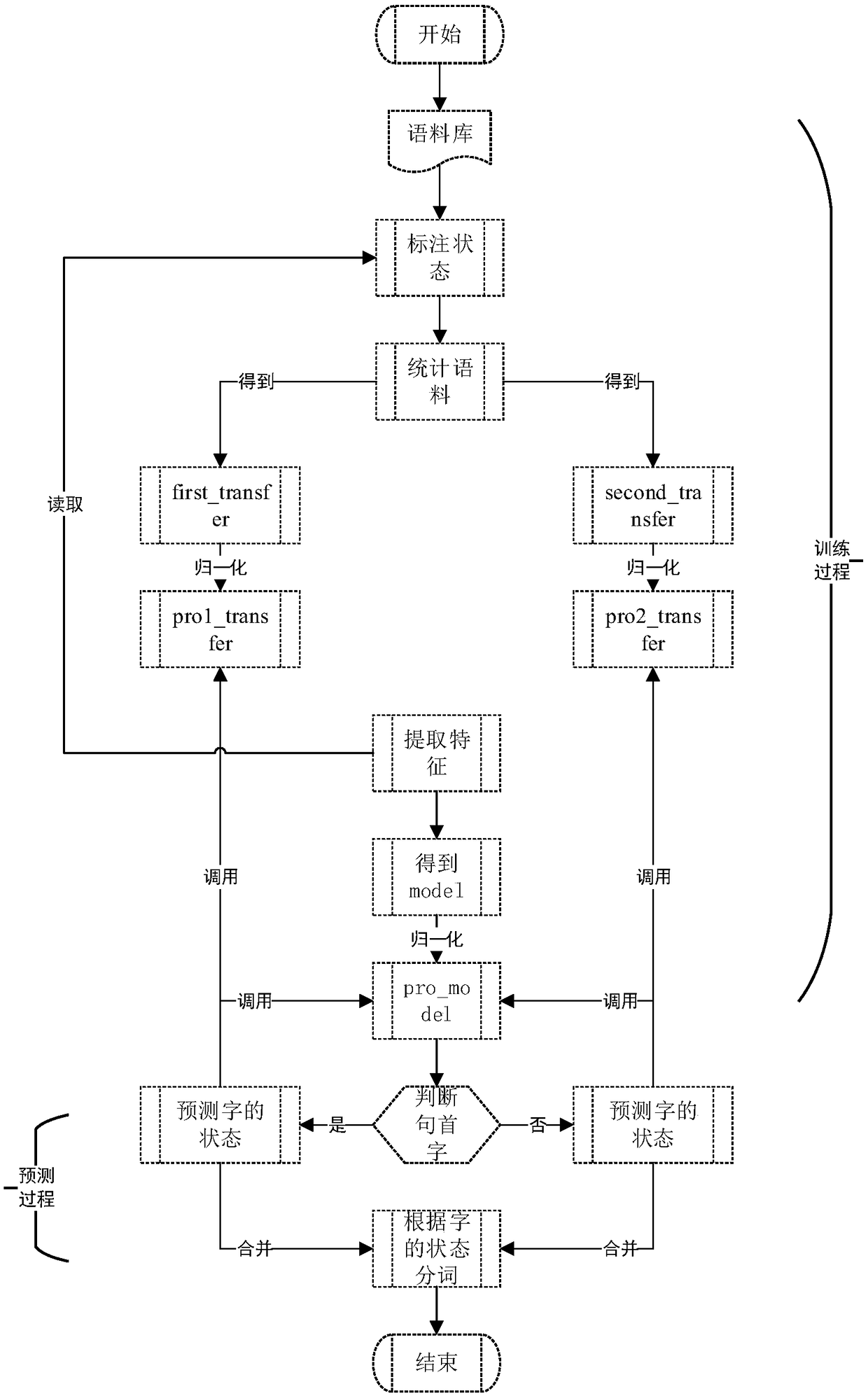
[0035] Embodiment 1: as figure 1 As shown, a Chinese word segmentation method based on the naive Bayesian algorithm, first selects the appropriate document as the corpus, and divides the corpus into sentences; then marks the corpus, not only marking the state for each word, but also Mark the part of speech; then count the marked corpus to obtain a state transition matrix, which provides the basis for the later prediction stage; then extract the features of each word from the marked corpus, in order to improve accuracy, the features of each word include The properties of the upper and lower characters; then use the feature file of each Chinese character to train a model; then use the state transition matrix and probability model to predict each Chinese character in the sentence to be segmented; finally, according to the different status of the Chinese character, the Sentence participle.
[0036] The specific steps are:
[0037] (1) Find a corpus suitable as a training set, an...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com