High-dimension data soft and hard clustering integration method based on random subspace
A random subspace, high-dimensional data technology, applied in the field of high-dimensional data soft and hard clustering integration
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

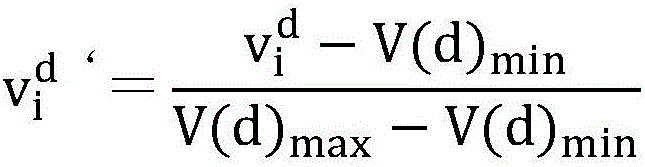
Examples
Embodiment Construction
[0119] It should be noted that, in the case of no conflict, the embodiments in the present application and the features in the embodiments can be combined with each other. The present application will be further described in detail below in conjunction with the drawings and specific embodiments.
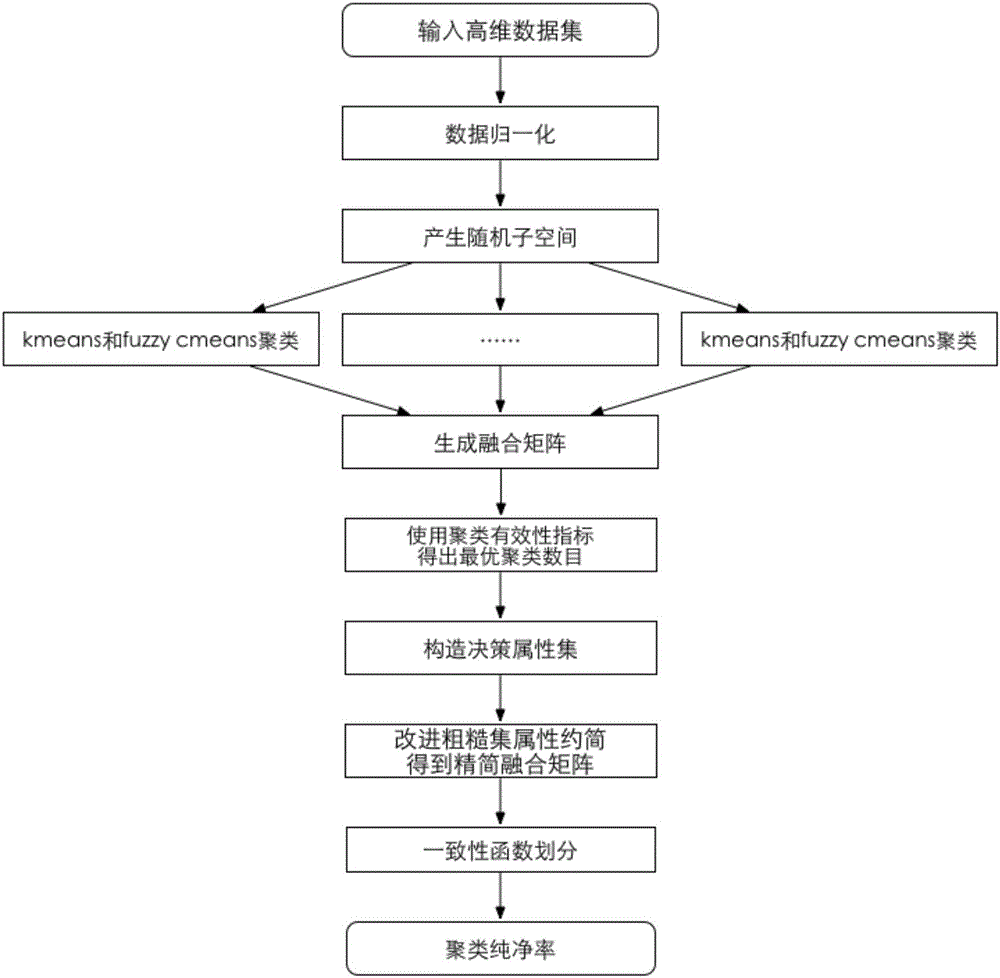
[0120] Attached below figure 1 The steps of the present invention are further described.
[0121] Step 1. Input a high-dimensional data set: input a high-dimensional data set to be clustered, the row vector corresponds to the sample dimension, and the column vector corresponds to the attribute dimension;
[0122] Step 2, data normalization: first obtain the maximum value V(d) corresponding to the attribute of the dth column max and minimum V(d) min , convert the attribute value of column d according to the following formula:
[0123]
[0124] in, It is the i-th data in the d-th column, is the updated value, i∈{1,2,...,n},d∈{1,2,...,D}, n is the number of samples, and D is t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com