Device and method for acquiring speech recognition multi-information text
A text acquisition and multi-information technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem that valuable information cannot be realized
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
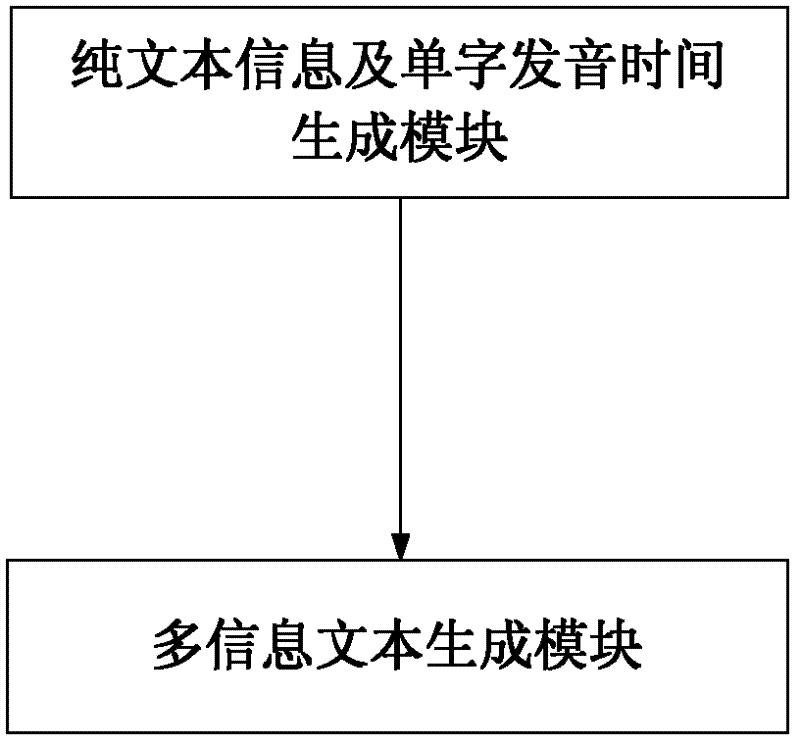
[0032] The plain text information and single-character pronunciation time generating module are used to convert the speech audio into plain text information through speech recognition, and are used to obtain the single-character pronunciation time in the speech audio, that is, the start time and end time of the single-character pronunciation, and then through the said The length of single word pronunciation time determines single word pronunciation speech rate. The pronunciation time of the single character is automatically obtained during the voice recognition process while converting the voice audio into plain text information.
[0033] The multi-information text generation module is used to integrate the information on the pronunciation and speech rate of a single character in the plain text information to generate multi-information text information.
[0034] According to the obtained single-character pronunciation and speech rate, the speech rate is expressed by changing t...
Embodiment 2
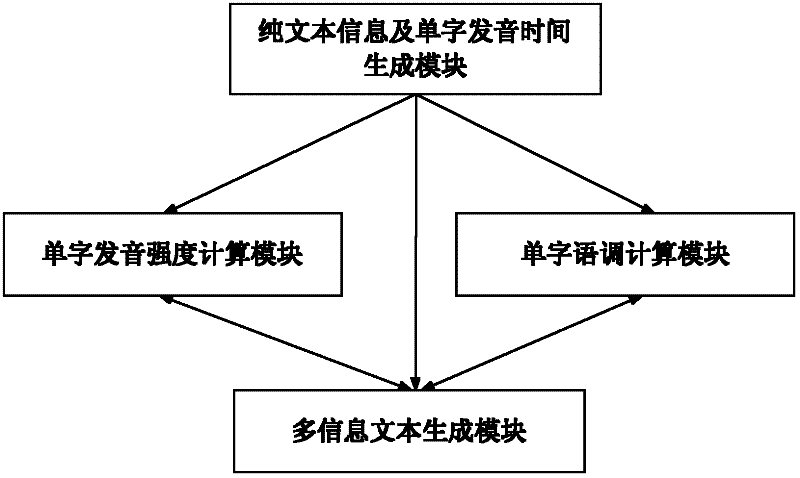
[0041] The plain text information and single-character pronunciation time generating module are used to convert the voice audio into plain text information through speech recognition, and are used to obtain the single-character pronunciation time in the voice audio, that is, the start time and end time of the single-character pronunciation, and then through the said The length of single word pronunciation time determines single word pronunciation speech rate. The pronunciation time of the single character is automatically obtained during the voice recognition process while converting the voice audio into plain text information.
[0042] The word pronunciation strength calculation module is used to calculate the word pronunciation strength according to the obtained word pronunciation time. The pronunciation strength of each character can be obtained by calculating the mean value of the pronunciation strength within the time period of the pronunciation of the single character by...
Embodiment 3
[0064] Step 1, convert the speech audio into plain text information through speech recognition, and obtain the pronunciation time of the single character in the speech audio at the same time, that is, the start time and end time of the pronunciation of the single character, and then determine the speech rate of the pronunciation of the single character through the length of the pronunciation time of the single character . The pronunciation time of the single character is automatically obtained during the voice recognition process while converting the voice audio into plain text information.
[0065] Step 2: Integrating the information on the pronunciation and speech rate of a single character in the plain text information to generate multi-information text information.
[0066] Embodiment Four
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com