


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Modeling method for enhancing expressive force of text-to-speech (TTS) system
A modeling method and technology of speech synthesis, applied in speech synthesis, speech analysis, speech recognition, etc., can solve problems such as affecting the accuracy of the fundamental frequency model
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
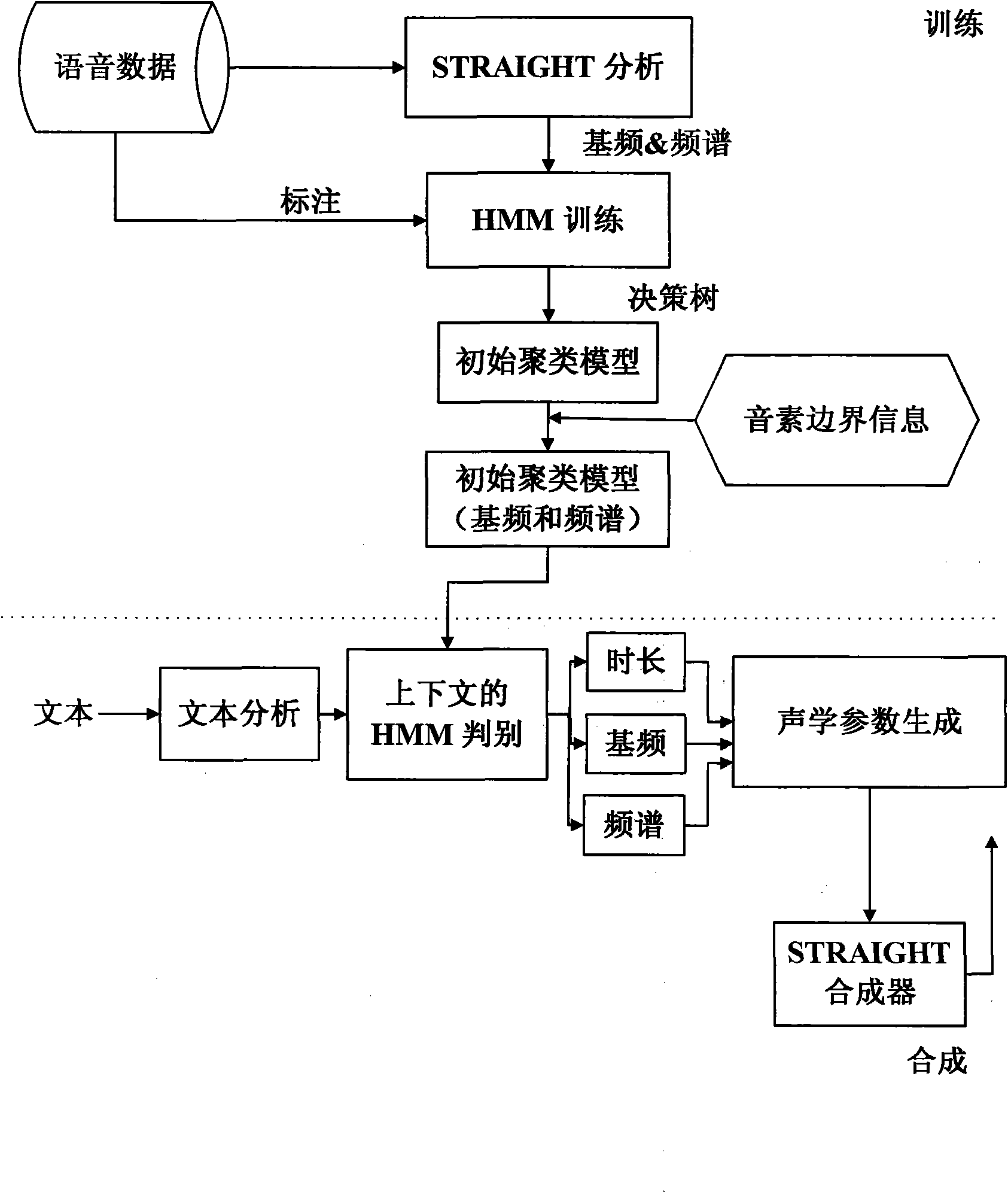
[0043] (1) Model training: In the case of ensuring that the phoneme boundaries of the fundamental frequency and spectrum are the same as the original baseline system, observe the performance of the fundamental frequency model and fundamental frequency parameter prediction through respective asynchronous modeling. In fact, this is a semi-asynchronous approach. The reason why it is not fully asynchronous is that we consider the following issues: If the fundamental frequency and spectrum are modeled without the same phoneme boundary, the phoneme boundary of the fundamental frequency will be due to Some sounds that start and end with unvoiced sounds are not divided correctly; when synthesizing, we also have a big alignment problem because the fundamental frequency and spectrum are completely asynchronous. Specific steps are as follows:
[0044] I. The training starts, and the initial steps are the same as the original synchronous modeling system until the initial clustering hidden...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com