Replicated data deleting method based on file content types
A technology of deduplication and content type, which is applied to the redundant data error detection in computing, digital data processing, special data processing applications, etc. It can solve problems such as single block strategy and inability to optimize file content type. , to achieve the effect of improving the overall performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0045] The present invention will be further described below in conjunction with the accompanying drawings.
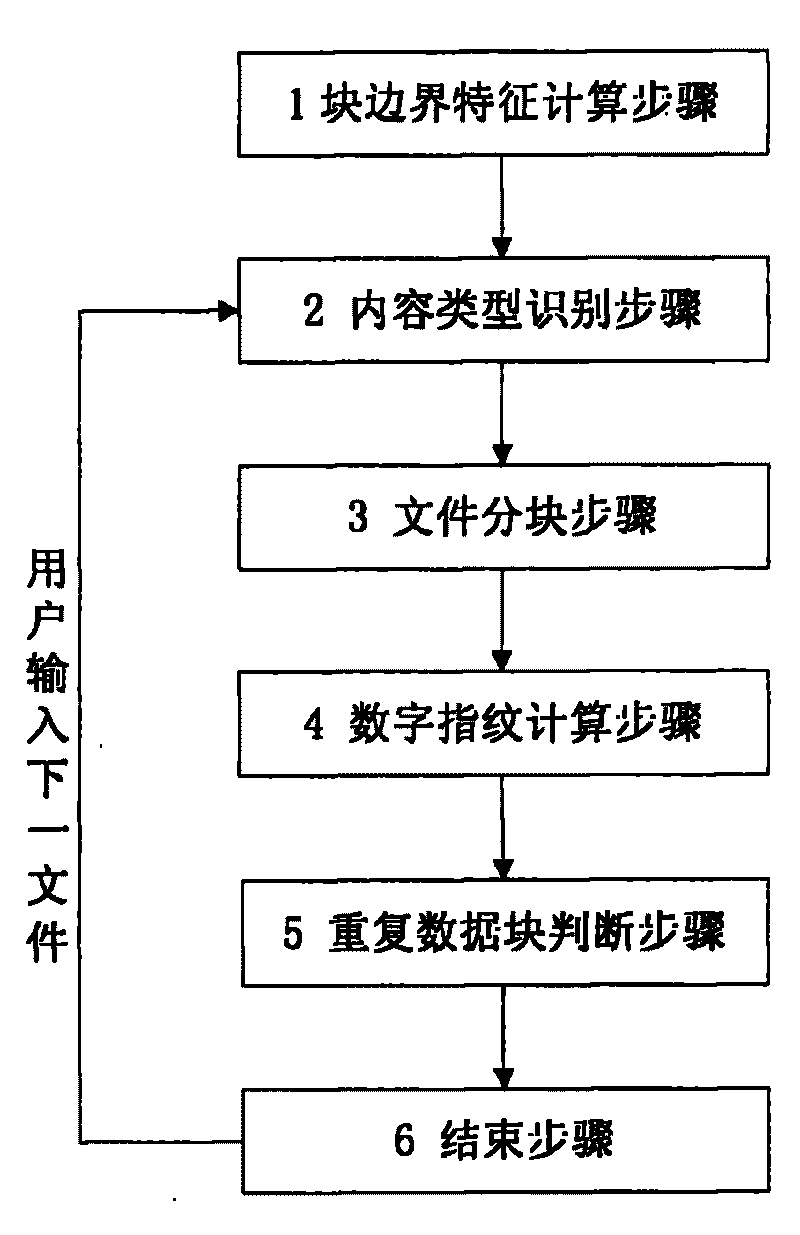
[0046] likefigure 1 As shown, the present invention performs the block boundary feature calculation step in advance, and the following sequence includes the content type identification step, the file block step, the digital fingerprint calculation step, the repeated data block judgment step and the end step.
[0047] An example of a complete flow for a content-type-based deduplication approach is given below:
[0048] Perform block boundary feature calculation steps in advance, including the following sub-steps:
[0049] A. Generate a sample file collection in the storage pool: extract the backup file collection generated by the backup process performed on September 30, 2009 from the backup system, a total of 14427 files, as a sample file collection, and put them into the storage pool;
[0050] B. Classification of sample files: Extract the metadata of each sample fil...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com